
java爬蟲系列(四)——動態網頁爬蟲升級版
我之前推薦過大家使用
seimiagent+seimicrawler,但是經過我多次試驗,在爬取任務過多,比如執行緒數超過幾十的時候,seimiagent會經常崩潰,當然這也和啟動seimiagent的伺服器有關。
鑑於seimiagent的效能不適合普通裝備的爬蟲愛好者,我重新寫了一款quick-spring+selenium的最簡爬蟲案例,供大家參考。
專案地址
專案介紹
框架
selenium
這就不用多介紹了吧,百度一搜就知道了,用來解析網頁的框架。
結構
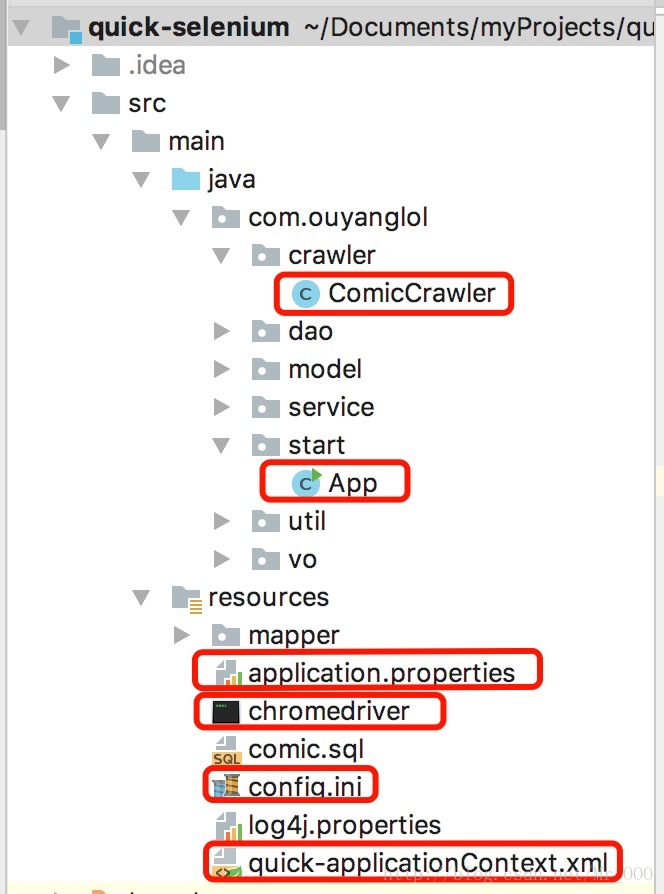
比較重要的檔案我都勾畫出來了。
ComicCrawler.java
控制每個網頁的具體爬蟲邏輯。App.java
爬蟲啟動類。application.properties
一些關鍵的配置資訊,根據你自己的配置修改就行了。config.ini
網頁驅動器的配置檔案,比如你要選擇哪一種驅動器,我這裡選中的是chromedriver,因為目前根據我的測試,它要比phantomjs穩定一點。quick-applicationContext.xml
可以自己修改一些連線池的配置。
快速啟動
修改配置檔案
根據自己的配置,修改好application.properties、config.ini、quick-applicationContext.xml的內容。
qiniu_cdn
WebDriverPool.java
找到
private static final String DEFAULT_CONFIG_FILE = "/Users/Ouyang/Documents/myProjects/quick-selenium/src/main/resources/config.ini";
修改為自己的config.ini的路徑。
App.java
package com.ouyanglol.start;
import com.ouyanglol.core.QuickBase;
import com.ouyanglol.crawler.ComicCrawler;
/**
* Package: com.ouyanglol.start
*
* @Author 修改
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/Ouyang/Documents/myProjects/chromedriver");為自己的chromedriver的路徑,如果使用phantomjs就不用了,phantomjs的配置在config.ini裡面宣告。
填寫自己的爬蟲開始路徑。
crawler.start("https://manhua.dmzj.com/yiquanchaoren/");ComicDriver.java
一定要注意使用webDriver.quit();,根據我多次的實驗,長時間啟動多個webDriver,不退出的話,也容易導致驅動器崩潰。
如果你們電腦配置過低,瀏覽器多次崩潰,不妨取消
// if (i%50==0) {
// webDriver.quit();
// webDriver = webDriverPool.get();
// }這一段的註釋,每解析50個網頁就啟動一個新的驅動器。
ComicContentService.java
qiniuUtil.uploadImg(fileName,imageUrl,chapterUrl);//把圖片儲存到七牛雲,圖片的處理方式可以自己決定
沒有七牛雲的同學,可以把這段程式碼註釋,以免報錯。
comic.sql
執行其中sql,初始化資料庫,最後啟動App.java中的main()方法就可以了。