
java爬蟲系列(五)——今日頭條文章爬蟲實戰
專案原始碼
爬蟲目標
爬取某一頭條號下面所有文章。
爬蟲設計思路
爬取方式
動態解析網頁方式爬取
之前介紹過使用webdriver的方式爬取網頁內容,這樣做的話好處非常明顯,只需要考慮如何解析網頁的element標籤就行了,當然弊端也非常明顯,就是效率不高。
解析介面方式爬取
沒遇到反爬手段逆天的網頁,我一般不推薦使用webdriver的方式,作為一名技術人員,始終要把專案效能放到第一位,所以這次的專案我選擇使用破解今日頭條介面的方式去拿取他們的文章。
解析思路
破解入口
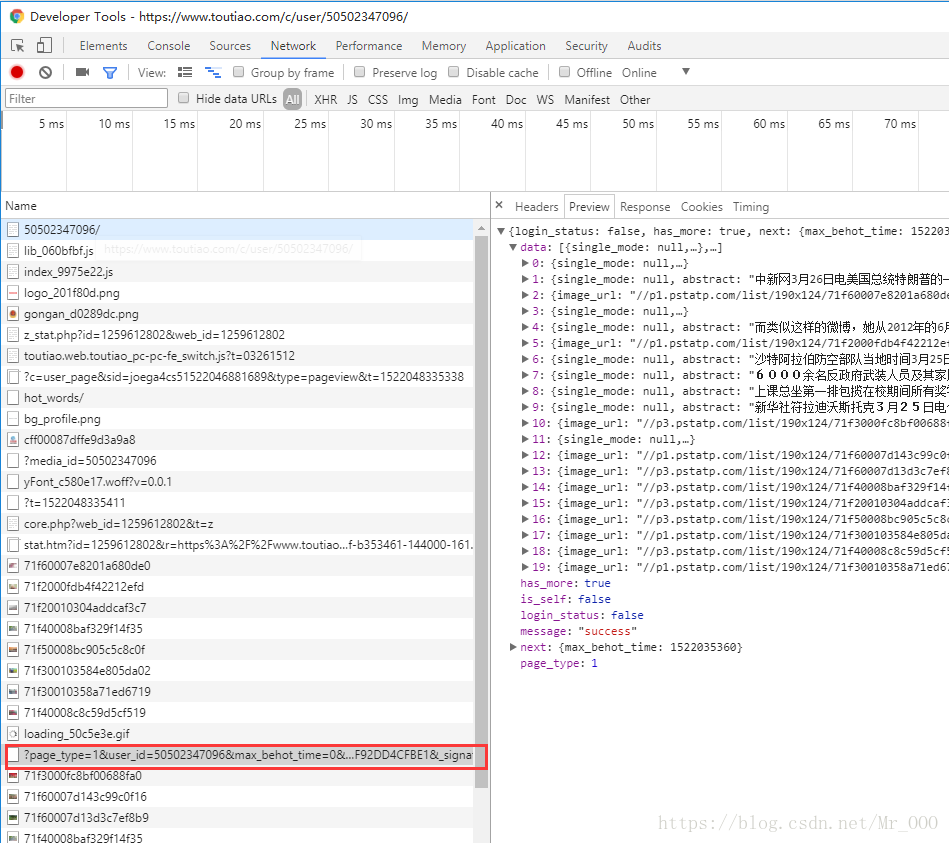
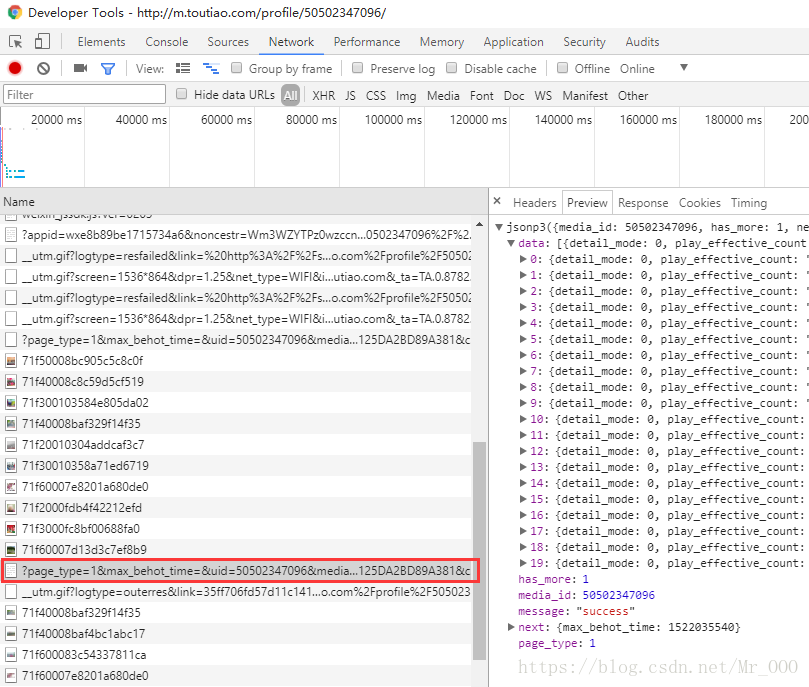
介面對比
很明顯,cp端的介面比h5的介面多一個_signature
_signature的生成方法,結果發現異常複雜,我的前端水平根本搞不定,方法是window.TAC.sign,有興趣的同學可以去試試。
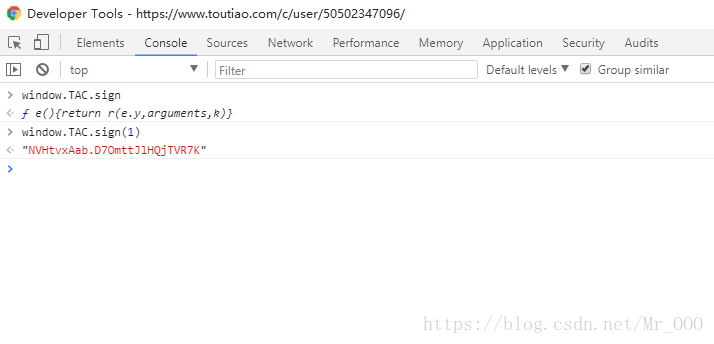
無奈只能選擇h5的介面了,現在只需要破解as和cp兩個引數就行了。
破解加密引數
引數生成方式
第一部當然是找引數怎麼生成的,很遺憾,這一步沒有捷徑,只能複製好as和cp,去每一個js檔案裡面匹配,需要一點耐心。
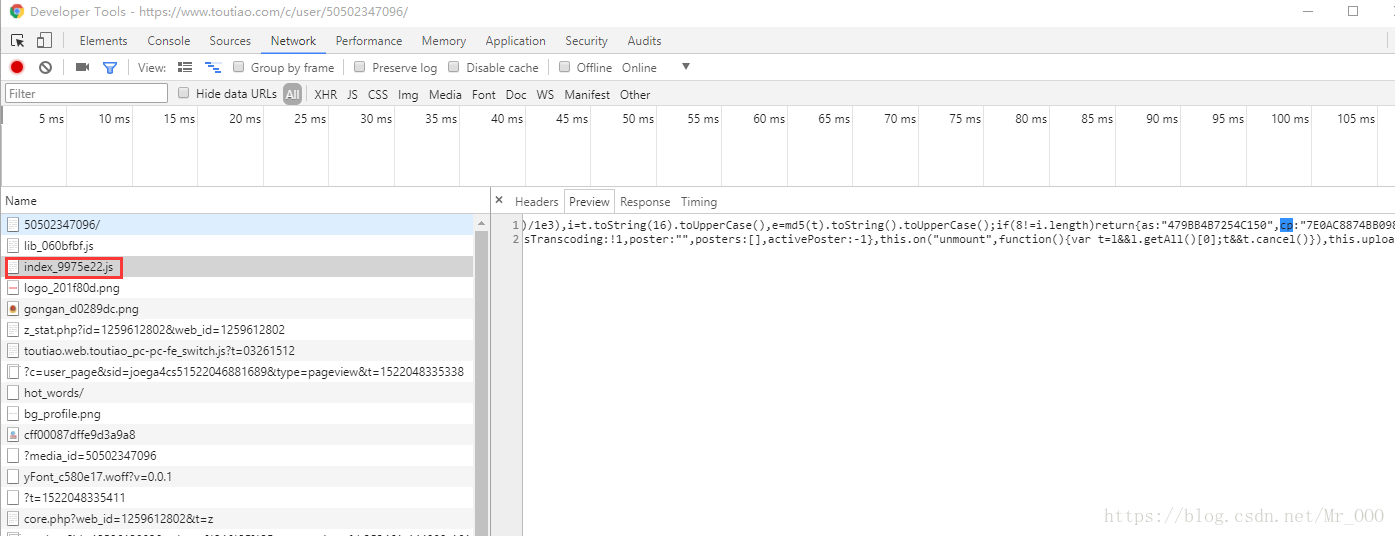
解析js
格式化該方法:
!function(t) {
var i = {};
i.getHoney = function() {
var 不算太難,一個簡單的MD5加密方式,轉成java方法也很簡單:
public static Map<String,String> getAsCp(){
String as = "479BB4B7254C150";
String cp = "7E0AC8874BB0985";
int t = (int) (new Date().getTime()/1000);
String e = Integer.toHexString(t).toUpperCase();
String i = DigestUtils.md5DigestAsHex(String.valueOf(t).getBytes()).toUpperCase();
if (e.length()==8) {
char[] n = i.substring(0,5).toCharArray();
char[] a = i.substring(i.length()-5).toCharArray();
StringBuilder s = new StringBuilder();
StringBuilder r = new StringBuilder();
for (int o = 0; o < 5; o++) {
s.append(n[o]).append(e.substring(o,o+1));
r.append(e.substring(o+3,o+4)).append(a[o]);
}
as = "A1" + s + e.substring(e.length()-3);
cp = e.substring(0,3) + r + "E1";
}
Map<String,String> map = new HashMap<>();
map.put("as",as);
map.put("cp",cp);
return map;
}分析介面返回值
media_id:該媒體ID
message:是否成功
next.max_behot_time:下一頁的請求引數
has_more:是否有下一頁
data.article_url:文章的html地址
其他引數都不重要了,這裡並沒有直接返回文章的內容,下一步就是去原文地址爬取文章內容了。
解析原文地址
基本是個靜態網頁,直接提取標籤裡面的內容就行了。
java專案解析
基本功能
為了方便,我使用spring boot框架,設計成了一個web專案,以訪問介面的方式啟動或者停止爬蟲。
佇列和執行緒池
因為是介面的方式啟動爬蟲,所以不可能等10多萬個爬蟲任務結束之後再返回成功,只能非同步執行任務,所以需要執行緒池。
光有執行緒池還不夠,幾十萬甚至更多的任務全部甩給執行緒池,顯然不是一個好的選擇。所以這裡就需要java的Queue,我選擇的是LinkedBlockingDeque,不過最後還是沒用到雙端的特性,所以使用LinkedBlockingQueue是一樣的,把所有需要爬取的任務先放入Queue佇列中,開始爬取的時候再從裡面拿去地址,這樣就可簡單的解決高併發的問題。
如果任務量特別大,而且有對詳細日誌的需求,可以選擇換成kafka。
操作介面——swagger2
使用postman傳送請求還是不太方便,還要填地址之類的,我考慮有個前端介面來操作就最好了,但是前端水平有限,不想花太多時間寫,所以選擇了整合swagger2。
開啟http://127.0.0.1:9091/swagger-ui.html#/
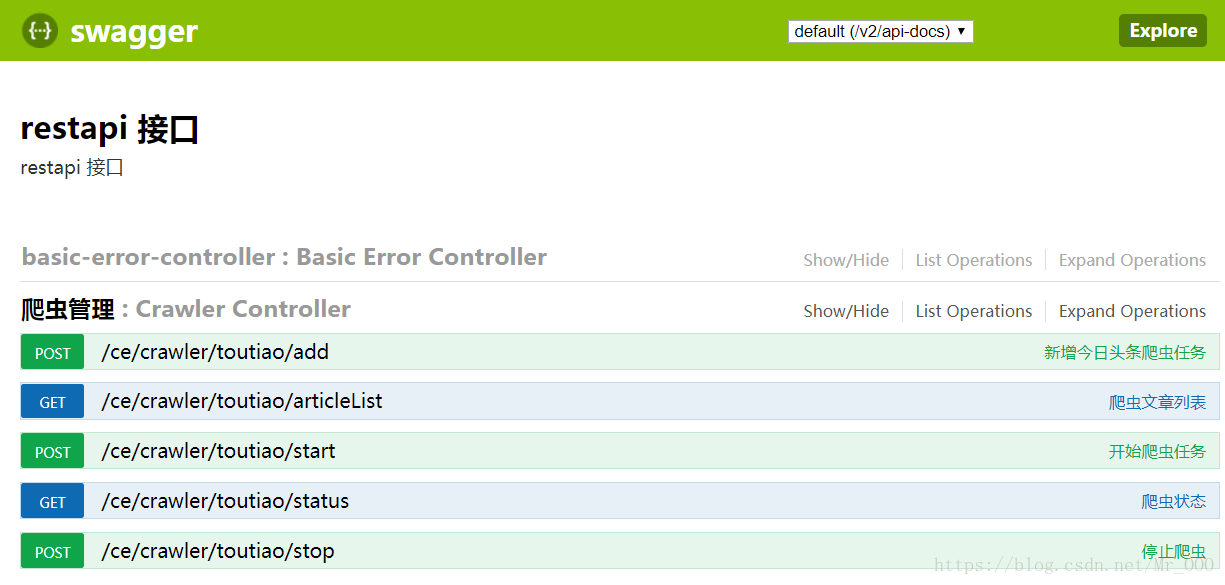
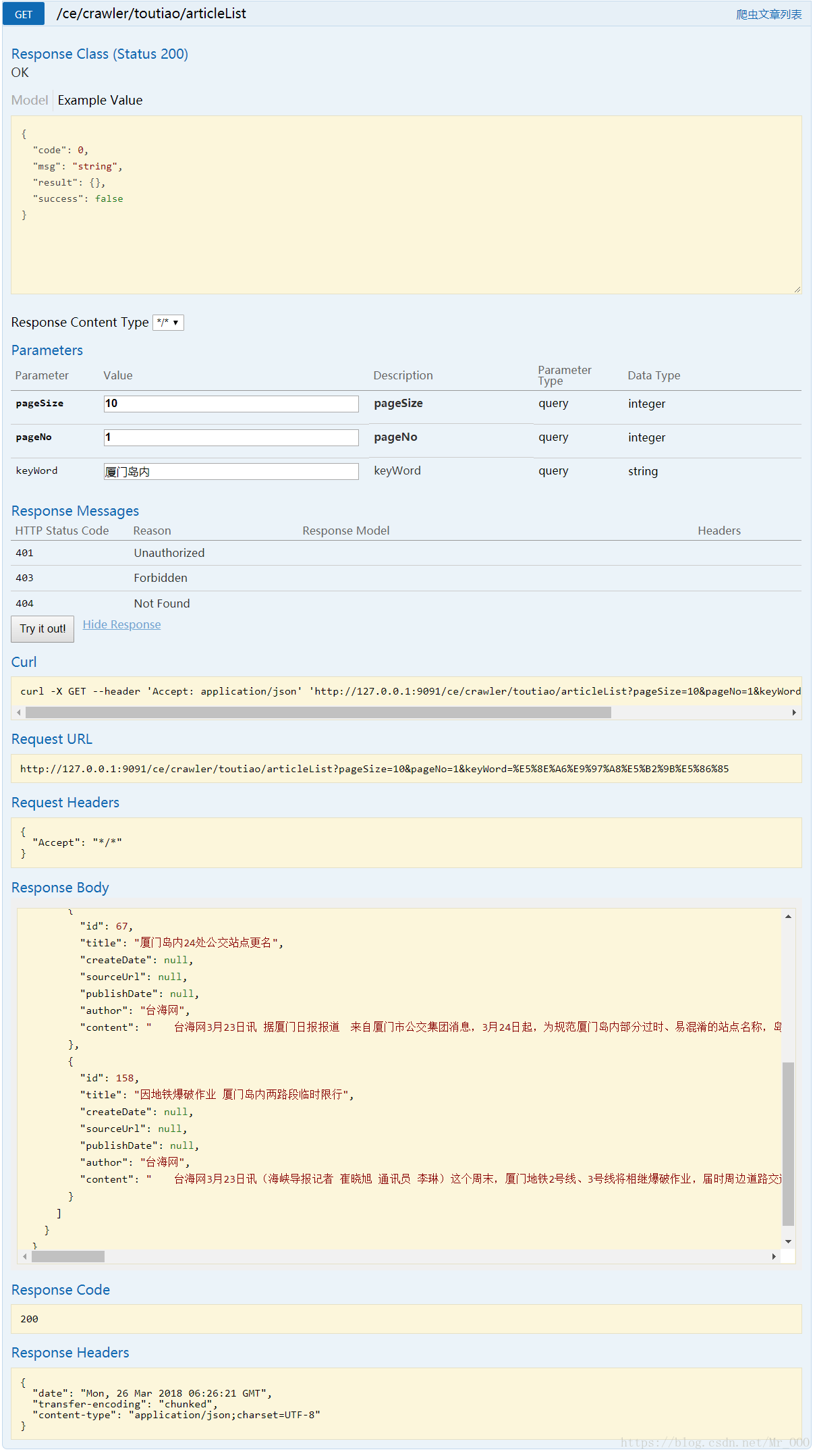
一看就知道怎麼用了,我就不多介紹了,有興趣的同學,可以根據這五個介面,寫一個前端介面,一個針對頭條號的爬蟲就算完成了。
總結
爬蟲最難的地方其實並不在程式碼上,而在於對爬取網頁的分析上,比如制定爬取方式,攻破對方的反爬手段等等,需要一些耐心和分析能力,所謂熟能生巧,最主要的還是要多嘗試,累計經驗。
補充
經網友提示發現,每個mid下的內容頁的結構方式略有不同,本文中的mid的內容頁是靜態頁面,所以使用Jsoup解析,另外有些mid,比如1558737777313793(AI財經社),它的內容頁是動態頁面,我使用的是正則匹配獲取對應資料,示例在dev1.0分支上,大家可以借鑑一下,掌握這兩種解析方式,解析其他mid都大同小異了。