
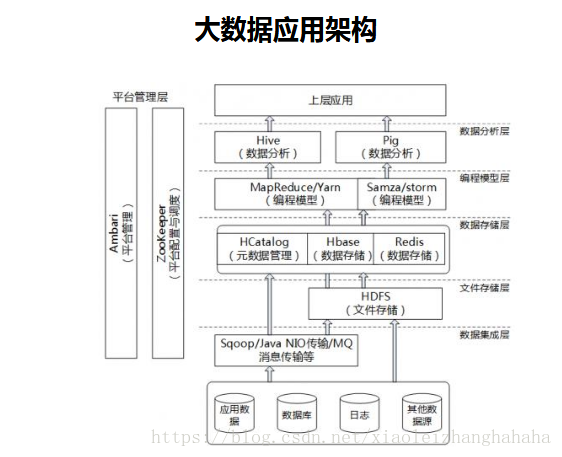
大資料應用架構
可以說,NIO中只需要一個執行緒就能完成所有接收,讀,寫等操作
要學習NIO,首先要理解它的三大核心
Selector,選擇器
Buffer,緩衝區
Channel,通道
訊息佇列(MQ)是一種應用程式對應用程式的通訊方法
訊息佇列主要解決了應用耦合、非同步處理、流量削鋒等問題。
當前使用較多的訊息佇列有RabbitMQ、RocketMQ、ActiveMQ、Kafka、ZeroMQ、MetaMq等,而部分資料庫如Redis、Mysql以及phxsql也可實現訊息佇列的功能。
HDFS Hadoop分散式檔案系統(HDFS)被設計成適合執行在通用硬體(commodity hardware)上的分散式檔案系統。
HCatalog是Hadoop的表儲存管理工具。它將Hive Metastore的表格資料暴露給其他Hadoop應用程式。它使具有不同資料處理工具(Pig,MapReduce)的使用者能夠輕鬆地將資料寫入網格。
使用方法:http://www.tutorialspoint.com/hcatalog/hcatalog_quick_guide.htm
redis 官網 https://redis.io/
MapReduce是一種程式設計模型,用於大規模資料集(大於1TB)的並行運算 分批次 hive 封裝 寫sql 語句
Apache Hadoop YARN (Yet Another Resource Negotiator,另一種資源協調者)是一種新的 Hadoop 資源管理器,它是一個通用資源管理系統,可為上層應用提供統一的資源管理和排程,它的引入為叢集在利用率、資源統一管理和資料共享等方面帶來了巨大好處。
實時流處理Storm、Spark Streaming、Samza、Flink pig 封裝 寫sql 語句