
Redis深度歷險
Redis深度歷險--核心原理與應用實踐:
Redis是網際網路技術領域應用非常廣泛的儲存中介軟體,它是remote dictionary service的簡稱,遠端字典服務。
Redis 可以做什麼?
Redis的業務應用範圍非常廣泛,讓我們以掘金技術社群(juejin.im)的帖子模組為例項,梳理一下,Redis 可以用在哪些地方?
- 記錄帖子的點贊數、評論數和點選數 (hash)。
- 記錄使用者的帖子 ID 列表 (排序),便於快速顯示使用者的帖子列表 (zset)。
- 記錄帖子的標題、摘要、作者和封面資訊,用於列表頁展示 (hash)。
- 記錄帖子的點贊使用者 ID 列表,評論 ID 列表,用於顯示和去重計數 (zset)。
- 快取近期熱帖內容 (帖子內容空間佔用比較大),減少資料庫壓力 (hash)。
- 記錄帖子的相關文章 ID,根據內容推薦相關帖子 (list)。
- 如果帖子 ID 是整數自增的,可以使用 Redis 來分配帖子 ID(計數器)。
- 收藏集和帖子之間的關係 (zset)。
- 記錄熱榜帖子 ID 列表,總熱榜和分類熱榜 (zset)。
- 快取使用者行為歷史,進行惡意行為過濾 (zset,hash)。
Redis 基礎資料結構
Redis 有 5 種基礎資料結構,分別為:string (字串)、list (列表)、set (集合)、hash (雜湊) 和 zset (有序集合)。
string (字串)
字串 string 是 Redis 最簡單的資料結構。Redis 所有的資料結構都是以唯一的 key 字串作為名稱,然後通過這個唯一 key 值來獲取相應的 value 資料。不同型別的資料結構的差異就在於 value 的結構不一樣。
Redis 的字串是動態字串,是可以修改的字串,內部結構實現上類似於 Java 的 ArrayList
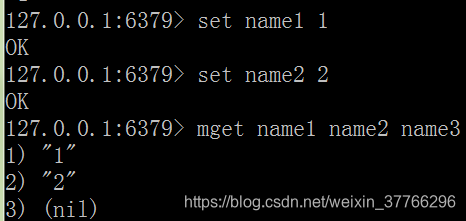
批量鍵值對:
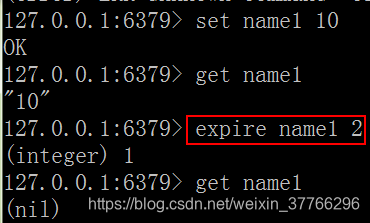
過期和set命令擴充套件:
可以對 key 設定過期時間,到點自動刪除,這個功能常用來控制快取的失效時間。
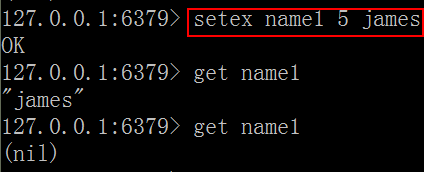
混合使用:
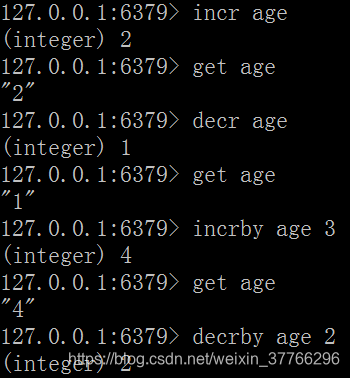
計數,增or減:
list (列表)
Redis 的列表相當於 Java 語言裡面的 LinkedList,注意它是連結串列而不是陣列。這意味著 list 的插入和刪除操作非常快,時間複雜度為 O(1)。
當列表彈出了最後一個元素之後,該資料結構自動被刪除,記憶體被回收。
右邊進左邊出:佇列
右邊進右邊出:棧

hash (字典)
Redis 的字典相當於 Java 語言裡面的 HashMap,它是無序字典。內部實現結構上同 Java 的 HashMap 也是一致的,同樣的陣列 + 連結串列二維結構。第一維 hash 的陣列位置碰撞時,就會將碰撞的元素使用連結串列串接起來。不同的是,Redis 的字典的值只能是字串,另外它們 rehash 的方式不一樣,因為 Java 的 HashMap 在字典很大時,rehash 是個耗時的操作,需要一次性全部 rehash。Redis 為了高效能,不能堵塞服務,所以採用了漸進式 rehash 策略。
有點奇怪,有時候會報錯:那是因為book這個變數已經被使用了,通過type book即可知道


set (集合)
Redis 的集合相當於 Java 語言裡面的 HashSet,它內部的鍵值對是無序的唯一的。它的內部實現相當於一個特殊的字典,字典中所有的 value 都是一個值NULL。

zset (有序集合)
zset 可能是 Redis 提供的最為特色的資料結構,它也是在面試中面試官最愛問的資料結構。它類似於 Java 的 SortedSet 和 HashMap 的結合體,一方面它是一個 set,保證了內部 value 的唯一性,另一方面它可以給每個 value 賦予一個 score,代表這個 value 的排序權重。
zset 可以用來存粉絲列表,value 值是粉絲的使用者 ID,score 是關注時間。我們可以對粉絲列表按關注時間進行排序。
zset 還可以用來儲存學生的成績,value 值是學生的 ID,score 是他的考試成績。我們可以對成績按分數進行排序就可以得到他的名次。

容器型資料結構的通用規則
list/set/hash/zset 這四種資料結構是容器型資料結構,它們共享下面兩條通用規則:
-
create if not exists
如果容器不存在,那就建立一個,再進行操作。比如 rpush 操作剛開始是沒有列表的,Redis 就會自動建立一個,然後再 rpush 進去新元素。
-
drop if no elements
如果容器裡元素沒有了,那麼立即刪除元素,釋放記憶體。這意味著 lpop 操作到最後一個元素,列表就消失了。
過期時間
Redis 所有的資料結構都可以設定過期時間,時間到了,Redis 會自動刪除相應的物件。需要注意的是過期是以物件為單位,比如一個 hash 結構的過期是整個 hash 物件的過期,而不是其中的某個子 key。
還有一個需要特別注意的地方是如果一個字串已經設定了過期時間,然後你呼叫了 set 方法修改了它,它的過期時間會消失。
127.0.0.1:6379> set codehole yoyo
OK
127.0.0.1:6379> expire codehole 600
(integer) 1
127.0.0.1:6379> ttl codehole
(integer) 597
127.0.0.1:6379> set codehole yoyo
OK
127.0.0.1:6379> ttl codehole
(integer) -1
千帆競發 —— 分散式鎖:
分散式鎖本質上要實現的目標就是在 Redis 裡面佔一個“茅坑”,當別的程序也要來佔時,發現已經有人蹲在那裡了,就只好放棄或者稍後再試。
佔坑一般是使用 setnx(set if not exists) 指令,只允許被一個客戶端佔坑。先來先佔, 用完了,再呼叫 del 指令釋放茅坑。
但是有個問題,如果邏輯執行到中間出現異常了,可能會導致 del 指令沒有被呼叫,這樣就會陷入死鎖,鎖永遠得不到釋放。
於是我們在拿到鎖之後,再給鎖加上一個過期時間,比如 5s,這樣即使中間出現異常也可以保證 5 秒之後鎖會自動釋放。
但是以上邏輯還有問題。如果在 setnx 和 expire 之間伺服器程序突然掛掉了,可能是因為機器掉電或者是被人為殺掉的,就會導致 expire 得不到執行,也會造成死鎖。
為了治理這個亂象,Redis 2.8 版本中作者加入了 set 指令的擴充套件引數,使得 setnx 和 expire 指令可以一起執行,徹底解決了分散式鎖的亂象。

上面這個指令就是 setnx 和 expire 組合在一起的原子指令,它就是分散式鎖的奧義所在。
緩兵之計 —— 延時佇列:
非同步訊息佇列
Redis 的 list(列表) 資料結構常用來作為非同步訊息佇列使用,使用rpush/lpush操作入佇列,使用lpop 和 rpop來出佇列。
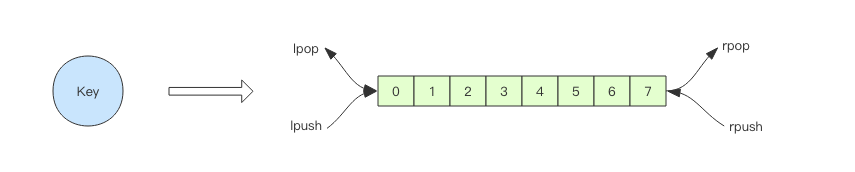
佇列空了怎麼辦?
如果佇列空了,客戶端就會陷入 pop 的死迴圈,不停地 pop,沒有資料,接著再 pop,又沒有資料。這就是浪費生命的空輪詢。
通常我們使用 sleep 來解決這個問題,讓執行緒睡一會,睡個 1s 鍾就可以了。但是會導致訊息延遲。
可以通過阻塞讀blpop/brpop:
阻塞讀在佇列沒有資料的時候,會立即進入休眠狀態,一旦資料到來,則立刻醒過來。訊息的延遲幾乎為零。用blpop/brpop替代前面的lpop/rpop,就完美解決了上面的問題。
空閒連線自動斷開
空閒連線的問題。
如果執行緒一直阻塞在哪裡,Redis 的客戶端連線就成了閒置連線,閒置過久,伺服器一般會主動斷開連線,減少閒置資源佔用。這個時候blpop/brpop會丟擲異常來。
所以編寫客戶端消費者的時候要小心,注意捕獲異常,還要重試。
鎖衝突處理
前面我們講了分散式鎖的問題,但是沒有提到客戶端在處理請求時加鎖沒加成功怎麼辦。一般有 3 種策略來處理加鎖失敗:
- 直接丟擲異常,通知使用者稍後重試;
- sleep 一會再重試;
- 將請求轉移至延時佇列,過一會再試;
直接丟擲特定型別的異常
這種方式比較適合由使用者直接發起的請求,使用者看到錯誤對話方塊後,會先閱讀對話方塊的內容,再點選重試,這樣就可以起到人工延時的效果。如果考慮到使用者體驗,可以由前端的程式碼替代使用者自己來進行延時重試控制。它本質上是對當前請求的放棄,由使用者決定是否重新發起新的請求。
sleep
sleep 會阻塞當前的訊息處理執行緒,會導致佇列的後續訊息處理出現延遲。如果碰撞的比較頻繁或者佇列裡訊息比較多,sleep 可能並不合適。如果因為個別死鎖的 key 導致加鎖不成功,執行緒會徹底堵死,導致後續訊息永遠得不到及時處理。
延時佇列
這種方式比較適合非同步訊息處理,將當前衝突的請求扔到另一個佇列延後處理以避開衝突。
延時佇列的實現
延時佇列可以通過 Redis 的 zset(有序列表) 來實現。我們將訊息序列化成一個字串作為 zset 的value,這個訊息的到期處理時間作為score,然後用多個執行緒輪詢 zset 獲取到期的任務進行處理,多個執行緒是為了保障可用性,萬一掛了一個執行緒還有其它執行緒可以繼續處理。因為有多個執行緒,所以需要考慮併發爭搶任務,確保任務不能被多次執行。
四兩撥千斤 —— HyperLogLog:
我們先思考一個常見的業務問題:如果你負責開發維護一個大型的網站,有一天老闆找產品經理要網站每個網頁每天的 UV 資料,然後讓你來開發這個統計模組,你會如何實現?
如果統計 PV 那非常好辦,給每個網頁一個獨立的 Redis 計數器就可以了,這個計數器的 key 字尾加上當天的日期。這樣來一個請求,incrby 一次,最終就可以統計出所有的 PV 資料。
但是 UV 不一樣,它要去重,同一個使用者一天之內的多次訪問請求只能計數一次。這就要求每一個網頁請求都需要帶上使用者的 ID,無論是登陸使用者還是未登陸使用者都需要一個唯一 ID 來標識。
你也許已經想到了一個簡單的方案,那就是為每一個頁面一個獨立的 set 集合來儲存所有當天訪問過此頁面的使用者 ID。當一個請求過來時,我們使用 sadd 將使用者 ID 塞進去就可以了。通過 scard 可以取出這個集合的大小,這個數字就是這個頁面的 UV 資料。沒錯,這是一個非常簡單的方案。
但是,如果你的頁面訪問量非常大,比如一個爆款頁面幾千萬的 UV,你需要一個很大的 set 集合來統計,這就非常浪費空間。如果這樣的頁面很多,那所需要的儲存空間是驚人的。為這樣一個去重功能就耗費這樣多的儲存空間,值得麼?有沒有更好的解決方案呢?
這要引入的一個解決方案,Redis 提供了 HyperLogLog 資料結構就是用來解決這種統計問題的。HyperLogLog 提供不精確的去重計數方案,雖然不精確但是也不是非常不精確,標準誤差是 0.81%,這樣的精確度已經可以滿足上面的 UV 統計需求了。
HyperLogLog 資料結構是 Redis 的高階資料結構,它非常有用,但是令人感到意外的是,使用過它的人非常少。
使用方法
HyperLogLog 提供了兩個指令 pfadd 和 pfcount,根據字面意義很好理解,一個是增加計數,一個是獲取計數。pfadd 用法和 set 集合的 sadd 是一樣的,來一個使用者 ID,就將使用者 ID 塞進去就是。pfcount 和 scard 用法是一樣的,直接獲取計數值。
層巒疊嶂 —— 布隆過濾器:
前面我們學會了使用 HyperLogLog 資料結構來進行估數,它非常有價值,可以解決很多精確度不高的統計需求。
但是如果我們想知道某一個值是不是已經在 HyperLogLog 結構裡面了,它就無能為力了,它只提供了 pfadd 和 pfcount 方法,沒有提供 pfcontains 這種方法。
講個使用場景,比如我們在使用新聞客戶端看新聞時,它會給我們不停地推薦新的內容,它每次推薦時要去重,去掉那些已經看過的內容。問題來了,新聞客戶端推薦系統如何實現推送去重的?
你會想到伺服器記錄了使用者看過的所有歷史記錄,當推薦系統推薦新聞時會從每個使用者的歷史記錄裡進行篩選,過濾掉那些已經存在的記錄。問題是當用戶量很大,每個使用者看過的新聞又很多的情況下,這種方式,推薦系統的去重工作在效能上跟的上麼?
實際上,如果歷史記錄儲存在關係資料庫裡,去重就需要頻繁地對資料庫進行 exists 查詢,當系統併發量很高時,資料庫是很難扛住壓力的。
你可能又想到了快取,但是如此多的歷史記錄全部快取起來,那得浪費多大儲存空間啊?而且這個儲存空間是隨著時間線性增長,你撐得住一個月,你能撐得住幾年麼?但是不快取的話,效能又跟不上,這該怎麼辦?
這時,布隆過濾器 (Bloom Filter) 閃亮登場了,它就是專門用來解決這種去重問題的。它在起到去重的同時,在空間上還能節省 90% 以上,只是稍微有那麼點不精確,也就是有一定的誤判概率。
布隆過濾器是什麼?
布隆過濾器可以理解為一個不怎麼精確的 set 結構,當你使用它的 contains 方法判斷某個物件是否存在時,它可能會誤判。但是布隆過濾器也不是特別不精確,只要引數設定的合理,它的精確度可以控制的相對足夠精確,只會有小小的誤判概率。
當布隆過濾器說某個值存在時,這個值可能不存在;當它說不存在時,那就肯定不存在。打個比方,當它說不認識你時,肯定就不認識;當它說見過你時,可能根本就沒見過面,不過因為你的臉跟它認識的人中某臉比較相似 (某些熟臉的係數組合),所以誤判以前見過你。
Redis 中的布隆過濾器
Redis 官方提供的布隆過濾器到了 Redis 4.0 提供了外掛功能之後才正式登場。布隆過濾器作為一個外掛載入到 Redis Server 中,給 Redis 提供了強大的布隆去重功能。
下面我們來體驗一下 Redis 4.0 的布隆過濾器,為了省去繁瑣安裝過程,我們直接用 Docker 吧。
> docker pull redislabs/rebloom # 拉取映象
> docker run -p6379:6379 redislabs/rebloom # 執行容器
> redis-cli # 連線容器中的 redis 服務
如果上面三條指令執行沒有問題,下面就可以體驗布隆過濾器了。
布隆過濾器基本使用
布隆過濾器有二個基本指令,bf.add 新增元素,bf.exists 查詢元素是否存在,它的用法和 set 集合的 sadd 和 sismember 差不多。注意 bf.add 只能一次新增一個元素,如果想要一次新增多個,就需要用到 bf.madd 指令。同樣如果需要一次查詢多個元素是否存在,就需要用到 bf.mexists 指令。
注意事項
布隆過濾器的initial_size估計的過大,會浪費儲存空間,估計的過小,就會影響準確率,使用者在使用之前一定要儘可能地精確估計好元素數量,還需要加上一定的冗餘空間以避免實際元素可能會意外高出估計值很多。
布隆過濾器的error_rate越小,需要的儲存空間就越大,對於不需要過於精確的場合,error_rate設定稍大一點也無傷大雅。比如在新聞去重上而言,誤判率高一點只會讓小部分文章不能讓合適的人看到,文章的整體閱讀量不會因為這點誤判率就帶來巨大的改變。
近水樓臺 —— GeoHash:
Redis 在 3.2 版本以後增加了地理位置 GEO 模組,意味著我們可以使用 Redis 來實現摩拜單車「附近的 Mobike」、美團和餓了麼「附近的餐館」這樣的功能了。
如果要計算「附近的人」,也就是給定一個元素的座標,然後計算這個座標附近的其它元素,按照距離進行排序,該如何下手?
如果現在元素的經緯度座標使用關係資料庫 (元素 id, 經度 x, 緯度 y) 儲存,你該如何計算?
首先,你不可能通過遍歷來計算所有的元素和目標元素的距離然後再進行排序,這個計算量太大了,效能指標肯定無法滿足。一般的方法都是通過矩形區域來限定元素的數量,然後對區域內的元素進行全量距離計算再排序。這樣可以明顯減少計算量。如何劃分矩形區域呢?可以指定一個半徑 r,使用一條 SQL 就可以圈出來。當用戶對篩出來的結果不滿意,那就擴大半徑繼續篩選。
select id from positions where x0-r < x < x0+r and y0-r < y < y0+r
為了滿足高效能的矩形區域演算法,資料表需要在經緯度座標加上雙向複合索引 (x, y),這樣可以最大優化查詢效能。
但是資料庫查詢效能畢竟有限,如果「附近的人」查詢請求非常多,在高併發場合,這可能並不是一個很好的方案。
GeoHash 演算法
業界比較通用的地理位置距離排序演算法是 GeoHash 演算法,Redis 也使用 GeoHash 演算法。GeoHash 演算法將二維的經緯度資料對映到一維的整數,這樣所有的元素都將在掛載到一條線上,距離靠近的二維座標對映到一維後的點之間距離也會很接近。當我們想要計算「附近的人時」,首先將目標位置對映到這條線上,然後在這個一維的線上獲取附近的點就行了。
那這個對映演算法具體是怎樣的呢?它將整個地球看成一個二維平面,然後劃分成了一系列正方形的方格,就好比圍棋棋盤。所有的地圖元素座標都將放置於唯一的方格中。方格越小,座標越精確。然後對這些方格進行整數編碼,越是靠近的方格編碼越是接近。那如何編碼呢?一個最簡單的方案就是切蛋糕法。設想一個正方形的蛋糕擺在你面前,二刀下去均分分成四塊小正方形,這四個小正方形可以分別標記為 00,01,10,11 四個二進位制整數。然後對每一個小正方形繼續用二刀法切割一下,這時每個小小正方形就可以使用 4bit 的二進位制整數予以表示。然後繼續切下去,正方形就會越來越小,二進位制整數也會越來越長,精確度就會越來越高。
上面的例子中使用的是二刀法,真實演算法中還會有很多其它刀法,最終編碼出來的整數數字也都不一樣。
編碼之後,每個地圖元素的座標都將變成一個整數,通過這個整數可以還原出元素的座標,整數越長,還原出來的座標值的損失程度就越小。對於「附近的人」這個功能而言,損失的一點精確度可以忽略不計。
在使用 Redis 進行 Geo 查詢時,我們要時刻想到它的內部結構實際上只是一個 zset(skiplist)。通過 zset 的 score 排序就可以得到座標附近的其它元素 (實際情況要複雜一些,不過這樣理解足夠了),通過將 score 還原成座標值就可以得到元素的原始座標。
Redis 的 Geo 指令基本使用
Redis 提供的 Geo 指令只有 6 個,使用時,讀者務必再次想起,它只是一個普通的 zset 結構。
增加
geoadd 指令攜帶集合名稱以及多個經緯度名稱三元組,注意這裡可以加入多個三元組
127.0.0.1:6379> geoadd company 116.48105 39.996794 juejin
(integer) 1
127.0.0.1:6379> geoadd company 116.514203 39.905409 ireader
(integer) 1
127.0.0.1:6379> geoadd company 116.489033 40.007669 meituan
(integer) 1
127.0.0.1:6379> geoadd company 116.562108 39.787602 jd 116.334255 40.027400 xiaomi
(integer) 2
也許你會問為什麼 Redis 沒有提供 geo 刪除指令?前面我們提到 geo 儲存結構上使用的是 zset,意味著我們可以使用 zset 相關的指令來操作 geo 資料,所以刪除指令可以直接使用 zrem 指令即可。
距離
geodist 指令可以用來計算兩個元素之間的距離,攜帶集合名稱、2 個名稱和距離單位。
127.0.0.1:6379> geodist company juejin ireader km
"10.5501"
127.0.0.1:6379> geodist company juejin meituan km
"1.3878"
127.0.0.1:6379> geodist company juejin jd km
"24.2739"
127.0.0.1:6379> geodist company juejin xiaomi km
"12.9606"
127.0.0.1:6379> geodist company juejin juejin km
"0.0000"
我們可以看到掘金離美團最近,因為它們都在望京。距離單位可以是 m、km、ml、ft,分別代表米、千米、英里和尺。
獲取元素位置
geopos 指令可以獲取集合中任意元素的經緯度座標,可以一次獲取多個。
127.0.0.1:6379> geopos company juejin
1) 1) "116.48104995489120483"
2) "39.99679348858259686"
127.0.0.1:6379> geopos company ireader
1) 1) "116.5142020583152771"
2) "39.90540918662494363"
127.0.0.1:6379> geopos company juejin ireader
1) 1) "116.48104995489120483"
2) "39.99679348858259686"
2) 1) "116.5142020583152771"
2) "39.90540918662494363"
我們觀察到獲取的經緯度座標和 geoadd 進去的座標有輕微的誤差,原因是 geohash 對二維座標進行的一維對映是有損的,通過對映再還原回來的值會出現較小的差別。對於「附近的人」這種功能來說,這點誤差根本不是事。
獲取元素的 hash 值
geohash 可以獲取元素的經緯度編碼字串,上面已經提到,它是 base32 編碼。
127.0.0.1:6379> geohash company ireader
1) "wx4g52e1ce0"
127.0.0.1:6379> geohash company juejin
1) "wx4gd94yjn0"
附近的公司
georadiusbymember 指令是最為關鍵的指令,它可以用來查詢指定元素附近的其它元素,它的引數非常複雜。
# 範圍 20 公里以內最多 3 個元素按距離正排,它不會排除自身
127.0.0.1:6379> georadiusbymember company ireader 20 km count 3 asc
1) "ireader"
2) "juejin"
3) "meituan"
# 範圍 20 公里以內最多 3 個元素按距離倒排,排除本身
127.0.0.1:6379> georadiusbymember company ireader 20 km count 3 desc
1) "jd"
2) "meituan"
3) "juejin"
# 三個可選引數 withcoord withdist withhash 用來攜帶附加引數
# withdist 很有用,它可以用來顯示距離
127.0.0.1:6379> georadiusbymember company ireader 20 km withcoord withdist withhash count 3 asc
1) 1) "ireader"
2) "0.0000"
3) (integer) 4069886008361398
4) 1) "116.5142020583152771"
2) "39.90540918662494363"
2) 1) "juejin"
2) "10.5501"
3) (integer) 4069887154388167
4) 1) "116.48104995489120483"
2) "39.99679348858259686"
3) 1) "meituan"
2) "11.5748"
3) (integer) 4069887179083478
4) 1) "116.48903220891952515"
2) "40.00766997707732031"
除了 georadiusbymember 指令根據元素查詢附近的元素,Redis 還提供了根據座標值來查詢附近的元素,這個指令更加有用,它可以根據使用者的定位來計算「附近的車」,「附近的餐館」等。它的引數和 georadiusbymember 基本一致,除了將目標元素改成經緯度座標值。
127.0.0.1:6379> georadius company 116.514202 39.905409 20 km withdist count 3 asc
1) 1) "ireader"
2) "0.0000"
2) 1) "juejin"
2) "10.5501"
3) 1) "meituan"
2) "11.5748"
小結 & 注意事項
在一個地圖應用中,車的資料、餐館的資料、人的資料可能會有百萬千萬條,如果使用 Redis 的 Geo 資料結構,它們將全部放在一個 zset 集合中。在 Redis 的叢集環境中,集合可能會從一個節點遷移到另一個節點,如果單個 key 的資料過大,會對叢集的遷移工作造成較大的影響,在叢集環境中單個 key 對應的資料量不宜超過 1M,否則會導致叢集遷移出現卡頓現象,影響線上服務的正常執行。
所以,這裡建議 Geo 的資料使用單獨的 Redis 例項部署,不使用叢集環境。
如果資料量過億甚至更大,就需要對 Geo 資料進行拆分,按國家拆分、按省拆分,按市拆分,在人口特大城市甚至可以按區拆分。這樣就可以顯著降低單個 zset 集合的大小。
大海撈針 —— Scan:
在平時線上 Redis 維護工作中,有時候需要從 Redis 例項成千上萬的 key 中找出特定字首的 key 列表來手動處理資料,可能是修改它的值,也可能是刪除 key。這裡就有一個問題,如何從海量的 key 中找出滿足特定字首的 key 列表來?
Redis 提供了一個簡單暴力的指令 keys 用來列出所有滿足特定正則字串規則的 key。
127.0.0.1:6379> set codehole1 a
OK
127.0.0.1:6379> set codehole2 b
OK
127.0.0.1:6379> set codehole3 c
OK
127.0.0.1:6379> set code1hole a
OK
127.0.0.1:6379> set code2hole b
OK
127.0.0.1:6379> set code3hole b
OK
127.0.0.1:6379> keys *
1) "codehole1"
2) "code3hole"
3) "codehole3"
4) "code2hole"
5) "codehole2"
6) "code1hole"
127.0.0.1:6379> keys codehole*
1) "codehole1"
2) "codehole3"
3) "codehole2"
127.0.0.1:6379> keys code*hole
1) "code3hole"
2) "code2hole"
3) "code1hole"
這個指令使用非常簡單,提供一個簡單的正則字串即可,但是有很明顯的兩個缺點。
- 沒有 offset、limit 引數,一次性吐出所有滿足條件的 key,萬一例項中有幾百 w 個 key 滿足條件,當你看到滿屏的字串刷的沒有盡頭時,你就知道難受了。
- keys 演算法是遍歷演算法,複雜度是 O(n),如果例項中有千萬級以上的 key,這個指令就會導致 Redis 服務卡頓,所有讀寫 Redis 的其它的指令都會被延後甚至會超時報錯,因為 Redis 是單執行緒程式,順序執行所有指令,其它指令必須等到當前的 keys 指令執行完了才可以繼續。
面對這兩個顯著的缺點該怎麼辦呢?
Redis 為了解決這個問題,它在 2.8 版本中加入了大海撈針的指令——scan。scan 相比 keys 具備有以下特點:
- 複雜度雖然也是 O(n),但是它是通過遊標分步進行的,不會阻塞執行緒;
- 提供 limit 引數,可以控制每次返回結果的最大條數,limit 只是一個 hint,返回的結果可多可少;
- 同 keys 一樣,它也提供模式匹配功能;
- 伺服器不需要為遊標儲存狀態,遊標的唯一狀態就是 scan 返回給客戶端的遊標整數;
- 返回的結果可能會有重複,需要客戶端去重複,這點非常重要;
- 遍歷的過程中如果有資料修改,改動後的資料能不能遍歷到是不確定的;
- 單次返回的結果是空的並不意味著遍歷結束,而要看返回的遊標值是否為零;
scan 基礎使用
在使用之前,讓我們往 Redis 裡插入 10000 條資料來進行測試
import redis
client = redis.StrictRedis()
for i in range(10000):
client.set("key%d" % i, i)
好,Redis 中現在有了 10000 條資料,接下來我們找出以 key99 開頭 key 列表。
scan 引數提供了三個引數,第一個是 cursor 整數值,第二個是 key 的正則模式,第三個是遍歷的 limit hint。第一次遍歷時,cursor 值為 0,然後將返回結果中第一個整數值作為下一次遍歷的 cursor。一直遍歷到返回的 cursor 值為 0 時結束。
127.0.0.1:6379> scan 0 match key99* count 1000
1) "13976"
2) 1) "key9911"
2) "key9974"
3) "key9994"
4) "key9910"
5) "key9907"
6) "key9989"
7) "key9971"
8) "key99"
9) "key9966"
10) "key992"
11) "key9903"
12) "key9905"
127.0.0.1:6379> scan 13976 match key99* count 1000
1) "1996"
2) 1) "key9982"
2) "key9997"
3) "key9963"
4) "key996"
5) "key9912"
6) "key9999"
7) "key9921"
8) "key994"
9) "key9956"
10) "key9919"
127.0.0.1:6379> scan 1996 match key99* count 1000
1) "12594"
2) 1) "key9939"
2) "key9941"
3) "key9967"
4) "key9938"
5) "key9906"
6) "key999"
7) "key9909"
8) "key9933"
9) "key9992"
......
127.0.0.1:6379> scan 11687 match key99* count 1000
1) "0"
2) 1) "key9969"
2) "key998"
3) "key9986"
4) "key9968"
5) "key9965"
6) "key9990"
7) "key9915"
8) "key9928"
9) "key9908"
10) "key9929"
11) "key9944"
從上面的過程可以看到雖然提供的 limit 是 1000,但是返回的結果只有 10 個左右。因為這個 limit 不是限定返回結果的數量,而是限定伺服器單次遍歷的字典槽位數量(約等於)。如果將 limit 設定為 10,你會發現返回結果是空的,但是遊標值不為零,意味著遍歷還沒結束。
字典的結構
在 Redis 中所有的 key 都儲存在一個很大的字典中,這個字典的結構和 Java 中的 HashMap 一樣,是一維陣列 + 二維連結串列結構,第一維陣列的大小總是 2^n(n>=0),擴容一次陣列大小空間加倍,也就是 n++。
scan 指令返回的遊標就是第一維陣列的位置索引,我們將這個位置索引稱為槽 (slot)。如果不考慮字典的擴容縮容,直接按陣列下標挨個遍歷就行了。limit 引數就表示需要遍歷的槽位數,之所以返回的結果可能多可能少,是因為不是所有的槽位上都會掛接連結串列,有些槽位可能是空的,還有些槽位上掛接的連結串列上的元素可能會有多個。每一次遍歷都會將 limit 數量的槽位上掛接的所有連結串列元素進行模式匹配過濾後,一次性返回給客戶端。
scan 遍歷順序
scan 的遍歷順序非常特別。它不是從第一維陣列的第 0 位一直遍歷到末尾,而是採用了高位進位加法來遍歷。之所以使用這樣特殊的方式進行遍歷,是考慮到字典的擴容和縮容時避免槽位的遍歷重複和遺漏。
首先我們用動畫演示一下普通加法和高位進位加法的區別。
從動畫中可以看出高位進位法從左邊加,進位往右邊移動,同普通加法正好相反。但是最終它們都會遍歷所有的槽位並且沒有重複。
字典擴容:
Java 中的 HashMap 有擴容的概念,當 loadFactor 達到閾值時,需要重新分配一個新的 2 倍大小的陣列,然後將所有的元素全部 rehash 掛到新的陣列下面。rehash 就是將元素的 hash 值對陣列長度進行取模運算,因為長度變了,所以每個元素掛接的槽位可能也發生了變化。又因為陣列的長度是 2^n 次方,所以取模運算等價於位與操作。
a mod 8 = a & (8-1) = a & 7
a mod 16 = a & (16-1) = a & 15
a mod 32 = a & (32-1) = a & 31
這裡的 7, 15, 31 稱之為字典的 mask 值,mask 的作用就是保留 hash 值的低位,高位都被設定為 0。
接下來我們看看 rehash 前後元素槽位的變化。
假設當前的字典的陣列長度由 8 位擴容到 16 位,那麼 3 號槽位 011 將會被 rehash 到 3 號槽位和 11 號槽位,也就是說該槽位連結串列中大約有一半的元素還是 3 號槽位,其它的元素會放到 11 號槽位,11 這個數字的二進位制是 1011,就是對 3 的二進位制 011 增加了一個高位 1。
抽象一點說,假設開始槽位的二進位制數是 xxx,那麼該槽位中的元素將被 rehash 到 0xxx 和 1xxx(xxx+8) 中。 如果字典長度由 16 位擴容到 32 位,那麼對於二進位制槽位 xxxx 中的元素將被 rehash 到 0xxxx 和 1xxxx(xxxx+16) 中。
對比擴容縮容前後的遍歷順序
觀察這張圖,我們發現採用高位進位加法的遍歷順序,rehash 後的槽位在遍歷順序上是相鄰的。
假設當前要即將遍歷 110 這個位置 (橙色),那麼擴容後,當前槽位上所有的元素對應的新槽位是 0110 和 1110(深綠色),也就是在槽位的二進位制數增加一個高位 0 或 1。這時我們可以直接從 0110 這個槽位開始往後繼續遍歷,0110 槽位之前的所有槽位都是已經遍歷過的,這樣就可以避免擴容後對已經遍歷過的槽位進行重複遍歷。
再考慮縮容,假設當前即將遍歷 110 這個位置 (橙色),那麼縮容後,當前槽位所有的元素對應的新槽位是 10(深綠色),也就是去掉槽位二進位制最高位。這時我們可以直接從 10 這個槽位繼續往後遍歷,10 槽位之前的所有槽位都是已經遍歷過的,這樣就可以避免縮容的重複遍歷。不過縮容還是不太一樣,它會對圖中 010 這個槽位上的元素進行重複遍歷,因為縮融後 10 槽位的元素是 010 和 110 上掛接的元素的融合。
漸進式 rehash:
Java 的 HashMap 在擴容時會一次性將舊陣列下掛接的元素全部轉移到新陣列下面。如果 HashMap 中元素特別多,執行緒就會出現卡頓現象。Redis 為了解決這個問題,它採用漸進式 rehash。
它會同時保留舊陣列和新陣列,然後在定時任務中以及後續對 hash 的指令操作中漸漸地將舊陣列中掛接的元素遷移到新陣列上。這意味著要操作處於 rehash 中的字典,需要同時訪問新舊兩個陣列結構。如果在舊陣列下面找不到元素,還需要去新陣列下面去尋找。
scan 也需要考慮這個問題,對與 rehash 中的字典,它需要同時掃描新舊槽位,然後將結果融合後返回給客戶端。
更多的 scan 指令
scan 指令是一系列指令,除了可以遍歷所有的 key 之外,還可以對指定的容器集合進行遍歷。比如 zscan 遍歷 zset 集合元素,hscan 遍歷 hash 字典的元素、sscan 遍歷 set 集合的元素。
它們的原理同 scan 都會類似的,因為 hash 底層就是字典,set 也是一個特殊的 hash(所有的 value 指向同一個元素),zset 內部也使用了字典來儲存所有的元素內容。
大 key 掃描
有時候會因為業務人員使用不當,在 Redis 例項中會形成很大的物件,比如一個很大的 hash,一個很大的 zset 這都是經常出現的。這樣的物件對 Redis 的叢集資料遷移帶來了很大的問題,因為在叢集環境下,如果某個 key 太大,會資料導致遷移卡頓。另外在記憶體分配上,如果一個 key 太大,那麼當它需要擴容時,會一次性申請更大的一塊記憶體,這也會導致卡頓。如果這個大 key 被刪除,記憶體會一次性回收,卡頓現象會再一次產生。
在平時的業務開發中,要儘量避免大 key 的產生。
如果你觀察到 Redis 的記憶體大起大落,這極有可能是因為大 key 導致的,這時候你就需要定位出具體是那個 key,進一步定位出具體的業務來源,然後再改進相關業務程式碼設計。
那如何定位大 key 呢?
為了避免對線上 Redis 帶來卡頓,這就要用到 scan 指令,對於掃描出來的每一個 key,使用 type 指令獲得 key 的型別,然後使用相應資料結構的 size 或者 len 方法來得到它的大小,對於每一種型別,保留大小的前 N 名作為掃描結果展示出來。
上面這樣的過程需要編寫指令碼,比較繁瑣,不過 Redis 官方已經在 redis-cli 指令中提供了這樣的掃描功能,我們可以直接拿來即用。
redis-cli -h 127.0.0.1 -p 7001 –-bigkeys
如果你擔心這個指令會大幅擡升 Redis 的 ops 導致線上報警,還可以增加一個休眠引數。
redis-cli -h 127.0.0.1 -p 7001 –-bigkeys -i 0.1
上面這個指令每隔 100 條 scan 指令就會休眠 0.1s,ops 就不會劇烈擡升,但是掃描的時間會變長。
鞭辟入裡 —— 執行緒 IO 模型:
Redis 是個單執行緒程式!這點必須銘記。
也許你會懷疑高併發的 Redis 中介軟體怎麼可能是單執行緒。很抱歉,它就是單執行緒,你的懷疑暴露了你基礎知識的不足。莫要瞧不起單執行緒,除了 Redis 之外,Node.js 也是單執行緒,Nginx 也是單執行緒,但是它們都是伺服器高效能的典範。
Redis 單執行緒為什麼還能這麼快?
因為它所有的資料都在記憶體中,所有的運算都是記憶體級別的運算。正因為 Redis 是單執行緒,所以要小心使用 Redis 指令,對於那些時間複雜度為 O(n) 級別的指令,一定要謹慎使用,一不小心就可能會導致 Redis 卡頓。
非阻塞 IO
當我們呼叫套接字的讀寫方法,預設它們是阻塞的,比如read方法要傳遞進去一個引數n,表示最多讀取這麼多位元組後再返回,如果一個位元組都沒有,那麼執行緒就會卡在那裡,直到新的資料到來或者連線關閉了,read方法才可以返回,執行緒才能繼續處理。而write方法一般來說不會阻塞,除非核心為套接字分配的寫緩衝區已經滿了,write方法就會阻塞,直到快取區中有空閒空間挪出來了。
非阻塞 IO 在套接字物件上提供了一個選項Non_Blocking,當這個選項開啟時,讀寫方法不會阻塞,而是能讀多少讀多少,能寫多少寫多少。能讀多少取決於核心為套接字分配的讀緩衝區內部的資料位元組數,能寫多少取決於核心為套接字分配的寫緩衝區的空閒空間位元組數。讀方法和寫方法都會通過返回值來告知程式實際讀寫了多少位元組。
有了非阻塞 IO 意味著執行緒在讀寫 IO 時可以不必再阻塞了,讀寫可以瞬間完成然後執行緒可以繼續幹別的事了。
事件輪詢 (多路複用)
非阻塞 IO 有個問題,那就是執行緒要讀資料,結果讀了一部分就返回了,執行緒如何知道何時才應該繼續讀。也就是當資料到來時,執行緒如何得到通知。寫也是一樣,如果緩衝區滿了,寫不完,剩下的資料何時才應該繼續寫,執行緒也應該得到通知。
事件輪詢 API 就是用來解決這個問題的,最簡單的事件輪詢 API 是select函式,它是作業系統提供給使用者程式的 API。輸入是讀寫描述符列表read_fds & write_fds,輸出是與之對應的可讀可寫事件。同時還提供了一個timeout引數,如果沒有任何事件到來,那麼就最多等待timeout時間,執行緒處於阻塞狀態。一旦期間有任何事件到來,就可以立即返回。時間過了之後還是沒有任何事件到來,也會立即返回。拿到事件後,執行緒就可以繼續挨個處理相應的事件。處理完了繼續過來輪詢。於是執行緒就進入了一個死迴圈,我們把這個死迴圈稱為事件迴圈,一個迴圈為一個週期。
每個客戶端套接字socket都有對應的讀寫檔案描述符。
read_events, write_events = select(read_fds, write_fds, timeout)
for event in read_events:
handle_read(event.fd)
for event in write_events:
handle_write(event.fd)
handle_others() # 處理其它事情,如定時任務等
因為我們通過select系統呼叫同時處理多個通道描述符的讀寫事件,因此我們將這類系統呼叫稱為多路複用 API。現代作業系統的多路複用 API 已經不再使用select系統呼叫,而改用epoll(linux)和kqueue(freebsd & macosx),因為 select 系統呼叫的效能在描述符特別多時效能會非常差。它們使用起來可能在形式上略有差異,但是本質上都是差不多的,都可以使用上面的虛擬碼邏輯進行理解。
伺服器套接字serversocket物件的讀操作是指呼叫accept接受客戶端新連線。何時有新連線到來,也是通過select系統呼叫的讀事件來得到通知的。
事件輪詢 API 就是 Java 語言裡面的 NIO 技術
Java 的 NIO 並不是 Java 特有的技術,其它計算機語言都有這個技術,只不過換了一個詞彙,不叫 NIO 而已。
指令佇列
Redis 會將每個客戶端套接字都關聯一個指令佇列。客戶端的指令通過佇列來排隊進行順序處理,先到先服務。
響應佇列
Redis 同樣也會為每個客戶端套接字關聯一個響應佇列。Redis 伺服器通過響應佇列來將指令的返回結果回覆給客戶端。 如果佇列為空,那麼意味著連線暫時處於空閒狀態,不需要去獲取寫事件,也就是可以將當前的客戶端描述符從write_fds裡面移出來。等到佇列有資料了,再將描述符放進去。避免select系統呼叫立即返回寫事件,結果發現沒什麼資料可以寫。出這種情況的執行緒會飆高 CPU。
定時任務??
伺服器處理要響應 IO 事件外,還要處理其它事情。比如定時任務就是非常重要的一件事。如果執行緒阻塞在 select 系統呼叫上,定時任務將無法得到準時排程。那 Redis 是如何解決這個問題的呢?
Redis 的定時任務會記錄在一個稱為最小堆的資料結構中。這個堆中,最快要執行的任務排在堆的最上方。在每個迴圈週期,Redis 都會將最小堆裡面已經到點的任務立即進行處理。處理完畢後,將最快要執行的任務還需要的時間記錄下來,這個時間就是select系統呼叫的timeout引數。因為 Redis 知道未來timeout時間內,沒有其它定時任務需要處理,所以可以安心睡眠timeout的時間。
Nginx 和 Node 的事件處理原理和 Redis 也是類似的
交頭接耳 —— 通訊協議:
Redis 的作者認為資料庫系統的瓶頸一般不在於網路流量,而是資料庫自身內部邏輯處理上。所以即使 Redis 使用了浪費流量的文字協議,依然可以取得極高的訪問效能。Redis 將所有資料都放在記憶體,用一個單執行緒對外提供服務,單個節點在跑滿一個 CPU 核心的情況下可以達到了 10w/s 的超高 QPS。
RESP(Redis Serialization Protocol)
RESP 是 Redis 序列化協議的簡寫。它是一種直觀的文字協議,優勢在於實現異常簡單,解析效能極好。
Redis 協議將傳輸的結構資料分為 5 種最小單元型別,單元結束時統一加上回車換行符號\r\n。
- 單行字串 以
+符號開頭。 - 多行字串 以
$符號開頭,後跟字串長度。 - 整數值 以
:符號開頭,後跟整數的字串形式。 - 錯誤訊息 以
-符號開頭。 - 陣列 以
*號開頭,後跟陣列的長度。
單行字串 hello world
+hello world\r\n
多行字串 hello world
$11\r\nhello world\r\n
多行字串當然也可以表示單行字串。
整數 1024
:1024\r\n
錯誤 引數型別錯誤
-WRONGTYPE Operation against a key holding the wrong kind of value\r\n
陣列 [1,2,3]
*3\r\n:1\r\n:2\r\n:3\r\n
NULL 用多行字串表示,不過長度要寫成-1。
$-1\r\n
空串 用多行字串表示,長度填 0。
$0\r\n\r\n
注意這裡有兩個\r\n。為什麼是兩個?因為兩個\r\n之間,隔的是空串。
客戶端 -> 伺服器
客戶端向伺服器傳送的指令只有一種格式,多行字串陣列。比如一個簡單的 set 指令set author codehole會被序列化成下面的字串。
*3\r\n$3\r\nset\r\n$6\r\nauthor\r\n$8\r\ncodehole\r\n
在控制檯輸出這個字串如下,可以看出這是很好閱讀的一種格式。
*3
$3
set
$6
author
$8
codehole
伺服器 -> 客戶端
伺服器向客戶端回覆的響應要支援多種資料結構,所以訊息響應在結構上要複雜不少。不過再複雜的響應訊息也是以上 5 中基本型別的組合。
單行字串響應
127.0.0.1:6379> set author codehole
OK
這裡的 OK 就是單行響應,沒有使用引號括起來。
+OK
錯誤響應
127.0.0.1:6379> incr author
(error) ERR value is not an integer or out of range
試圖對一個字串進行自增,伺服器丟擲一個通用的錯誤。
-ERR value is not an integer or out of range
整數響應
127.0.0.1:6379> incr books
(integer) 1
這裡的1就是整數響應
:1
多行字串響應
127.0.0.1:6379> get author
"codehole"
這裡使用雙引號括起來的字串就是多行字串響應
$8
codehole
陣列響應
127.0.0.1:6379> hset info name laoqian
(integer) 1
127.0.0.1:6379> hset info age 30
(integer) 1
127.0.0.1:6379> hset info sex male
(integer) 1
127.0.0.1:6379> hgetall info
1) "name"
2) "laoqian"
3) "age"
4) "30"
5) "sex"
6) "male"
這裡的 hgetall 命令返回的就是一個數組,第 0|2|4 位置的字串是 hash 表的 key,第 1|3|5 位置的字串是 value,客戶端負責將陣列組裝成字典再返回。
*6
$4
name
$6
laoqian
$3
age
$2
30
$3
sex
$4
male
巢狀
127.0.0.1:6379> scan 0
1) "0"
2) 1) "info"
2) "books"
3) "author"
scan 命令用來掃描伺服器包含的所有 key 列表,它是以遊標的形式獲取,一次只獲取一部分。
scan 命令返回的是一個巢狀陣列。陣列的第一個值表示遊標的值,如果這個值為零,說明已經遍歷完畢。如果不為零,使用這個值作為 scan 命令的引數進行下一次遍歷。陣列的第二個值又是一個數組,這個陣列就是 key 列表。
*2
$1
0
*3
$4
info
$5
books
$6
author
小結
Redis 協議裡有大量冗餘的回車換行符,但是這不影響它成為網際網路技術領域非常受歡迎的一個文字協議。有很多開源專案使用 RESP 作為它的通訊協議。在技術領域效能並不總是一切,還有簡單性、易理解性和易實現性,這些都需要進行適當權衡。
未雨綢繆 —— 持久化:
Redis 的資料全部在記憶體裡,如果突然宕機,資料就會全部丟失,因此必須有一種機制來保證 Redis 的資料不會因為故障而丟失,這種機制就是 Redis 的持久化機制。
Redis 的持久化機制有兩種,第一種是快照,第二種是 AOF 日誌。快照是一次全量備份,AOF 日誌是連續的增量備份。快照是記憶體資料的二進位制序列化形式,在儲存上非常緊湊,而 AOF 日誌記錄的是記憶體資料修改的指令記錄文字。AOF 日誌在長期的執行過程中會變的無比龐大,資料庫重啟時需要載入 AOF 日誌進行指令重放,這個時間就會無比漫長。所以需要定期進行 AOF 重寫,給 AOF 日誌進行瘦身。
快照原理
我們知道 Redis 是單執行緒程式,這個執行緒要同時負責多個客戶端套接字的併發讀寫操作和記憶體資料結構的邏輯讀寫。
在服務線上請求的同時,Redis 還需要進行記憶體快照,記憶體快照要求 Redis 必須進行檔案 IO 操作,可檔案 IO 操作是不能使用多路複用 API。
這意味著單執行緒同時在服務線上的請求還要進行檔案 IO 操作,檔案 IO 操作會嚴重拖垮伺服器請求的效能。還有個重要的問題是為了不阻塞線上的業務,就需要邊持久化邊響應客戶端請求。持久化的同時,記憶體資料結構還在改變,比如一個大型的 hash 字典正在持久化,結果一個請求過來把它給刪掉了,還沒持久化完呢,這尼瑪要怎麼搞?
那該怎麼辦呢?
Redis 使用作業系統的多程序 COW(Copy On Write) 機制來實現快照持久化,這個機制很有意思,也很少人知道。多程序 COW 也是鑑定程式設計師知識廣度的一個重要指標。
fork(多程序)
Redis 在持久化時會呼叫 glibc 的函式fork產生一個子程序,快照持久化完全交給子程序來處理,父程序繼續處理客戶端請求。子程序剛剛產生時,它和父程序共享記憶體裡面的程式碼段和資料段。這時你可以將父子程序想像成一個連體嬰兒,共享身體。這是 Linux 作業系統的機制,為了節約記憶體資源,所以儘可能讓它們共享起來。在程序分離的一瞬間,記憶體的增長几乎沒有明顯變化。
用 Python 語言描述程序分離的邏輯如下。fork函式會在父子程序同時返回,在父程序裡返回子程序的 pid,在子程序裡返回零。如果作業系統記憶體資源不足,pid 就會是負數,表示fork失敗。
pid = os.fork()
if pid > 0:
handle_client_requests() # 父程序繼續處理客戶端請求
if pid == 0:
handle_snapshot_write() # 子程序處理快照寫磁碟
if pid < 0:
# fork error
子程序做資料持久化,它不會修改現有的記憶體資料結構,它只是對資料結構進行遍歷讀取,然後序列化寫到磁碟中。但是父程序不一樣,它必須持續服務客戶端請求,然後對記憶體資料結構進行不間斷的修改。
重點::這個時候就會使用作業系統的 COW 機制來進行資料段頁面的分離。資料段是由很多作業系統的頁面組合而成,當父程序對其中一個頁面的資料進行修改時,會將被共享的頁面複製一份分離出來,然後對這個複製的頁面進行修改。這時子程序相應的頁面是沒有變化的,還是程序產生時那一瞬間的資料。
隨著父程序修改操作的持續進行,越來越多的共享頁面被分離出來,記憶體就會持續增長。但是也不會超過原有資料記憶體的 2 倍大小。另外一個 Redis 例項裡冷資料佔的比例往往是比較高的,所以很少會出現所有的頁面都會被分離,被分離的往往只有其中一部分頁面。每個頁面的大小隻有 4K,一個 Redis 例項裡面一般都會有成千上萬的頁面。
子程序因為資料沒有變化,它能看到的記憶體裡的資料在程序產生的一瞬間就凝固了,再也不會改變,這也是為什麼 Redis 的持久化叫「快照」的原因。接下來子程序就可以非常安心的遍歷資料了進行序列化寫磁碟了。
AOF 原理
AOF 日誌儲存的是 Redis 伺服器的順序指令序列,AOF 日誌只記錄對記憶體進行修改的指令記錄。
假設 AOF 日誌記錄了自 R