
常用連續型分佈介紹及R語言實現
R的極客理想系列文章,涵蓋了R的思想,使用,工具,創新等的一系列要點,以我個人的學習和體驗去詮釋R的強大。
R語言作為統計學一門語言,一直在小眾領域閃耀著光芒。直到大資料的爆發,R語言變成了一門炙手可熱的資料分析的利器。隨著越來越多的工程背景的人的加入,R語言的社群在迅速擴大成長。現在已不僅僅是統計領域,教育,銀行,電商,網際網路….都在使用R語言。
要成為有理想的極客,我們不能停留在語法上,要掌握牢固的數學,概率,統計知識,同時還要有創新精神,把R語言發揮到各個領域。讓我們一起動起來吧,開始R的極客理想。
關於作者:
- 張丹(Conan), 程式設計師Java,R,PHP,Javascript
- weibo:@Conan_Z
- email: [email protected]

前言
隨機變數在我們的生活中處處可見,如每日天氣,股價漲跌,彩票中獎等,這些事情都是事前不可預言其結果的,就算在相同的條件下重複進行試驗,其結果未必相同。數學家們總結了這種規律,用概率分佈來描述隨機變數取值。
就算股價不能預測,但如果我們知道它的概率分佈,那麼有90%的可能我們可以猜出答案。
目錄
- 正態分佈
- 指數分步
- γ(伽瑪)分佈
- weibull分佈
- F分佈
- T分佈
- β(貝塔)分佈
- χ²(卡方)分佈
- 均勻分佈
1. 正態分佈
正態分佈(Normal distribution)又名高斯分佈(Gaussian distribution),是一個在數學、物理及工程等領域都非常重要的概率分佈,在統計學的許多方面有著重大的影響力。
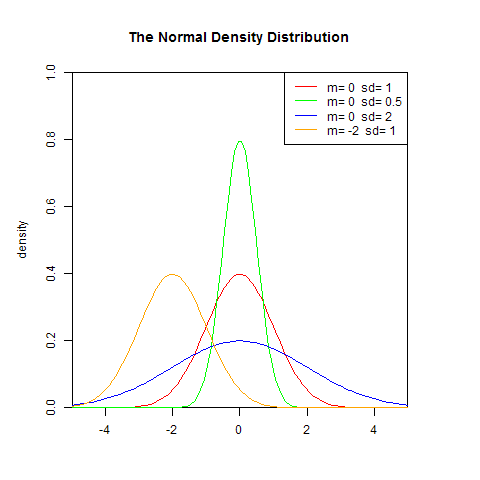
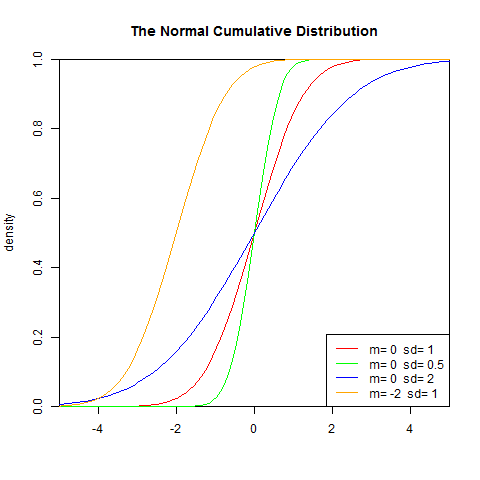
若隨機變數X服從一個數學期望為μ、方差為σ^2的正態分佈,記為N(μ,σ^2)。其概率密度函式為正態分佈的期望值μ決定了其位置,其標準差σ決定了分佈的幅度。因其曲線呈鐘形,因此人們又經常稱之為鐘形曲線。我們通常所說的標準正態分佈是μ = 0,σ = 1的正態分佈。
1). 概率密度函式
![]()
set.seed(1) x <- seq(-5,5,length.out=100) y <- dnorm(x,0,1) plot(x,y,col="red",xlim=c(-5,5),ylim=c(0,1),type='l', xaxs="i", yaxs="i",ylab='density',xlab='', main="The Normal Density Distribution") lines(x,dnorm(x,0,0.5),col="green") lines(x,dnorm(x,0,2),col="blue") lines(x,dnorm(x,-2,1),col="orange") legend("topright",legend=paste("m=",c(0,0,0,-2)," sd=", c(1,0.5,2,1)), lwd=1, col=c("red", "green","blue","orange"))
2). 累積分佈函式
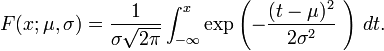
set.seed(1)
x <- seq(-5,5,length.out=100)
y <- pnorm(x,0,1)
plot(x,y,col="red",xlim=c(-5,5),ylim=c(0,1),type='l',
xaxs="i", yaxs="i",ylab='density',xlab='',
main="The Normal Cumulative Distribution")
lines(x,pnorm(x,0,0.5),col="green")
lines(x,pnorm(x,0,2),col="blue")
lines(x,pnorm(x,-2,1),col="orange")
legend("bottomright",legend=paste("m=",c(0,0,0,-2)," sd=", c(1,0.5,2,1)), lwd=1,col=c("red", "green","blue","orange"))
3). 分佈檢驗
Shapiro-Wilk正態分佈檢驗: 用來檢驗是否資料符合正態分佈,類似於線性迴歸的方法一樣,是檢驗其於迴歸曲線的殘差。該方法推薦在樣本量很小的時候使用,樣本在3到5000之間。
該檢驗原假設為H0:資料集符合正態分佈,統計量W為:
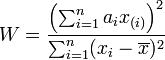
- 統計量W 最大值是1,越接近1,表示樣本與正態分佈匹配
-
p值,如果p-value小於顯著性水平α(0.05),則拒絕H0
R語言程式
> set.seed(1) > S<-rnorm(1000) > shapiro.test(S) Shapiro-Wilk normality test data: S W = 0.9988, p-value = 0.7256結論: W接近1,p-value>0.05,不能拒絕原假設,所以資料集S符合正態分佈!
Kolmogorov-Smirnov連續分佈檢驗:檢驗單一樣本是不是服從某一預先假設的特定分佈的方法。以樣本資料的累計頻數分佈與特定理論分佈比較,若兩者間的差距很小,則推論該樣本取自某特定分佈族。
該檢驗原假設為H0:資料集符合正態分佈,H1:樣本所來自的總體分佈不符合正態分佈。令F0(x)表示預先假設的理論分佈,Fn(x)表示隨機樣本的累計概率(頻率)函式.
統計量D為: D=max|F0(x) - Fn(x)|
- D值越小,越接近0,表示樣本資料越接近正態分佈
- p值,如果p-value小於顯著性水平α(0.05),則拒絕H0
> set.seed(1) > S<-rnorm(1000) > ks.test(S, "pnorm") One-sample Kolmogorov-Smirnov test data: S D = 0.0211, p-value = 0.7673 alternative hypothesis: two-sided結論: D值很小, p-value>0.05,不能拒絕原假設,所以資料集S符合正態分佈!
2. 指數分佈
指數分佈(Exponential distribution)用來表示獨立隨機事件發生的時間間隔,比如旅客進機場的時間間隔、中文維基百科新條目出現的時間間隔等等。
許多電子產品的壽命分佈一般服從指數分佈。有的系統的壽命分佈也可用指數分佈來近似。它在可靠性研究中是最常用的一種分佈形式。指數分佈是伽瑪分佈和weibull分佈的特殊情況,產品的失效是偶然失效時,其壽命服從指數分佈。
指數分佈可以看作當weibull分佈中的形狀係數等於1的特殊分佈,指數分佈的失效率是與時間t無關的常數,所以分佈函式簡單。
1). 概率密度函式
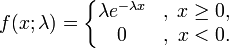
其中λ > 0是分佈的一個引數,常被稱為率引數(rate parameter)。即每單位時間發生該事件的次數。指數分佈的區間是[0,∞)。 如果一個隨機變數X 呈指數分佈,則可以寫作:X ~ Exponential(λ)。
set.seed(1) x<-seq(-1,2,length.out=100) y<-dexp(x,0.5) plot(x,y,col="red",xlim=c(0,2),ylim=c(0,5),type='l', xaxs="i", yaxs="i",ylab='density',xlab='', main="The Exponential Density Distribution") lines(x,dexp(x,1),col="green") lines(x,dexp(x,2),col="blue") lines(x,dexp(x,5),col="orange") legend("topright",legend=paste("rate=",c(.5, 1, 2,5)), lwd=1,col=c("red", "green","blue","orange"))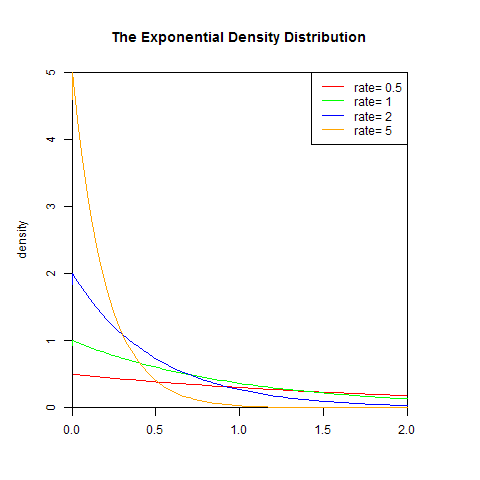
2). 累積分佈函式
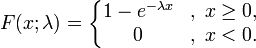
set.seed(1) x<-seq(-1,2,length.out=100) y<-pexp(x,0.5) plot(x,y,col="red",xlim=c(0,2),ylim=c(0,1),type='l', xaxs="i", yaxs="i",ylab='density',xlab='', main="The Exponential Cumulative Distribution Function") lines(x,pexp(x,1),col="green") lines(x,pexp(x,2),col="blue") lines(x,pexp(x,5),col="orange") legend("bottomright",legend=paste("rate=",c(.5, 1, 2,5)), lwd=1, col=c("red", "green","blue","orange"))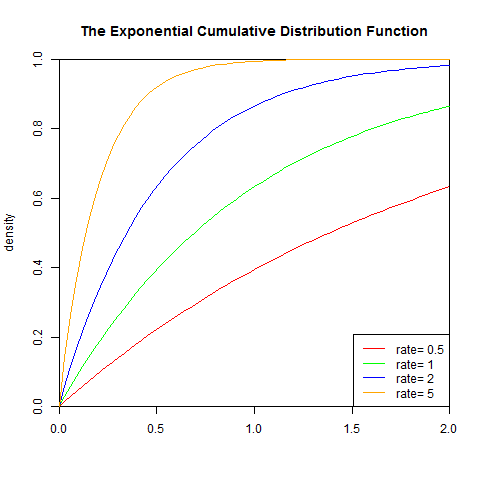
3). 分佈檢驗
Kolmogorov-Smirnov連續分佈檢驗:檢驗單一樣本是不是服從某一預先假設的特定分佈的方法。以樣本資料的累計頻數分佈與特定理論分佈比較,若兩者間的差距很小,則推論該樣本取自某特定分佈族。
該檢驗原假設為H0:資料集符合指數分佈,H1:樣本所來自的總體分佈不符合指數分佈。令F0(x)表示預先假設的理論分佈,Fn(x)表示隨機樣本的累計概率(頻率)函式.
統計量D為: D=max|F0(x) - Fn(x)|
- D值越小,越接近0,表示樣本資料越接近指數分佈
- p值,如果p-value小於顯著性水平α(0.05),則拒絕H0
> set.seed(1) > S<-rexp(1000) > ks.test(S, "pexp") One-sample Kolmogorov-Smirnov test data: S D = 0.0387, p-value = 0.1001 alternative hypothesis: two-sided結論: D值很小, p-value>0.05,不能拒絕原假設,所以資料集S符合指數分佈!
3. γ(伽瑪)分佈
伽瑪分佈(Gamma)是著名的皮爾遜概率分佈函式簇中的重要一員,稱為皮爾遜Ⅲ型分佈。它的曲線有一個峰,但左右不對稱。
伽瑪分佈中的引數α,稱為形狀引數,β稱為尺度引數。
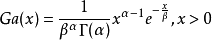
伽瑪函式為:
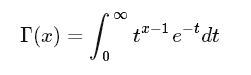
伽瑪函式是階乘在實數上的泛化。
1). 概率密度函式
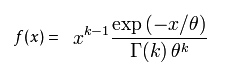
set.seed(1) x<-seq(0,10,length.out=100) y<-dgamma(x,1,2) plot(x,y,col="red",xlim=c(0,10),ylim=c(0,2),type='l', xaxs="i", yaxs="i",ylab='density',xlab='', main="The Gamma Density Distribution") lines(x,dgamma(x,2,2),col="green") lines(x,dgamma(x,3,2),col="blue") lines(x,dgamma(x,5,1),col="orange") lines(x,dgamma(x,9,1),col="black") legend("topright",legend=paste("shape=",c(1,2,3,5,9)," rate=", c(2,2,2,1,1)), lwd=1, col=c("red", "green","blue","orange","black"))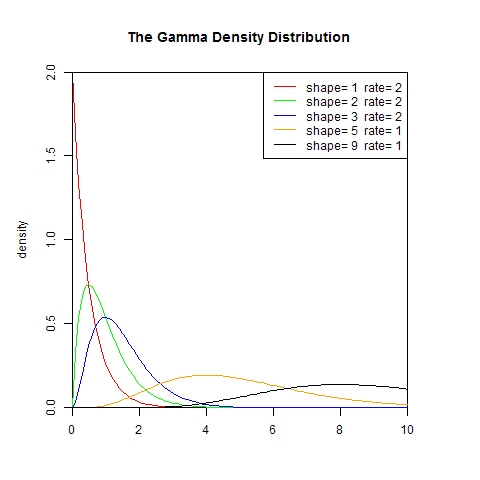
2). 累積分佈函式
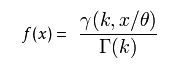
set.seed(1) x<-seq(0,10,length.out=100) y<-pgamma(x,1,2) plot(x,y,col="red",xlim=c(0,10),ylim=c(0,1),type='l', xaxs="i", yaxs="i",ylab='density',xlab='', main="The Gamma Cumulative Distribution Function") lines(x,pgamma(x,2,2),col="green") lines(x,pgamma(x,3,2),col="blue") lines(x,pgamma(x,5,1),col="orange") lines(x,pgamma(x,9,1),col="black") legend("bottomright",legend=paste("shape=",c(1,2,3,5,9)," rate=", c(2,2,2,1,1)), lwd=1, col=c("red", "green","blue","orange","black"))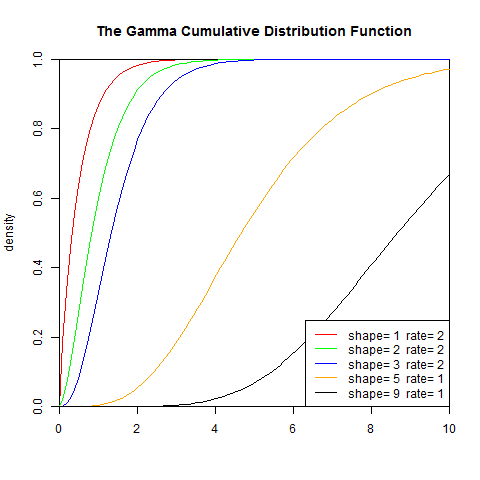
3). 分佈檢驗
Kolmogorov-Smirnov連續分佈檢驗: 檢驗單一樣本是不是服從某一預先假設的特定分佈的方法。以樣本資料的累計頻數分佈與特定理論分佈比較,若兩者間的差距很小,則推論該樣本取自某特定分佈族。
該檢驗原假設為H0:資料集符合伽瑪分佈,H1:樣本所來自的總體分佈不符合伽瑪分佈。令F0(x)表示預先假設的理論分佈,Fn(x)表示隨機樣本的累計概率(頻率)函式.
統計量D為: D=max|F0(x) - Fn(x)|
- D值越小,越接近0,表示樣本資料越接近伽瑪分佈
- p值,如果p-value小於顯著性水平α(0.05),則拒絕H0
> set.seed(1) > S<-rgamma(1000,1) > ks.test(S, "pgamma", 1) One-sample Kolmogorov-Smirnov test data: S D = 0.0363, p-value = 0.1438 alternative hypothesis: two-sided結論: D值很小, p-value>0.05,不能拒絕原假設,所以資料集S符合shape=1伽瑪分佈!
檢驗失敗:
> ks.test(S, "pgamma", 2) One-sample Kolmogorov-Smirnov test data: S D = 0.3801, p-value < 2.2e-16 alternative hypothesis: two-sided結論:D值不夠小, p-value<0.05,拒絕原假設,所以資料集S符合shape=2伽瑪分佈!
4. weibull分佈
weibull(韋伯)分佈,又稱韋氏分佈或威布林分佈,是可靠性分析和壽命檢驗的理論基礎。Weibull分佈能被應用於很多形式,分佈由形狀、尺度(範圍)和位置三個引數決定。其中形狀引數是最重要的引數,決定分佈密度曲線的基本形狀,尺度引數起放大或縮小曲線的作用,但不影響分佈的形狀。
Weibull分佈通常用在故障分析領域( field of failure analysis)中;尤其是它可以模擬(mimic) 故障率(failture rate)持續( over time)變化的分佈。故障率為:
- 一直為常量(constant over time), 那麼 α = 1, 暗示在隨機事件中發生
- 一直減少(decreases over time),那麼α < 1, 暗示"早期失效(infant mortality)"
- 一直增加(increases over time),那麼α > 1, 暗示"耗盡(wear out)" - 隨著時間的推進,失敗的可能性變大
1). 概率密度函式
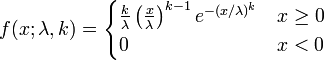
set.seed(1) x<- seq(0, 2.5, length.out=1000) y<- dweibull(x, 0.5) plot(x, y, type="l", col="blue",xlim=c(0, 2.5),ylim=c(0, 6), xaxs="i", yaxs="i",ylab='density',xlab='', main="The Weibull Density Distribution") lines(x, dweibull(x, 1), type="l", col="red") lines(x, dweibull(x, 1.5), type="l", col="magenta") lines(x, dweibull(x, 5), type="l", col="green") lines(x, dweibull(x, 15), type="l", col="purple") legend("topright", legend=paste("shape =", c(.5, 1, 1.5, 5, 15)), lwd=1,col=c("blue", "red", "magenta", "green","purple"))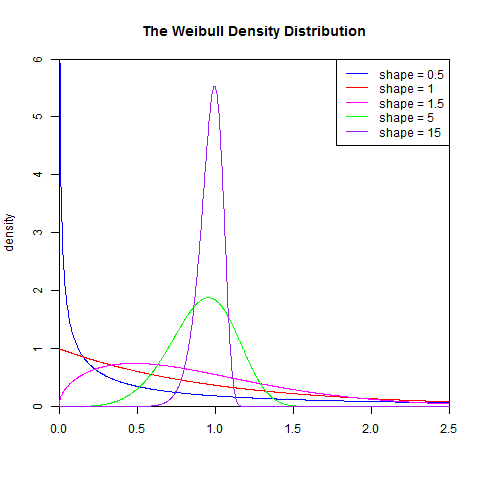
2). 累積分佈函式
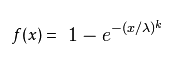
set.seed(1) x<- seq(0, 2.5, length.out=1000) y<- pweibull(x, 0.5) plot(x, y, type="l", col="blue",xlim=c(0, 2.5),ylim=c(0, 1.2), xaxs="i", yaxs="i",ylab='density',xlab='', main="The Weibull Cumulative Distribution Function") lines(x, pweibull(x, 1), type="l", col="red") lines(x, pweibull(x, 1.5), type="l", col="magenta") lines(x, pweibull(x, 5), type="l", col="green") lines(x, pweibull(x, 15), type="l", col="purple") legend("bottomright", legend=paste("shape =", c(.5, 1, 1.5, 5, 15)), lwd=1, col=c("blue", "red", "magenta", "green","purple"))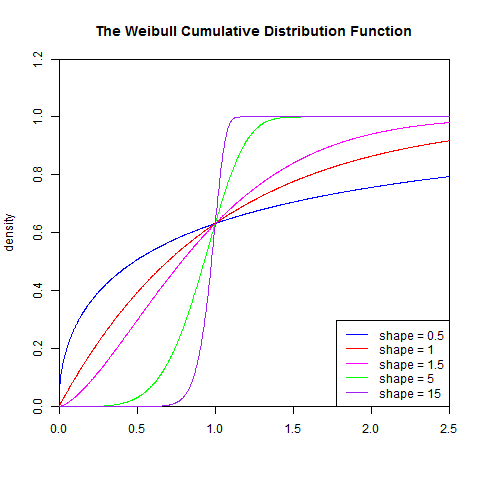
3). 分佈檢驗
Kolmogorov-Smirnov連續分佈檢驗: 檢驗單一樣本是不是服從某一預先假設的特定分佈的方法。以樣本資料的累計頻數分佈與特定理論分佈比較,若兩者間的差距很小,則推論該樣本取自某特定分佈族。
該檢驗原假設為H0:資料集符合weibull分佈,H1:樣本所來自的總體分佈不符合weibull分佈。令F0(x)表示預先假設的理論分佈,Fn(x)表示隨機樣本的累計概率(頻率)函式.
統計量D為: D=max|F0(x) - Fn(x)|
- D值越小,越接近0,表示樣本資料越接近weibull分佈
- p值,如果p-value小於顯著性水平α(0.05),則拒絕H0
> set.seed(1) > S<-rweibull(1000,1) > ks.test(S, "pweibull",1) One-sample Kolmogorov-Smirnov test data: S D = 0.0244, p-value = 0.5928 alternative hypothesis: two-sided結論: D值很小, p-value>0.05,不能拒絕原假設,所以資料集S符合shape=1的weibull分佈!
5. F分佈
F-分佈(F-distribution)是一種連續概率分佈,被廣泛應用於似然比率檢驗,特別是ANOVA中。F分佈定義為:設X、Y為兩個獨立的隨機變數,X服從自由度為k1的卡方分佈,Y服從自由度為k2的卡方分佈,這2 個獨立的卡方分佈被各自的自由度除以後的比率這一統計量的分佈。即: 上式F服從第一自由度為k1,第二自由度為k2的F分佈。
F分佈的性質
- 它是一種非對稱分佈
- 它有兩個自由度,即n1 -1和n2-1,相應的分佈記為F( n1 –1, n2-1), n1 –1通常稱為分子自由度, n2-1通常稱為分母自由度
- F分佈是一個以自由度n1 –1和n2-1為引數的分佈族,不同的自由度決定了F 分佈的形狀
- F分佈的倒數性質:Fα,df1,df2=1/F1-α,df1,df2[1]
1). 概率密度函式
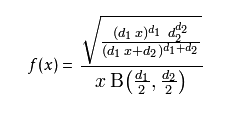
B是Beta函式(beta function)
set.seed(1) x<-seq(0,5,length.out=1000) y<-df(x,1,1,0) plot(x,y,col="red",xlim=c(0,5),ylim=c(0,1),type='l', xaxs="i", yaxs="i",ylab='density',xlab='', main="The F Density Distribution") lines(x,df(x,1,1,2),col="green") lines(x,df(x,2,2,2),col="blue") lines(x,df(x,2,4,4),col="orange") legend("topright",legend=paste("df1=",c(1,1,2,2),"df2=",c(1,1,2,4)," ncp=", c(0,2,2,4)), lwd=1, col=c("red", "green","blue","orange"))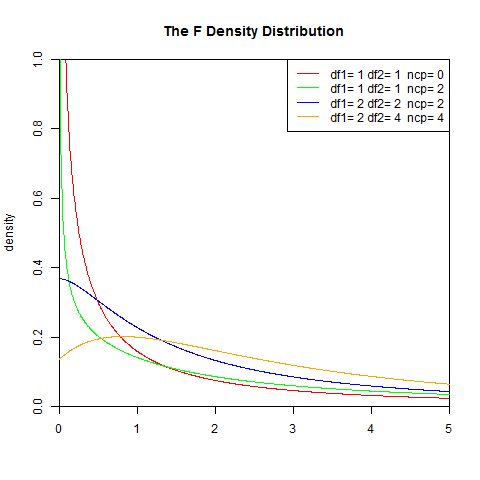
2). 累積分佈函式
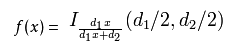
I是不完全Beta函式
set.seed(1) x<-seq(0,5,length.out=1000) y<-df(x,1,1,0) plot(x,y,col="red",xlim=c(0,5),ylim=c(0,1),type='l', xaxs="i", yaxs="i",ylab='density',xlab='', main="The F Cumulative Distribution Function") lines(x,pf(x,1,1,2),col="green") lines(x,pf(x,2,2,2),col="blue") lines(x,pf(x,2,4,4),col="orange") legend("topright",legend=paste("df1=",c(1,1,2,2),"df2=",c(1,1,2,4)," ncp=", c(0,2,2,4)), lwd=1, col=c("red", "green","blue","orange"))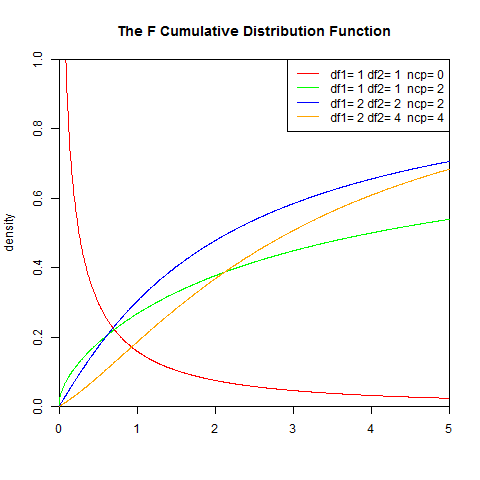
3). 分佈檢驗
Kolmogorov-Smirnov連續分佈檢驗: 檢驗單一樣本是不是服從某一預先假設的特定分佈的方法。以樣本資料的累計頻數分佈與特定理論分佈比較,若兩者間的差距很小,則推論該樣本取自某特定分佈族。
該檢驗原假設為H0:資料集符合F分佈,H1:樣本所來自的總體分佈不符合F分佈。令F0(x)表示預先假設的理論分佈,Fn(x)表示隨機樣本的累計概率(頻率)函式.
統計量D為: D=max|F0(x) - Fn(x)|
- D值越小,越接近0,表示樣本資料越接近F分佈
- p值,如果p-value小於顯著性水平α(0.05),則拒絕H0
> set.seed(1) > S<-rf(1000,1,1,2) > ks.test(S, "pf", 1,1,2) One-sample Kolmogorov-Smirnov test data: S D = 0.0113, p-value = 0.9996 alternative hypothesis: two-sided結論: D值很小, p-value>0.05,不能拒絕原假設,所以資料集S符合df1=1, df2=1, ncp=2的F分佈!
6. T分佈
學生t-分佈(Student's t-distribution),可簡稱為t分佈。應用在估計呈正態分佈的母群體之平均數。它是對兩個樣本均值差異進行顯著性測試的學生t檢定的基礎。學生t檢定改進了Z檢定(Z-test),因為Z檢定以母體標準差已知為前提。雖然在樣本數量大(超過30個)時,可以應用Z檢定來求得近似值,但Z檢定用在小樣本會產生很大的誤差,因此必須改用學生t檢定以求準確。
在母體標準差未知的情況下,不論樣本數量大或小皆可應用學生t檢定。在待比較的資料有三組以上時,因為誤差無法壓低,此時可以用變異數分析(ANOVA)代替學生t檢定。
1). 概率密度函式
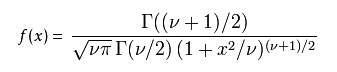
v 等於n − 1。 T的分佈稱為t-分佈。引數\nu 一般被稱為自由度。
γ 是伽瑪函式。set.seed(1) x<-seq(-5,5,length.out=1000) y<-dt(x,1,0) plot(x,y,col="red",xlim=c(-5,5),ylim=c(0,0.5),type='l', xaxs="i", yaxs="i",ylab='density',xlab='', main="The T Density Distribution") lines(x,dt(x,5,0),col="green") lines(x,dt(x,5,2),col="blue") lines(x,dt(x,50,4),col="orange") legend("topleft",legend=paste("df=",c(1,5,5,50)," ncp=", c(0,0,2,4)), lwd=1, col=c("red", "green","blue","orange"))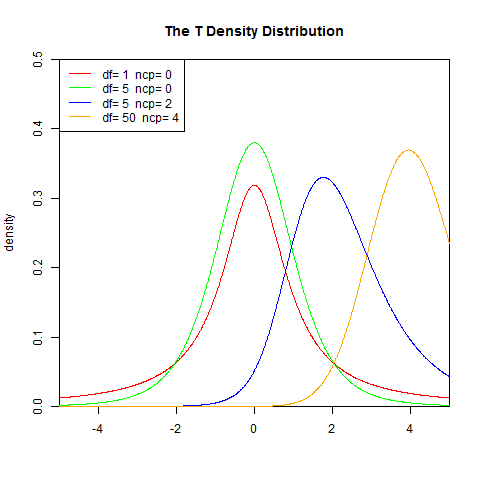
2). 累積分佈函式
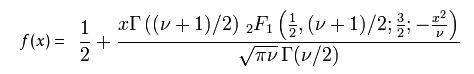
v 等於n − 1。 T的分佈稱為t-分佈。引數\nu 一般被稱為自由度。
γ 是伽瑪函式。set.seed(1) x<-seq(-5,5,length.out=1000) y<-pt(x,1,0) plot(x,y,col="red",xlim=c(-5,5),ylim=c(0,0.5),type='l', xaxs="i", yaxs="i",ylab='density',xlab='', main="The T Cumulative Distribution Function") lines(x,pt(x,5,0),col="green") lines(x,pt(x,5,2),col="blue") lines(x,pt(x,50,4),col="orange") legend("topleft",legend=paste("df=",c(1,5,5,50)," ncp=", c(0,0,2,4)), lwd=1, col=c("red", "green","blue","orange"))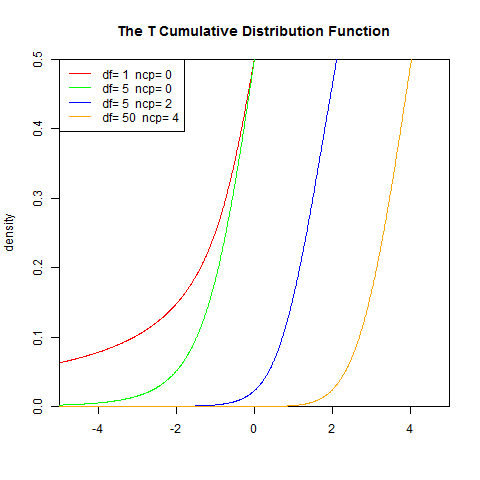
3). 分佈檢驗
Kolmogorov-Smirnov連續分佈檢驗: 檢驗單一樣本是不是服從某一預先假設的特定分佈的方法。以樣本資料的累計頻數分佈與特定理論分佈比較,若兩者間的差距很小,則推論該樣本取自某特定分佈族。
該檢驗原假設為H0:資料集符合T分佈,H1:樣本所來自的總體分佈不符合T分佈。令F0(x)表示預先假設的理論分佈,Fn(x)表示隨機樣本的累計概率(頻率)函式.
統計量D為: D=max|F0(x) - Fn(x)|
- D值越小,越接近0,表示樣本資料越接近T分佈
- p值,如果p-value小於顯著性水平α(0.05),則拒絕H0
> set.seed(1) > S<-rt(1000, 1,2) > ks.test(S, "pt", 1, 2) One-sample Kolmogorov-Smirnov test data: S D = 0.0253, p-value = 0.5461 alternative hypothesis: two-sided結論: D值很小, p-value>0.05,不能拒絕原假設,所以資料集S符合df1=1, ncp=2的T分佈!
7. β(貝塔Beta)分佈
貝塔分佈(Beta Distribution)是指一組定義在(0,1)區間的連續概率分佈,Beta分佈有α和β兩個引數α,β>0,其中α為成功次數加1,β為失敗次數加1。
Beta分佈的一個重要應該是作為伯努利分佈和二項式分佈的共軛先驗分佈出現,在機器學習和數理統計學中有重要應用。貝塔分佈中的引數可以理解為偽計數,伯努利分佈的似然函式可以表示為,表示一次事件發生的概率,它為貝塔有相同的形式,因此可以用貝塔分佈作為其先驗分佈。
1). 概率密度函式
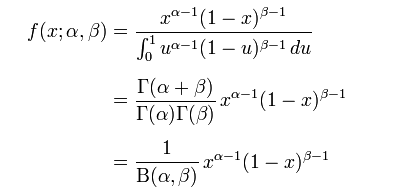
隨機變數X服從引數為a, β,服從Beta分佈
γ 是伽瑪函式set.seed(1) x<-seq(-5,5,length.out=10000) y<-dbeta(x,0.5,0.5) plot(x,y,col="red",xlim=c(0,1),ylim=c(0,6),type='l', xaxs="i", yaxs="i",ylab='density',xlab='', main="The Beta Density Distribution") lines(x,dbeta(x,5,1),col="green") lines(x,dbeta(x,1,3),col="blue") lines(x,dbeta(x,2,2),col="orange") lines(x,dbeta(x,2,5),col="black") legend("top",legend=paste("a=",c(.5,5,1,2,2)," b=", c(.5,1,3,2,5)), lwd=1,col=c("red", "green","blue","orange","black"))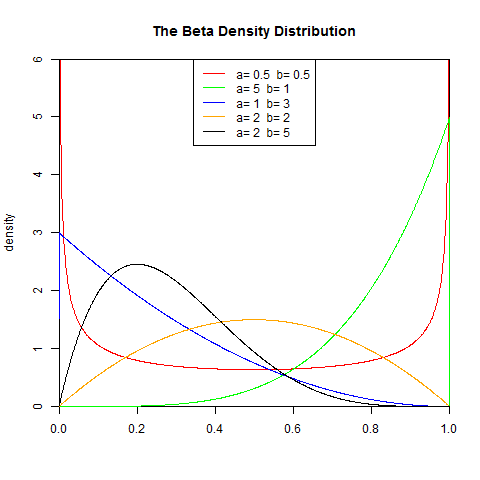
2). 累積分佈函式
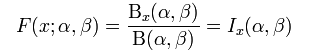
I是正則不完全Beta函式
set.seed(1) x<-seq(-5,5,length.out=10000) y<-pbeta(x,0.5,0.5) plot(x,y,col="red",xlim=c(0,1),ylim=c(0,1),type='l', xaxs="i", yaxs="i",ylab='density',xlab='', main="The Beta Cumulative Distribution Function") lines(x,pbeta(x,5,1),col="green") lines(x,pbeta(x,1,3),col="blue") lines(x,pbeta(x,2,2),col="orange") lines(x,pbeta(x,2,5),col="black") legend("topleft",legend=paste("a=",c(.5,5,1,2,2)," b=", c(.5,1,3,2,5)), lwd=1,col=c("red", "green","blue","orange","black"))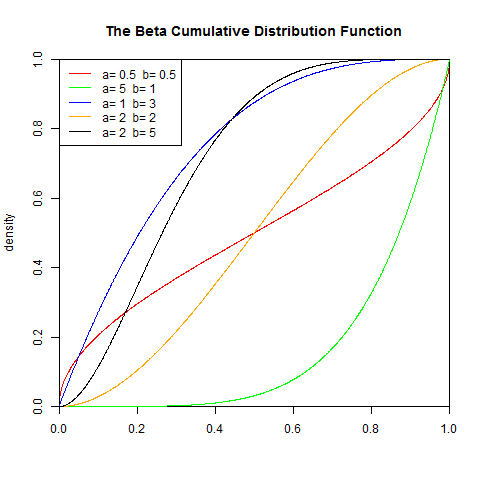
3). 分佈檢驗
Kolmogorov-Smirnov連續分佈檢驗: 檢驗單一樣本是不是服從某一預先假設的特定分佈的方法。以樣本資料的累計頻數分佈與特定理論分佈比較,若兩者間的差距很小,則推論該樣本取自某特定分佈族。
該檢驗原假設為H0:資料集符合Beta分佈,H1:樣本所來自的總體分佈不符合Beta分佈。令F0(x)表示預先假設的理論分佈,Fn(x)表示隨機樣本的累計概率(頻率)函式.
統計量D為: D=max|F0(x) - Fn(x)|
- D值越小,越接近0,表示樣本資料越接近Beta分佈
- p值,如果p-value小於顯著性水平α(0.05),則拒絕H0
> set.seed(1) > S<-rbeta(1000,1,2) > ks.test(S, "pbeta",1,2) One-sample Kolmogorov-Smirnov test data: S D = 0.0202, p-value = 0.807 alternative hypothesis: two-sided結論: D值很小, p-value>0.05,不能拒絕原假設,所以資料集S符合shape1=1, shape2=2的Beta分佈!
8. χ²(卡方)分佈
若n個相互獨立的隨機變數ξ₁、ξ₂、……、ξn ,均服從標準正態分佈(也稱獨立同分佈於標準正態分佈),則這n個服從標準正態分佈的隨機變數的平方和構成一新的隨機變數,其分佈規律稱為χ²分佈(chi-square distribution)。其中引數n稱為自由度,自由度不同就是另一個χ²分佈,正如正態分佈中均值或方差不同就是另一個正態分佈一樣。
1). 概率密度函式
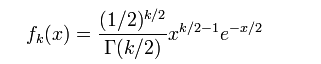
γ 是伽瑪函式
set.seed(1) x<-seq(0,10,length.out=1000) y<-dchisq(x,1) plot(x,y,col="red",xlim=c(0,5),ylim=c(0,2),type='l', xaxs="i", yaxs="i",ylab='density',xlab='', main="The Chisq Density Distribution") lines(x,dchisq(x,2),col="green") lines(x,dchisq(x,3),col="blue") lines(x,dchisq(x,10),col="orange") legend("topright",legend=paste("df=",c(1,2,3,10)), lwd=1, col=c("red", "green","blue","orange"))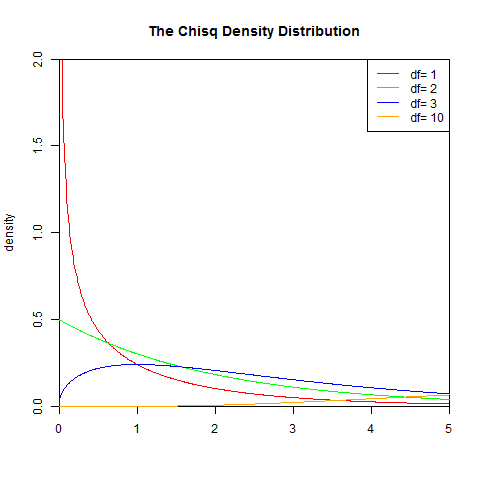
2). 累積分佈函式
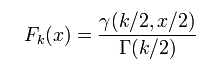
γ 是伽瑪函式
set.seed(1) x<-seq(0,10,length.out=1000) y<-pchisq(x,1) plot(x,y,col="red",xlim=c(0,10),ylim=c(0,1),type='l', xaxs="i", yaxs="i",ylab='density',xlab='', main="The Chisq Cumulative Distribution Function") lines(x,pchisq(x,2),col="green") lines(x,pchisq(x,3),col="blue") lines(x,pchisq(x,10),col="orange") legend("topleft",legend=paste("df=",c(1,2,3,10)), lwd=1, col=c("red", "green","blue","orange"))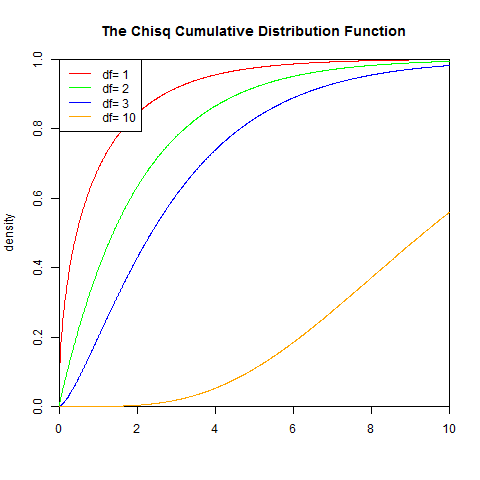
3). 分佈檢驗
Kolmogorov-Smirnov連續分佈檢驗: 檢驗單一樣本是不是服從某一預先假設的特定分佈的方法。以樣本資料的累計頻數分佈與特定理論分佈比較,若兩者間的差距很小,則推論該樣本取自某特定分佈族。
該檢驗原假設為H0:資料集符合卡方分佈,H1:樣本所來自的總體分佈不符合卡方分佈。令F0(x)表示預先假設的理論分佈,Fn(x)表示隨機樣本的累計概率(頻率)函式.
統計量D為: D=max|F0(x) - Fn(x)|
- D值越小,越接近0,表示樣本資料越接近卡方分佈
- p值,如果p-value小於顯著性水平α(0.05),則拒絕H0
> set.seed(1) > S<-rchisq(1000,1) > ks.test(S, "pchisq",1) One-sample Kolmogorov-Smirnov test data: S D = 0.0254, p-value = 0.5385 alternative hypothesis: two-sided結論: D值很小, p-value>0.05,不能拒絕原假設,所以資料集S符合df=1的卡方分佈!
9. 均勻分佈
均勻分佈(Uniform distribution)是均勻的,不偏差的一種簡單的概率分佈,分為:離散型均勻分佈與連續型均勻分佈。
1). 概率密度函式
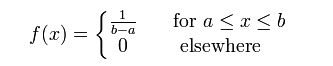
set.seed(1) x<-seq(0,10,length.out=1000) y<-dunif(x,0,1) plot(x,y,col="red",xlim=c(0,10),ylim=c(0,1.2),type='l', xaxs="i", yaxs="i",ylab='density',xlab='', main="The Uniform Density Distribution") lines(x,dnorm(x,0,0.5),col="green") lines(x,dnorm(x,0,2),col="blue") lines(x,dnorm(x,-2,1),col="orange") lines(x,dnorm(x,4,2),col="purple") legend("topright",legend=paste("m=",c(0,0,0,-2,4)," sd=", c(1,0.5,2,1,2)), lwd=1, col=c("red", "green","blue","orange","purple"))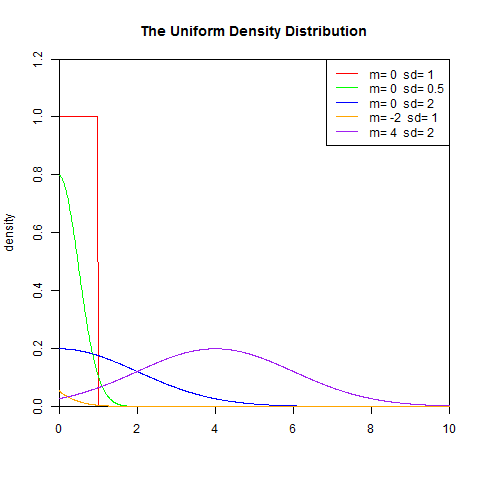
2). 累積分佈函式
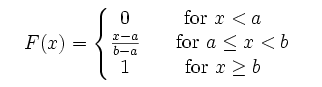
set.seed(1) x<-seq(0,10,length.out=1000) y<-punif(x,0,1) plot(x,y,col="red",xlim=c(0,10),ylim=c(0,1.2),type='l', xaxs="i", yaxs="i",ylab='density',xlab='', main="The Uniform Cumulative Distribution Function") lines(x,punif(x,0,0.5),col="green") lines(x,punif(x,0,2),col="blue") lines(x,punif(x,-2,1),col="orange") legend("bottomright",legend=paste("m=",c(0,0,0,-2)," sd=", c(1,0.5,2,1)), lwd=1, col=c("red", "green","blue","orange","purple"))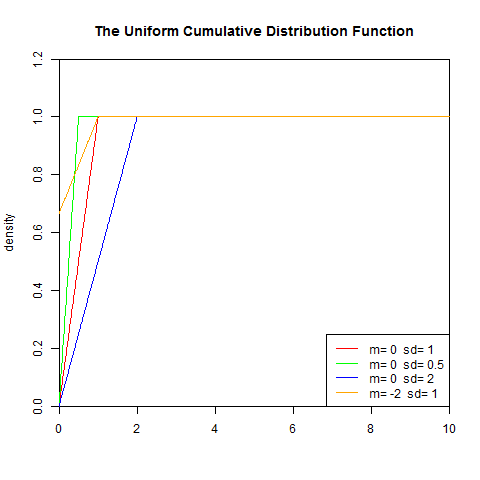
3). 分佈檢驗
Kolmogorov-Smirnov連續分佈檢驗: 檢驗單一樣本是不是服從某一預先假設的特定分佈的方法。以樣本資料的累計頻數分佈與特定理論分佈比較,若兩者間的差距很小,則推論該樣本取自某特定分佈族。
該檢驗原假設為H0:資料集符合均勻分佈,H1:樣本所來自的總體分佈不符合均勻分佈。令F0(x)表示預先假設的理論分佈,Fn(x)表示隨機樣本的累計概率(頻率)函式.
統計量D為: D=max|F0(x) - Fn(x)|
- D值越小,越接近0,表示樣本資料越接近均勻分佈
- p值,如果p-value小於顯著性水平α(0.05),則拒絕H0
> set.seed(1) > S<-runif(1000) > ks.test(S, "punif") One-sample Kolmogorov-Smirnov test data: S D = 0.0244, p-value = 0.5928 alternative hypothesis: two-sided結論: D值很小, p-value>0.05,不能拒絕原假設,所以資料集S符合均勻分佈!
在我們掌握了,這幾種常用的連續型分佈後,我們就可以基於這些分佈來建模了,很多的演算法模型就能解釋通了!!
參考資料