我讀R-FCN
背景
貢獻
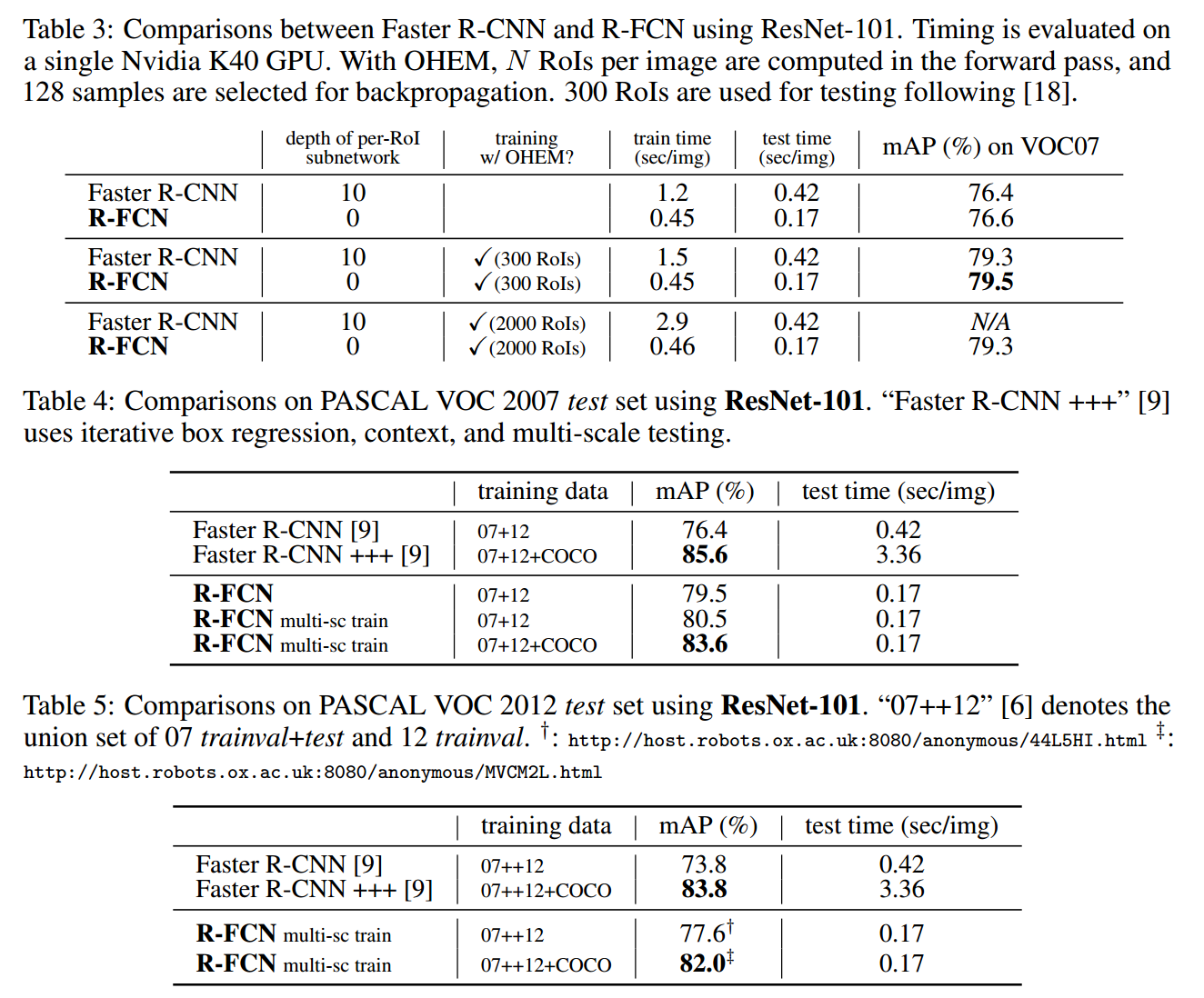
文章發表於 NIPS 2016,何凱明組新品。訓練和測試速度比上一篇 Faster R-CNN 都有提高,單張圖片測試用時 170ms,比 Faster R-CNN 快 2.5-20 倍,並且準確度略有提升(0.2%?)。
之前做法
R-CNN 系列對物體檢測主要步驟是先提 proposals,然後對每個 proposal 單獨做分類,同時微調 proposal 位置,最終使用非極大值抑制方法去除重疊的 proposal 得到最終結果。
Fast R-CNN 將提取 proposal 納入神經網路範圍,將神經網路最後一個 Pooling 層修改為 RoI 層,自此神經網路基於這個 RoI 層被分為前後兩部分,Fast/Faster R-CNN 在 RoI 層之後的神經網路對每個 proposal 進行運算時,都有一個神經子網路,產生大量計算。
方法
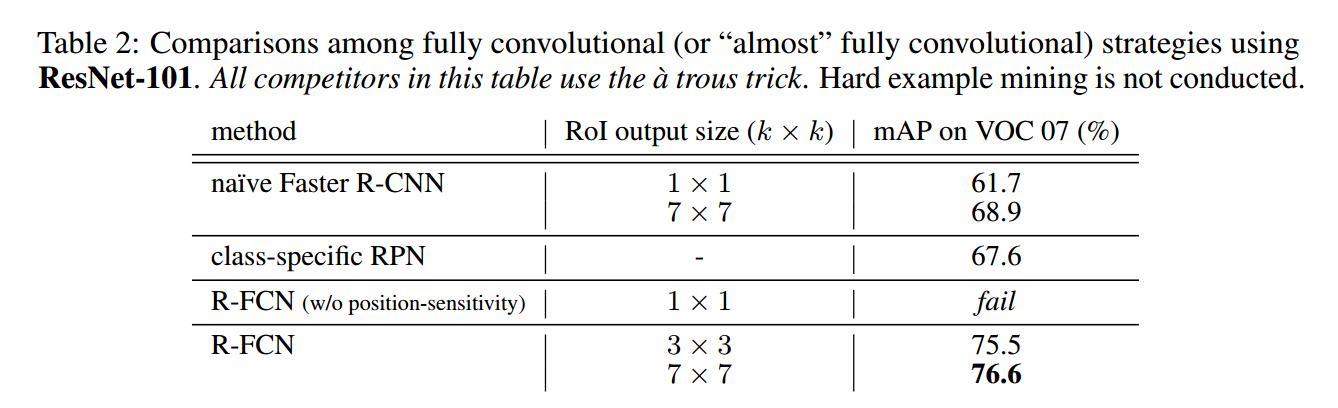
本文通過 pooling + voting 方法去除了 RoI 後面子網路引出的大量計算,提高了訓練和測試速度。下表可以看到,RoI 層後面子網路層數越來越少,在 R-FCN 中徹底幹掉了。

那沒有了子網路產生了一個問題,RoI 層後面接什麼,怎麼訓練?
物體檢測模型
作者這裡提出了一個理論,圖片分類要求網路具有平移不變性(這也是為什麼在 RoI 之前加入全連線層表現不好的原因),而物體檢測恰恰需要平移可變性。為了使 RoI 層後面具有平移可變性,作者提出在提出 RoI 層之後加入
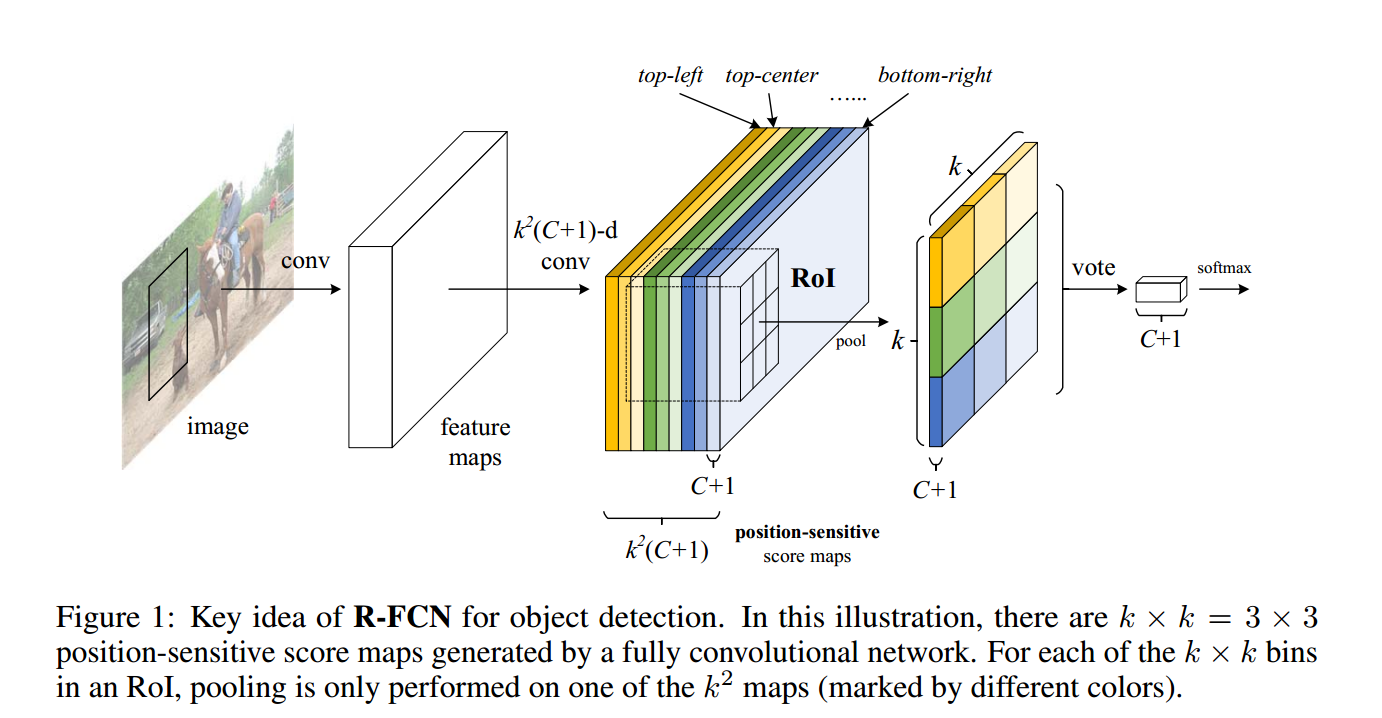
到這裡我們可以看到每個 RoI 都對應了
說了這麼多大家可能有點懵,看上面那張圖,第三步中的顏色表示到不同位置距離產生的 map,而每種顏色中 map 只取網格中一塊進行 pooling,輸出結果到第四步圖。簡單求和(voting)產生第五步圖,使用 softmax 標準 loss function。
邊界迴歸模型
使用和物體檢測相似方法,對
訓練
- Loss Function 和 Fast R-CNN 相同
- weight decay = 0.0005
- momentum = 0.9
- single scale, shorter size of image = 600 pixel
- 交叉訓練 RPN & F-RCN,同 Faster R-CNN -
實驗
- 非極大值抑制的 IoU 閾值為0.3
- 洞洞演算法1