
【RCNN系列】【超詳細解析】1

圖1 IoU定義
Region Proposal方法比傳統的滑動視窗方法獲取的質量要更高。比較常用的Region Proposal方法有:SelectiveSearch(SS,選擇性搜尋)、Edge Boxes(EB)。
基於Region Proposal目標檢測演算法的步驟如下:

其中:
CNN方法見http://blog.csdn.net/qq_17448289/article/details/52850223。
邊框迴歸(Bouding Box Regression):是對RegionProposal進行糾正的線性迴歸演算法,目的是為了讓Region Proposal提取到的視窗與目標視窗(Ground Truth)更加吻合。
二、R-CNN、Fast R-CNN、Faster R-CNN三者關係
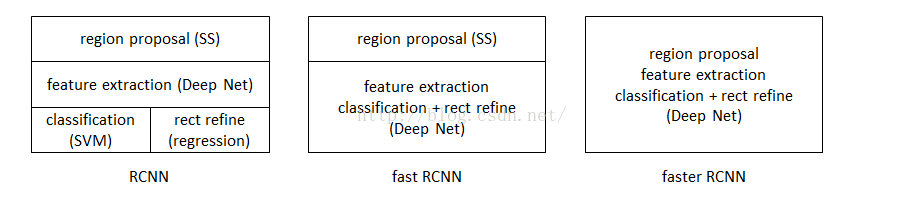
圖2 三者關係
表1 三者比較
|
|
使用方法 |
缺點 |
改進 |
| R-CNN (Region-based Convolutional Neural Networks) |
1、SS提取RP; 2、CNN提取特徵; 3、SVM分類; 4、BB盒迴歸。 |
1、 訓練步驟繁瑣(微調網路+訓練SVM+訓練bbox); 2、 訓練、測試均速度慢 ; 3、 訓練佔空間 |
1、 從DPM HSC的34.3%直接提升到了66%(mAP); 2、 引入RP+CNN |
| Fast R-CNN (Fast Region-based Convolutional Neural Networks) |
1、SS提取RP; 2、CNN提取特徵; 3、softmax分類; 4、多工損失函式邊框迴歸。 |
1、 依舊用SS提取RP(耗時2-3s,特徵提取耗時0.32s); 2、 無法滿足實時應用,沒有真正實現端到端訓練測試; 3、 利用了GPU,但是區域建議方法是在CPU上實現的。 |
1、 由66.9%提升到70%; 2、 每張影象耗時約為3s。 |
| Faster R-CNN (Fast Region-based Convolutional Neural Networks) |
1、RPN提取RP; 2、CNN提取特徵; 3、softmax分類; 4、多工損失函式邊框迴歸。 |
1、 還是無法達到實時檢測目標; 2、 獲取region proposal,再對每個proposal分類計算量還是比較大。 |
1、 提高了檢測精度和速度; 2、 真正實現端到端的目標檢測框架; 3、 生成建議框僅需約10ms。 |
2.1 R-CNN目標檢測流程介紹
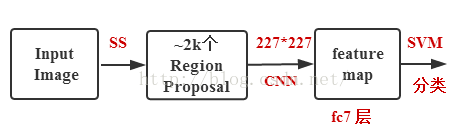
具體可參考http://blog.csdn.net/shenxiaolu1984/article/details/51066975
2.2 Fast R-CNN目標檢測流程介紹
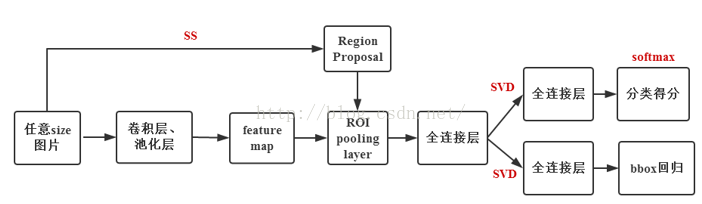
注意:Fast R-CNN的RegionProposal是在feature map之後做的,這樣可以不用對所有的區域進行單獨的CNN Forward步驟。
Fast R-CNN框架如下圖:
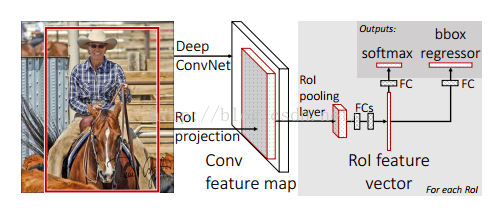
圖3 Fast R-CNN框架
Fast R-CNN框架與R-CNN有兩處不同:
① 最後一個卷積層後加了一個ROI pooling layer;
② 損失函式使用了multi-task loss(多工損失)函式,將邊框迴歸直接加到CNN網路中訓練。分類Fast R-CNN直接用softmax替代R-CNN用的SVM進行分類。
Fast R-CNN是端到端(end-to-end)的。
具體可參考http://blog.csdn.net/shenxiaolu1984/article/details/51036677
三、Faster R-CNN目標檢測
3.1 Faster R-CNN的思想
Faster R-CNN可以簡單地看做“區域生成網路RPNs + Fast R-CNN”的系統,用區域生成網路代替FastR-CNN中的Selective Search方法。Faster R-CNN這篇論文著重解決了這個系統中的三個問題:
1. 如何設計區域生成網路;
2. 如何訓練區域生成網路;
3. 如何讓區域生成網路和Fast RCNN網路共享特徵提取網路。
在整個Faster R-CNN演算法中,有三種尺度:
1. 原圖尺度:原始輸入的大小。不受任何限制,不影響效能。
2. 歸一化尺度:輸入特徵提取網路的大小,在測試時設定,原始碼中opts.test_scale=600。anchor在這個尺度上設定。這個引數和anchor的相對大小決定了想要檢測的目標範圍。
3. 網路輸入尺度:輸入特徵檢測網路的大小,在訓練時設定,原始碼中為224*224。
3.2 Faster R-CNN框架介紹

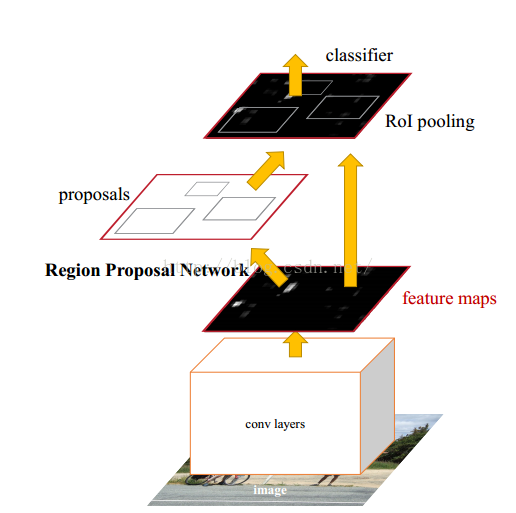
圖4 Faster R-CNN模型
Faster-R-CNN演算法由兩大模組組成:
1.PRN候選框提取模組;
2.Fast R-CNN檢測模組。
其中,RPN是全卷積神經網路,用於提取候選框;Fast R-CNN基於RPN提取的proposal檢測並識別proposal中的目標。
3.3 RPN介紹
3.3.1背景
目前最先進的目標檢測網路需要先用區域建議演算法推測目標位置,像SPPnet和Fast R-CNN這些網路雖然已經減少了檢測網路執行的時間,但是計算區域建議依然耗時較大。所以,在這樣的瓶頸下,RBG和Kaiming He一幫人將Region Proposal也交給CNN來做,這才提出了RPN(Region Proposal Network)區域建議網路用來提取檢測區域,它能和整個檢測網路共享全圖的卷積特徵,使得區域建議幾乎不花時間。
RCNN解決的是,“為什麼不用CNN做classification呢?”
Fast R-CNN解決的是,“為什麼不一起輸出bounding box和label呢?”
Faster R-CNN解決的是,“為什麼還要用selective search呢?”
3.3.2RPN核心思想
RPN的核心思想是使用CNN卷積神經網路直接產生Region Proposal,使用的方法本質上就是滑動視窗(只需在最後的卷積層上滑動一遍),因為anchor機制和邊框迴歸可以得到多尺度多長寬比的Region Proposal。
RPN網路也是全卷積網路(FCN,fully-convolutional network),可以針對生成檢測建議框的任務端到端地訓練,能夠同時預測出object的邊界和分數。只是在CNN上額外增加了2個卷積層(全卷積層cls和reg)。
①將每個特徵圖的位置編碼成一個特徵向量(256dfor ZF and 512d for VGG)。
②對每一個位置輸出一個objectness score和regressedbounds for k個region proposal,即在每個卷積對映位置輸出這個位置上多種尺度(3種)和長寬比(3種)的k個(3*3=9)區域建議的物體得分和迴歸邊界。
RPN網路的輸入可以是任意大小(但還是有最小解析度要求的,例如VGG是228*228)的圖片。如果用VGG16進行特徵提取,那麼RPN網路的組成形式可以表示為VGG16+RPN。
VGG16:參考
https://github.com/rbgirshick/py-faster-rcnn/blob/master/models/pascal_voc/VGG16/faster_rcnn_end2end/train.prototxt,可以看出VGG16中用於特徵提取的部分是13個卷積層(conv1_1---->conv5.3),不包括pool5及pool5後的網路層次結構。
因為我們的最終目標是和Fast R-CNN目標檢測網路共享計算,所以假設這兩個網路共享一系列卷積層。在論文的實驗中,ZF有5個可共享的卷積層, VGG有13個可共享的卷積層。
RPN的具體流程如下:使用一個小網路在最後卷積得到的特徵圖上進行滑動掃描,這個滑動網路每次與特徵圖上n*n(論文中n=3)的視窗全連線(影象的有效感受野很大,ZF是171畫素,VGG是228畫素),然後對映到一個低維向量(256d for ZF / 512d for VGG),最後將這個低維向量送入到兩個全連線層,即bbox迴歸層(reg)和box分類層(cls)。sliding window的處理方式保證reg-layer和cls-layer關聯了conv5-3的全部特徵空間。
reg層:預測proposal的anchor對應的proposal的(x,y,w,h)
cls層:判斷該proposal是前景(object)還是背景(non-object)。
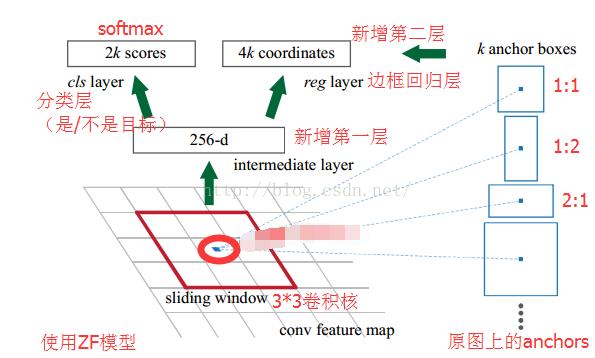
圖5 RPN框架
在圖5中,要注意,3*3卷積核的中心點對應原圖(re-scale,原始碼設定re-scale為600*1000)上的位置(點),將該點作為anchor的中心點,在原圖中框出多尺度、多種長寬比的anchors。所以,anchor不在conv特徵圖上,而在原圖上。

圖6 9種anchor(注意:是不同位置)
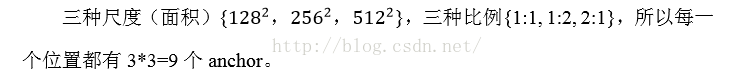
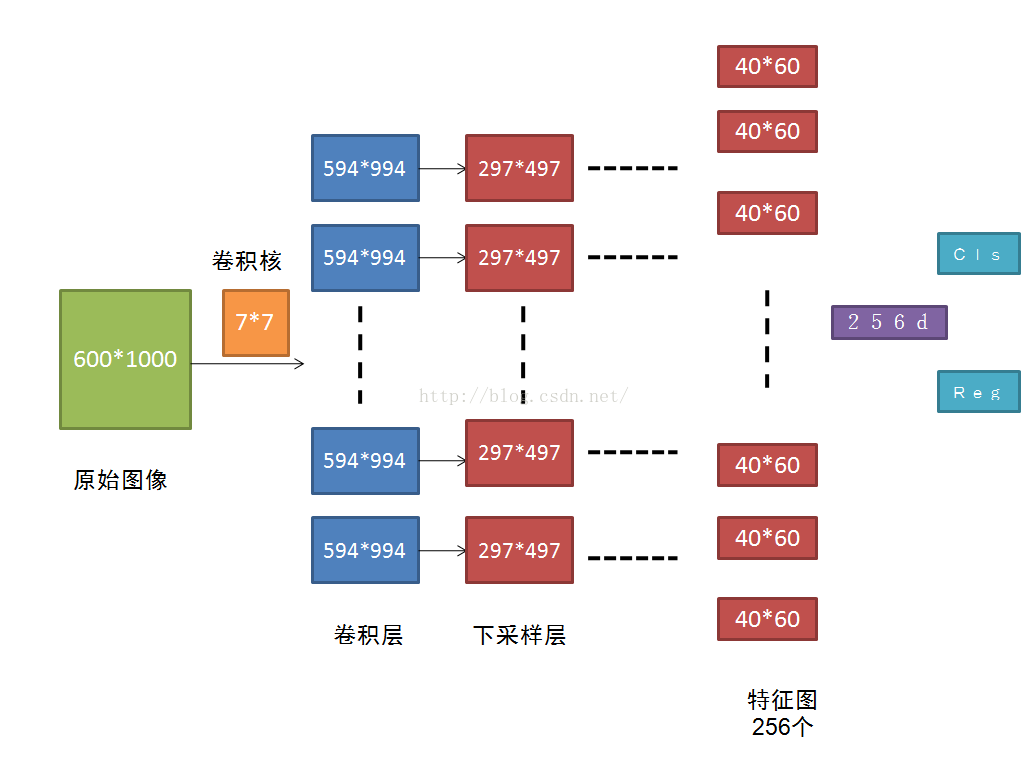
圖7 Faster R-CNN卷積流程圖
原圖600*1000經CNN卷積後,在CNN最後一層(conv5)得出的是40*60大小的特徵圖,對應文中說的典型值為2400。若特徵圖大小為W*H,則需要W*H*K個anchor,本文中需要40*60*9≈2k個。
在RPN網路中,我們需要重點理解其中的anchors概念,Loss fucntions計算方式和RPN層訓練資料生成的具體細節。
3.4 RPN的平移不變性
在計算機視覺中的一個挑戰就是平移不變性:比如人臉識別任務中,小的人臉(24*24的解析度)和大的人臉(1080*720)如何在同一個訓練好權值的網路中都能正確識別。若是平移了影象中的目標,則建議框也應該平移,也應該能用同樣的函式預測建議框。
傳統有兩種主流的解決方式:
第一、對影象或feature map層進行尺度\寬高的取樣;
第二、對濾波器進行尺度\寬高的取樣(或可以認為是滑動視窗).
但Faster R-CNN解決該問題的具體實現是:通過卷積核中心(用來生成推薦視窗的Anchor)進行尺度、寬高比的取樣,使用3種尺度和3種比例來產生9種anchor。
3.5 視窗分類和位置精修
分類層(cls_score)輸出每一個位置上,9個anchor屬於前景和背景的概率。
視窗迴歸層(bbox_pred)輸出每一個位置上,9個anchor對應視窗應該平移縮放的引數(x,y,w,h)。
對於每一個位置來說,分類層從256維特徵中輸出屬於前景和背景的概率;視窗迴歸層從256維特徵中輸出4個平移縮放參數。
需要注意的是:並沒有顯式地提取任何候選視窗,完全使用網路自身完成判斷和修正。
3.6 學習區域建議損失函式
3.6.1 標籤分類規定
為了訓練RPN,需要給每個anchor分配的類標籤{目標、非目標}。對於positive label(正標籤),論文中給瞭如下規定(滿足以下條件之一即可判為正標籤):

注意,一個GT包圍盒可以對應多個anchor,這樣一個GT包圍盒就可以有多個正標籤。
事實上,採用第②個規則基本上可以找到足夠的正樣本,但是對於一些極端情況,例如所有的Anchor對應的anchor box與groud truth的IoU不大於0.7,可以採用第一種規則生成。
negative label(負標籤):與所有GT包圍盒的IoU都小於0.3的anchor。
對於既不是正標籤也不是負標籤的anchor,以及跨越影象邊界的anchor我們給予捨棄,因為其對訓練目標是沒有任何作用的。
3.6.2 多工損失(來自Fast R-CNN)
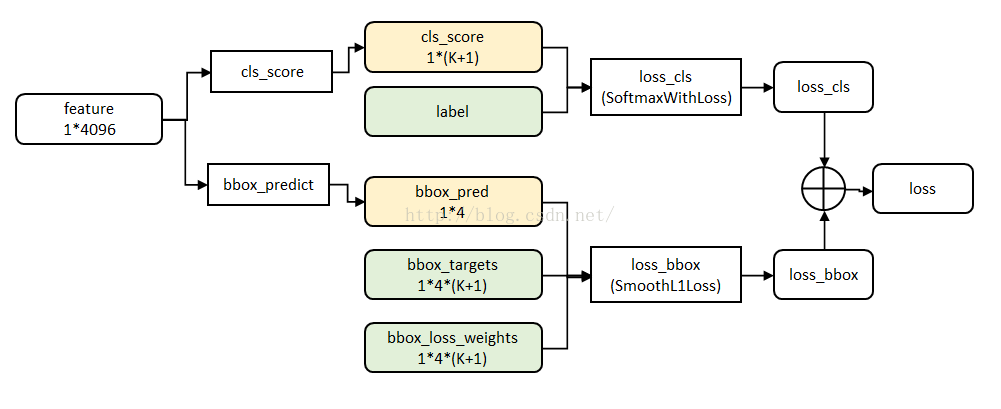
圖8 multi-task資料結構
Fast R-CNN網路有兩個同級輸出層(cls score和bbox_prdict層),都是全連線層,稱為multi-task。
① clsscore層:用於分類,輸出k+1維陣列p,表示屬於k類和背景的概率。對每個RoI(Region of Interesting)輸出離散型概率分佈
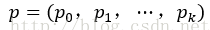
通常,p由k+1類的全連線層利用softmax計算得出。
② bbox_prdict層:用於調整候選區域位置,輸出bounding box迴歸的位移,輸出4*K維陣列t,表示分別屬於k類時,應該平移縮放的引數。
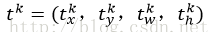
k表示類別的索引,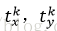
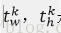
loss_cls層評估分類損失函式。由真實分類u對應的概率決定:

loss_bbox評估檢測框定位的損失函式。比較真實分類對應的預測平移縮放參數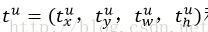
真實平移縮放參數為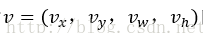
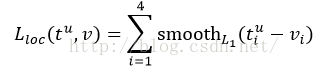
其中,smooth L1損失函式為:
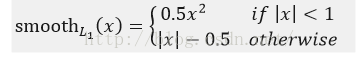
smooth L1損失函式曲線如下圖9所示,作者這樣設定的目的是想讓loss對於離群點更加魯棒,相比於L2損失函式,其對離群點、異常值(outlier)不敏感,可控制梯度的量級使訓練時不容易跑飛。
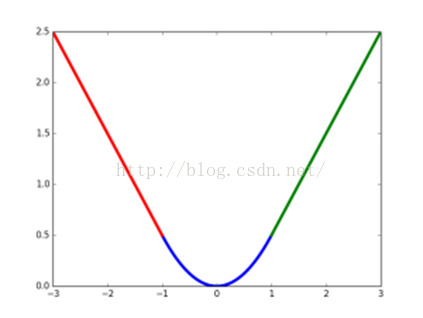
圖9 smoothL1損失函式曲線
最後總損失為(兩者加權和,如果分類為背景則不考慮定位損失):
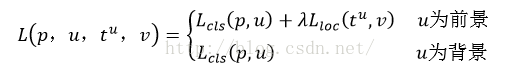
規定u=0為背景類(也就是負標籤),那麼艾弗森括號指數函式[u≥1]表示背景候選區域即負樣本不參與迴歸損失,不需要對候選區域進行迴歸操作。λ控制分類損失和迴歸損失的平衡。Fast R-CNN論文中,所有實驗λ=1。
艾弗森括號指數函式為:

原始碼中bbox_loss_weights用於標記每一個bbox是否屬於某一個類。
3.6.3 Faster R-CNN損失函式
遵循multi-task loss定義,最小化目標函式,FasterR-CNN中對一個影象的函式定義為:

其中:

3.6.4 R-CNN中的boundingbox迴歸
下面先介紹R-CNN和Fast R-CNN中所用到的邊框迴歸方法。
1. 為什麼要做Bounding-box regression?

圖10 示例
如圖10所示,綠色的框為飛機的Ground Truth,紅色的框是提取的Region Proposal。那麼即便紅色的框被分類器識別為飛機,但是由於紅色的框定位不準(IoU<0.5),那麼這張圖相當於沒有正確的檢測出飛機。如果我們能對紅色的框進行微調,使得經過微調後的視窗跟Ground Truth更接近,這樣豈不是定位會更準確。確實,Bounding-box regression 就是用來微調這個視窗的。
2. 迴歸/微調的物件是什麼?
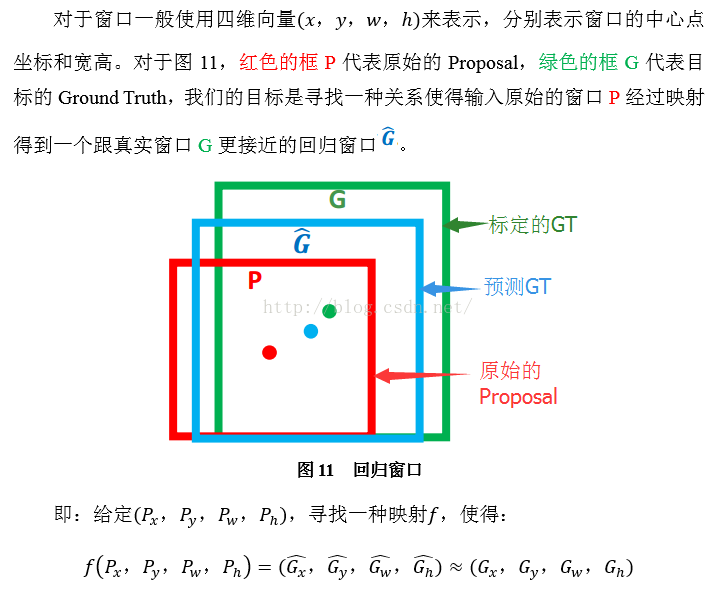
3. Bounding-box regression(邊框迴歸)
那麼經過何種變換才能從圖11中的視窗P變為視窗呢?比較簡單的思路就是:
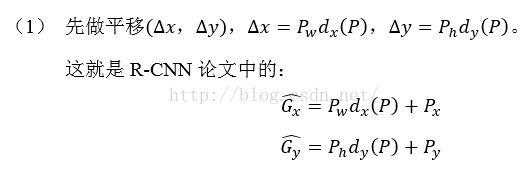

注意:只有當Proposal和Ground Truth比較接近時(線性問題),我們才能將其作為訓練樣本訓練我們的線性迴歸模型,否則會導致訓練的迴歸模型不work(當Proposal跟GT離得較遠,就是複雜的非線性問題了,此時用線性迴歸建模顯然不合理)。這個也是G-CNN: an Iterative Grid Based Object Detector多次迭代實現目標準確定位的關鍵。
線性迴歸就是給定輸入的特徵向量X,學習一組引數W,使得經過線性迴歸後的值跟真實值Y(Ground Truth)非常接近。即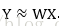
輸入: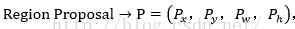
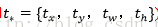
輸出:需要進行的平移變換和尺度縮放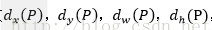
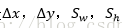
的確,這四個值應該是經過 Ground Truth 和Proposal計算得到的真正需要的平移量
這也就是R-CNN中的:
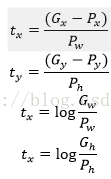
那麼目標函式可以表示為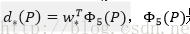
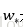
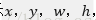
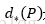
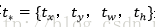
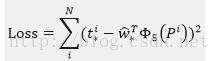
函式優化目標為:
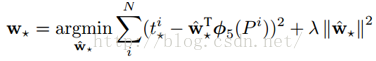
利用梯度下降法或者最小二乘法就可以得到
4. 測試階段
根據3我們學習到迴歸引數,對於測試影象,我們首先經過 CNN 提取特徵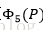

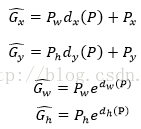
3.6.5 Faster R-CNN中的bounding box迴歸
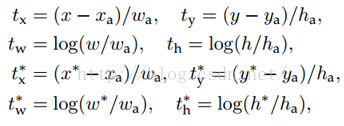
其中:

※注意:計算regression loss需要三組資訊:
1) 預測框,即RPN網路測出的proposa;
2) 錨點anchor box:之前的9個anchor對應9個不同尺度和長寬比的anchorbox;
3) GroundTruth:標定的框。
3.7 訓練RPNs
RPN通過反向傳播(BP,back-propagation)和隨機梯度下降(SGD,stochastic gradient descent)進行端到端(end-to-end)訓練。依照FastR-CNN中的“image-centric”取樣策略訓練這個網路。每個mini-batch由包含了許多正負樣本的單個影象組成。我們可以優化所有anchor的損失函式,但是這會偏向於負樣本,因為它們是主要的。
取樣
每一個mini-batch包含從一張影象中隨機提取的256個anchor(注意,不是所有的anchor都用來訓練),前景樣本和背景樣本均取128個,達到正負比例為1:1。如果一個影象中的正樣本數小於128,則多用一些負樣本以滿足有256個Proposal可以用於訓練。
初始化
新增的2層引數用均值為0,標準差為0.01的高斯分佈來進行初始化,其餘層(都是共享的卷積層,與VGG共有的層)引數用ImageNet分類預訓練模型來初始化。
引數化設定(使用caffe實現)
在PASCAL資料集上:
前60k個mini-batch進行迭代,學習率設為0.001;
後20k個mini-batch進行迭代,學習率設為0.0001;
設定動量momentum=0.9,權重衰減weightdecay=0.0005。

3.8 非極大值抑制法

訓練時(eg:輸入600*1000的影象),如果anchor box的邊界超過了影象邊界,那這樣的anchors對訓練loss也不會產生影響,我們將超過邊界的anchor捨棄不用。一幅600*1000的影象經過VGG16後大約為40*60,則此時的anchor數為40*60*9,約為20k個anchor boxes,再去除與邊界相交的anchor boxes後,剩下約為6k個anchor boxes,這麼多數量的anchorboxes之間肯定是有很多重疊區域,因此需要使用非極大值抑制法(NMS,non-maximum suppression)將IoU>0.7的區域全部合併,最後就剩下約2k個anchor boxes(同理,在最終檢測端,可以設定將概率大約某閾值P且IoU大約某閾值T的預測框採用NMS方法進行合併,注意:這裡的預測框指的不是anchor boxes)。NMS不會影響最終的檢測準確率,但是大幅地減少了建議框的數量。NMS之後,我們用建議區域中的top-N個來檢測(即排過序後取N個)。
3.9 RPN與Fast R-CNN特徵共享
Faster-R-CNN演算法由兩大模組組成:
1.PRN候選框提取模組;
2.Fast R-CNN檢測模組。
我們已經描述瞭如何為生成區域建議訓練網路,而沒有考慮基於區域的目標檢測CNN如何利用這些建議框。對於檢測網路,我們採用Fast R-CNN,現在描述一種演算法,學習由RPN和Fast R-CNN之間共享的卷積層。
RPN和Fast R-CNN都是獨立訓練的,要用不同方式修改它們的卷積層。因此需要開發一種允許兩個網路間共享卷積層的技術,而不是分別學習兩個網路。注意到這不是僅僅定義一個包含了RPN和Fast R-CNN的單獨網路,然後用反向傳播聯合優化它那麼簡單。原因是Fast R-CNN訓練依賴於固定的目標建議框,而且並不清楚當同時改變建議機制時,學習Fast R-CNN會不會收斂。
RPN在提取得到proposals後,作者選擇使用Fast-R-CNN實現最終目標的檢測和識別。RPN和Fast-R-CNN共用了13個VGG的卷積層,顯然將這兩個網路完全孤立訓練不是明智的選擇,作者採用交替訓練(Alternating training)階段卷積層特徵共享:
第一步,我們依上述訓練RPN,該網路用ImageNet預訓練的模型初始化,並端到端微調用於區域建議任務;
第二步,我們利用第一步的RPN生成的建議框,由Fast R-CNN訓練一個單獨的檢測網路,這個檢測網路同樣是由ImageNet預訓練的模型初始化的,這時候兩個網路還沒有共享卷積層;
第三步,我們用檢測網路初始化RPN訓練,但我們固定共享的卷積層,並且只微調RPN獨有的層,現在兩個網路共享卷積層了;
第四步,保持共享的卷積層固定,微調Fast R-CNN的fc層。這樣,兩個網路共享相同的卷積層,構成一個統一的網路。
注意:第一次迭代時,用ImageNet得到的模型初始化RPN和Fast-R-CNN中卷積層的引數;從第二次迭代開始,訓練RPN時,用Fast-R-CNN的共享卷積層引數初始化RPN中的共享卷積層引數,然後只Fine-tune不共享的卷積層和其他層的相應引數。訓練Fast-RCNN時,保持其與RPN共享的卷積層引數不變,只Fine-tune不共享的層對應的引數。這樣就可以實現兩個網路卷積層特徵共享訓練。相應的網路模型請參考https://github.com/rbgirshick/py-faster-rcnn/tree/master/models/pascal_voc/VGG16/faster_rcnn_alt_opt
圖1 IoU定義
Region Proposal方法比傳統的滑動視窗方法獲取的質量要更高。比較常用的Region Proposal方法有:SelectiveSearch(SS,選擇性搜尋)、Edge Boxes(EB)。
基於Region Proposal目標檢測演算法的步驟如下:
其中:
CNN方法見http://blog.csdn.net/qq_17448289/article/details/52850223。
邊框迴歸(Bouding Box Regression):是對RegionProposal進行糾正的線性迴歸演算法,目的是為了讓Region Proposal提取到的視窗與目標視窗(Ground Truth)更加吻合。
二、R-CNN、Fast R-CNN、Faster R-CNN三者關係
圖2 三者關係
表1 三者比較
|
|
使用方法 |
缺點 |
改進 |
| R-CNN (Region-based Convolutional Neural Networks) |
1、SS提取RP; 2、CNN提取特徵; 3、SVM分類; 4、BB盒迴歸。 |
1、 訓練步驟繁瑣(微調網路+訓練SVM+訓練bbox); 2、 訓練、測試均速度慢 ; 3、 訓練佔空間 |
1、 從DPM HSC的34.3%直接提升到了66%(mAP); 2、 引入RP+CNN |
| Fast R-CNN (Fast Region-based Convolutional Neural Networks) |
1、SS提取RP; 2、CNN提取特徵; 3、softmax分類; 4、多工損失函式邊框迴歸。 |
1、 依舊用SS提取RP(耗時2-3s,特徵提取耗時0.32s); 2、 無法滿足實時應用,沒有真正實現端到端訓練測試; 3、 利用了GPU,但是區域建議方法是在CPU上實現的。 |
1、 由66.9%提升到70%; 2、 每張影象耗時約為3s。 |
| Faster R-CNN (Fast Region-based Convolutional Neural Networks) |
1、RPN提取RP; 2、CNN提取特徵; 3、softmax分類; 4、多工損失函式邊框迴歸。 |
1、 還是無法達到實時檢測目標; 2、 獲取region proposal,再對每個proposal分類計算量還是比較大。 |
1、 提高了檢測精度和速度; 2、 真正實現端到端的目標檢測框架; 3、 生成建議框僅需約10ms。 |
2.1 R-CNN目標檢測流程介紹
具體可參考http://blog.csdn.net/shenxiaolu1984/article/details/51066975
2.2 Fast R-CNN目標檢測流程介紹
注意:Fast R-CNN的RegionProposal是在feature map之後做的,這樣可以不用對所有的區域進行單獨的CNN Forward步驟。
Fast R-CNN框架如下圖:
圖3 Fast R-CNN框架
Fast R-CNN框架與R-CNN有兩處不同:
① 最後一個卷積層後加了一個ROI pooling layer;
② 損失函式使用了multi-task loss(多工損失)函式,將邊框迴歸直接加到CNN網路中訓練。分類Fast R-CNN直接用softmax替代R-CNN用的SVM進行分類。
Fast R-CNN是端到端(end-to-end)的。
具體可參考http://blog.csdn.net/shenxiaolu1984/article/details/51036677
三、Faster R-CNN目標檢測
3.1 Faster R-CNN的思想
Faster R-CNN可以簡單地看做“區域生成網路RPNs + Fast R-CNN”的系統,用區域生成網路代替FastR-CNN中的Selective Search方法。Faster R-CNN這篇論文著重解決了這個系統中的三個問題:
1. 如何設計區域生成網路;
2. 如何訓練區域生成網路;
3. 如何讓區域生成網路和Fast RCNN網路共享特徵提取網路。
在整個Faster R-CNN演算法中,有三種尺度:
1. 原圖尺度:原始輸入的大小。不受任何限制,不影響效能。
2. 歸一化尺度:輸入特徵提取網路的大小,在測試時設定,原始碼中opts.test_scale=600。anchor在這個尺度上設定。這個引數和anchor的相對大小決定了想要檢測的目標範圍。
3. 網路輸入尺度:輸入特徵檢測網路的大小,在訓練時設定,原始碼中為224*224。
3.2 Faster R-CNN框架介紹
圖4 Faster R-CNN模型
Faster-R-CNN演算法由兩大模組組成:
1.PRN候選框提取模組;
2.Fast R-CNN檢測模組。
其中,RPN是全卷積神經網路,用於提取候選框;Fast R-CNN基於RPN提取的proposal檢測並識別proposal中的目標。
3.3 RPN介紹
3.3.1背景
目前最先進的目標檢測網路需要先用區域建議演算法推測目標位置,像SPPnet和Fast R-CNN這些網路雖然已經減少了檢測網路執行的時間,但是計算區域建議依然耗時較大。所以,在這樣的瓶頸下,RBG和Kaiming He一幫人將Region Proposal也交給CNN來做,這才提出了RPN(Region Proposal Network)區域建議網路用來提取檢測區域,它能和整個檢測網路共享全圖的卷積特徵,使得區域建議幾乎不花時間。
RCNN解決的是,“為什麼不用CNN做classification呢?”
Fast R-CNN解決的是,“為什麼不一起輸出bounding box和label呢?”
Faster R-CNN解決的是,“為什麼還要用selective search呢?”
3.3.2RPN核心思想
RPN的核心思想是使用CNN卷積神經網路直接產生Region Proposal,使用的方法本質上就是滑動視窗(只需在最後的卷積層上滑動一遍),因為anchor機制和邊框迴歸可以得到多尺度多長寬比的Region Proposal。
RPN網路也是全卷積網路(FCN,fully-convolutional network),可以針對生成檢測建議框的任務端到端地訓練,能夠同時預測出object的邊界和分數。只是在CNN上額外增加了2個卷積層(全卷積層cls和reg)。
①將每個特徵圖的位置編碼成一個特徵向量(256dfor ZF and 512d for VGG)。
②對每一個位置輸出一個objectness score和regressedbounds for k個region proposal,即在每個卷積對映位置輸出這個位置上多種尺度(3種)和長寬比(3種)的k個(3*3=9)區域建議的物體得分和迴歸邊界。
RPN網路的輸入可以是任意大小(但還是有最小解析度要求的,例如VGG是228*228)的圖片。如果用VGG16進行特徵提取,那麼RPN網路的組成形式可以表示為VGG16+RPN。
VGG16:參考
https://github.com/rbgirshick/py-faster-rcnn/blob/master/models/pascal_voc/VGG16/faster_rcnn_end2end/train.prototxt,可以看出VGG16中用於特徵提取的部分是13個卷積層(conv1_1---->conv5.3),不包括pool5及pool5後的網路層次結構。
因為我們的最終目標是和Fast R-CNN目標檢測網路共享計算,所以假設這兩個網路共享一系列卷積層。在論文的實驗中,ZF有5個可共享的卷積層, VGG有13個可共享的卷積層。
RPN的具體流程如下:使用一個小網路在最後卷積得到的特徵圖上進行滑動掃描,這個滑動網路每次與特徵圖上n*n(論文中n=3)的視窗全連線(影象的有效感受野很大,ZF是171畫素,VGG是228畫素),然後對映到一個低維向量(256d for ZF / 512d for VGG),最後將這個低維向量送入到兩個全連線層,即bbox迴歸層(reg)和box分類層(cls)。sliding window的處理方式保證reg-layer和cls-layer關聯了conv5-3的全部特徵空間。
reg層:預測proposal的anchor對應的proposal的(x,y,w,h)
cls層:判斷該proposal是前景(object)還是背景(non-object)。
圖5 RPN框架
在圖5中,要注意,3*3卷積核的中心點對應原圖(re-scale,原始碼設定re-scale為600*1000)上的位置(點),將該點作為anchor的中心點,在原圖中框出多尺度、多種長寬比的anchors。所以,anchor不在conv特徵圖上,而在原圖上。
圖6 9種anchor(注意:是不同位置)
圖7 Faster R-CNN卷積流程圖
原圖600*1000經CNN卷積後,在CNN最後一層(conv5)得出的是40*60大小的特徵圖,對應文中說的典型值為2400。若特徵圖大小為W*H,則需要W*H*K個anchor,本文中需要40*60*9≈2k個。
在RPN網路中,我們需要重點理解其中的anchors概念,Loss fucntions計算方式和RPN層訓練資料生成的具體細節。
3.4 RPN的平移不變性
在計算機視覺中的一個挑戰就是平移不變性:比如人臉識別任務中,小的人臉(24*24的解析度)和大的人臉(1080*720)如何在同一個訓練好權值的網路中都能正確識別。若是平移了影象中的目標,則建議框也應該平移,也應該能用同樣的函式預測建議框。
傳統有兩種主流的解決方式:
第一、對影象或feature map層進行尺度\寬高的取樣;
第二、對濾波器進行尺度\寬高的取樣(或可以認為是滑動視窗).
但Faster R-CNN解決該問題的具體實現是:通過卷積核中心(用來生成推薦視窗的Anchor)進行尺度、寬高比的取樣,使用3種尺度和3種比例來產生9種anchor。
3.5 視窗分類和位置精修
分類層(cls_score)輸出每一個位置上,9個anchor屬於前景和背景的概率。
視窗迴歸層(bbox_pred)輸出每一個位置上,9個anchor對應視窗應該平移縮放的引數(x,y,w,h)。
對於每一個位置來說,分類層從256維特徵中輸出屬於前景和背景的概率;視窗迴歸層從256維特徵中輸出4個平移縮放參數。
需要注意的是:並沒有顯式地提取任何候選視窗,完全使用網路自身完成判斷和修正。
3.6 學習區域建議損失函式
3.6.1 標籤分類規定
為了訓練RPN,需要給每個anchor分配的類標籤{目標、非目標}。對於positive label(正標籤),論文中給瞭如下規定(滿足以下條件之一即可判為正標籤):
注意,一個GT包圍盒可以對應多個anchor,這樣一個GT包圍盒就可以有多個正標籤。
事實上,採用第②個規則基本上可以找到足夠的正樣本,但是對於一些極端情況,例如所有的Anchor對應的anchor box與groud truth的IoU不大於0.7,可以採用第一種規則生成。
negative label(負標籤):與所有GT包圍盒的IoU都小於0.3的anchor。
對於既不是正標籤也不是負標籤的anchor,以及跨越影象邊界的anchor我們給予捨棄,因為其對訓練目標是沒有任何作用的。
3.6.2 多工損失(來自Fast R-CNN)
圖8 multi-task資料結構
Fast R-CNN網路有兩個同級輸出層(cls score和bbox_prdict層),都是全連線層,稱為multi-task。
① clsscore層:用於分類,輸出k+1維陣列p,表示屬於k類和背景的概率。對每個RoI(Region of Interesting)輸出離散型概率分佈
通常,p由k+1類的全連線層利用softmax計算得出。
② bbox_prdict層:用於調整候選區域位置,輸出bounding box迴歸的位移,輸出4*K維陣列t,表示分別屬於k類時,應該平移縮放的引數。
k表示類別的索引,
loss_cls層評估分類損失函式。由真實分類u對應的概率決定:
loss_bbox評估檢測框定位的損失函式。比較真實分類對應的預測平移縮放參數
真實平移縮放參數為
其中,smooth L1損失函式為:
smooth L1損失函式曲線如下圖9所示,作者這樣設定的目的是想讓loss對於離群點更加魯棒,相比於L2損失函式,其對離群點、異常值(outlier)不敏感,可控制梯度的量級使訓練時不容易跑飛。
圖9 smoothL1損失函式曲線
最後總損失為(兩者加權和,如果分類為背景則不考慮定位損失):
規定u=0為背景類(也就是負標籤),那麼艾弗森括號指數函式[u≥1]表示背景候選區域即負樣本不參與迴歸損失,不需要對候選區域進行迴歸操作。λ控制分類損失和迴歸損失的平衡。Fast R-CNN論文中,所有實驗λ=1。
艾弗森括號指數函式為:
原始碼中bbox_loss_weights用於標記每一個bbox是否屬於某一個類。
3.6.3 Faster R-CNN損失函式
遵循multi-task loss定義,最小化目標函式,FasterR-CNN中對一個影象的函式定義為:
其中:
3.6.4 R-CNN中的boundingbox迴歸
下面先介紹R-CNN和Fast R-CNN中所用到的邊框迴歸方法。
1. 為什麼要做Bounding-box regression?
圖10 示例
如圖10所示,綠色的框為飛機的Ground Truth,紅色的框是提取的Region Proposal。那麼即便紅色的框被分類器識別為飛機,但是由於紅色的框定位不準(IoU<0.5),那麼這張圖相當於沒有正確的檢測出飛機。如果我們能對紅色的框進行微調,使得經過微調後的視窗跟Ground Truth更接近,這樣豈不是定位會更準確。確實,Bounding-box regression 就是用來微調這個視窗的。
2. 迴歸/微調的物件是什麼?
3. Bounding-box regression(邊框迴歸)
那麼經過何種變換才能從圖11中的視窗P變為視窗呢?比較簡單的思路就是:
注意:只有當Proposal和Ground Truth比較接近時(線性問題),我們才能將其作為訓練樣本訓練我們的線性迴歸模型,否則會導致訓練的迴歸模型不work(當Proposal跟GT離得較遠,就是複雜的非線性問題了,此時用線性迴歸建模顯然不合理)。這個也是G-CNN: an Iterative Grid Based Object Detector多次迭代實現目標準確定位的關鍵。
線性迴歸就是給定輸入的特徵向量X,學習一組引數W,使得經過線性迴歸後的值跟真