
Just Do It!
1. 概述
微服務:
2014 年可以認為是微服務 1.0 的元年,當年有幾個標誌性事件,一是 Martin Fowler 在其部落格上發表了”Microservices”一文,正式提出微服務架構風格;二是 Netflix 微服務架構經過多年大規模生產驗證,最終抽象落地形成一整套開源的微服務基礎元件,統稱 NetflixOSS,Netflix 的成功經驗開始被業界認可並推崇;三是 Pivotal 將 NetflixOSS 開源微服務元件整合到其 Spring 體系,推出 Spring Cloud 微服務開發技術棧。
一晃三年過去,微服務技術生態又發生了巨大變化,容器,PaaS,Cloud Native,gRPC,ServiceMesh,Serverless 等新技術新理念你方唱罷我登場,不知不覺我們又來到了微服務 2.0 時代。

2. 架構及技術棧

微服務的三種架構模式:
2.1 鏈式模式
業務需要微服務之間是同步呼叫關係,服務1呼叫服務2,在服務2完成後,返回結果給服務1,然後返回gateway,返回請求方。
在實際業務場景中,涉及到交易和訂單的業務場景都會用到這種模式。
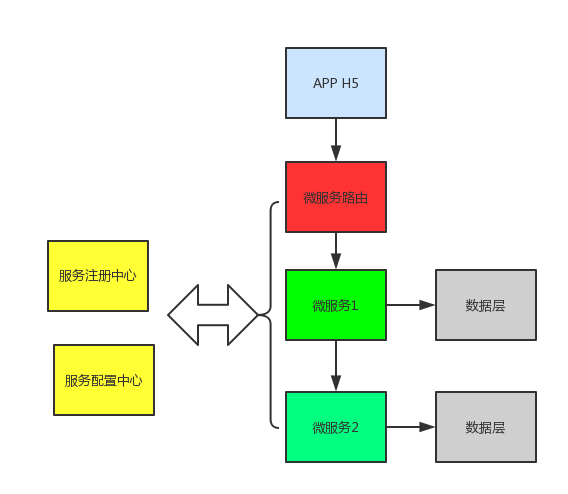
2.2 聚合模式
服務之前沒有依賴關係,不需要同步呼叫,各個微服務執行完成後,聚合層進行某些過濾或者合併計算,然後返回gateway,最終返回呼叫方。
2.3 非同步訊息模式
無論是鏈式模式,還是聚合模式,一個請求都需要處理完成後才能返回,如果一個請求不關心返回結果,為了提高系統吞吐量,可以採用非同步訊息模式,流程圖如下:

3.分散式事務
微服務模組比較分散、資料也比較分散,整個系統複雜性非常高,如何進行資料一致性實踐?在一個單體模組裡面可以做Local Transaction,但是在微服務體系裡面就不奏效。雖然難解決,但是不能不解決,不解決的話微服務架構就很難實施。我們知道微服務中做強一致性
我們的業務場景無非是兩種:第一種是非同步呼叫,就是一個請求過來就寫到訊息佇列裡面就行,這種模式相對簡單。今天主要講下同步呼叫的場景之下怎麼打造資料的最終一致性。既然是同步呼叫場景,並且不能降低業務系統的吞吐量,那麼應該怎麼做呢?建立一個非同步的分散式事務,業務呼叫失敗後,通過非同步方式來補償業務。我們的想法是能不能在整個業務邏輯層實現分散式事務語義策略?如何實現,無非有兩種,第一是在調正常請求的時候要記錄業務呼叫鏈(呼叫正常介面的完整引數),第二是異常時沿呼叫鏈反向補償。
非同步呼叫,存入MQ,然後
基於這個思路,我們架構設計上的關鍵點有三,第一是基於補償機制,第二是記錄呼叫鏈,第三是提供冪等補償介面。架構層面,看下圖,右邊是聚合器架構設計模式,左邊是非同步補償服務。
思路一:
分散式事務是多次提交,比如下訂單,需要扣減庫存,優惠券扣減等操作,如果下單失敗,需要回滾,補充庫存以及優惠券。
庫存和優惠券,訂單服務都是獨立的service。
我的設計思路是,多次提交利用快取儲存的flag判斷本次事務處理是否完成,比如提交訂單,先扣減庫存,庫存扣減完成後,設定flag為1,然後進行優惠券扣減,同理,成功則設定flag為2,繼續提交訂單流程。整個流程結束。
如果某個service處理失敗,比如庫存扣減完成後,設定flag為true,但是優惠券扣減失敗,則flag仍未1.
這種思路,每個servie執行邏輯前需要check flag是否是當前servie的step,如果是,說明前面的service執行都成功了,如果不是則,有失敗的service。如何回滾呢?我的思路欠缺的時候回滾方式。需要儲存成功的service的執行引數,以便於回滾。
思路二:

首先需要在聚合層引入一個Proxy。首先基於方法,在方法名加註解標註補償方法名,比如:- @Compensable(cancelMethod=“cancelRecord”)
另外,聚合層在呼叫原子層之前,通過代理記錄當前呼叫請求引數。如果業務正常,呼叫結束後,當前方法的呼叫記錄存檔或刪除,如果業務異常,查詢呼叫鏈回滾。
原子層我們做了哪些事情呢?主要是兩方面,第一是提供正常的原子介面,其次是提供補償冪等介面。

分散式事務關鍵是兩個表(如上圖),第一是事務組表,假設A->B->C三個請求是一個事務,首先針對ABC生成一個事務的ID,寫在這個表裡面,並且會記錄這個事務的狀態,預設的情況下正常的,執行失敗以後我們再把狀態由1(正常)變成2(異常);第二個表是事務呼叫組表,主要記錄事務組內的每一次呼叫以及相關引數,所以呼叫原子層之前需要記錄一下請求引數。如果失敗的話我們需要把這個事務的狀態由1變成2;第三,一旦狀態從1變成2就執行補償服務。這是我們的補償邏輯,就是不斷地掃描這個事務所處的表,比如一秒鐘掃一次事務組表,看一看這個表裡面有沒有狀態為2的,需要執行補償的服務。這個思路對業務的侵入比較小。
具體看下我們實際的例子,比如二手交易平臺裡面建立訂單事務組的正常流程,從鎖庫存到減紅包再到建立訂單,建立事務組完畢之後開始呼叫業務,首先Proxy記錄鎖庫存呼叫的引數,之後開始鎖庫存服務呼叫,成功後之後又開始減紅包和建立訂單過程,如果都成功了直接返回。

再看一下異常的流程,前面幾步都是一樣的,只是在調紅包服務、Proxy建立紅包的時候如果失敗了就會丟擲異常,業務正常返回,聚合層Proxy需要把事務組的狀態由1改成2,這個時候由左邊的補償服務非同步地補償呼叫

分散式事務引自:
http://www.techweb.com.cn/network/system/2017-07-12/2555992.shtml