
Python爬蟲入門(一)
Python爬蟲入門(一)
1.適配環境
note:部分神舟筆記本bios預設開啟virtualization technology,可以用工作管理員確認
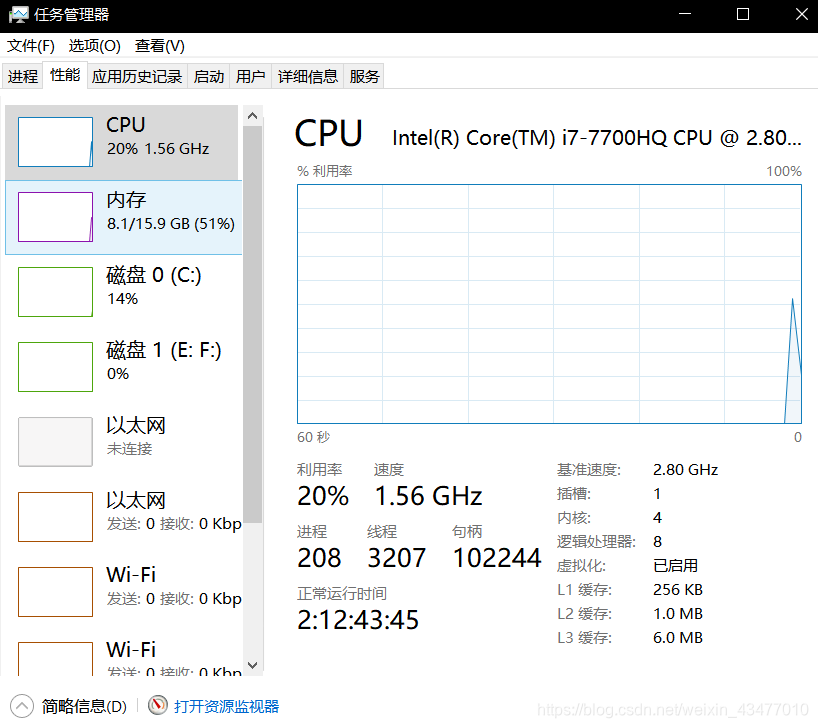
virtualbox
ubuntu18
vim
python3.6
1.1.ubuntu入門
sudo 給許可權
ls 返回當前目錄下的所有檔案的名稱,返回詳細資訊用ll
apt-get install/remove xxx 下載或刪除xxx
mkdir 建立資料夾
pwd 返回當前目錄
mv move檔案到另一個檔案中 mv spder.py test/
find find . -name spider.py查詢名為 spider.py的檔案,find ./test/ -name spider.py就是隻對test目錄下查詢
| rm | |
|---|---|
| rm -f | 強制刪除檔案 |
| rm -rf | 刪除資料夾 |
對爬蟲有幫助
ps檢視程序
ps a看到所有程序
ps aux | grep vscode檢視vscode的程序,可以用返回的編號,使用kill 編號,刪除。
grep -r re ./test在test文件中搜索檔案中有re字樣的,返回./test/spider.py import re
git clone xxxx.git 複製程式碼到本地
git pull對程式碼進行更新
1.2 vim入門
在非編輯介面輸入:
:wq表示寫入並退出,:q!強制退出,:set number顯示行數。:數字游標跳到指定數字行,:gg跳到第一行, :GG跳到最後一行
h左,j下,k上,l右
在非編輯介面下,按a進入編輯模式,按i進入insert的編輯模式,o表示進入並自動加一個換行。
非編輯模式下按dd,刪除游標所在行,按u撤回指令,按x刪除一個位元組。
文字內複製 1,10 co 16 把1到10行復制到16。用m代替co就是剪下過去
按住shift+insert將剪下板的東西複製到vim中
2.HTML


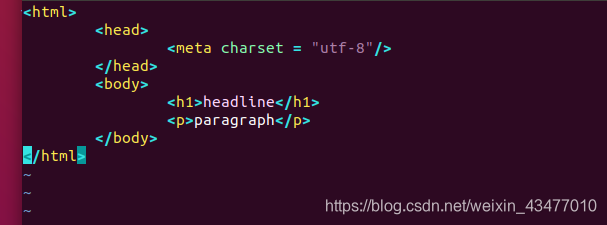
<html>是開頭,</html>是結束,其中的其他開閉和標籤為其的子集
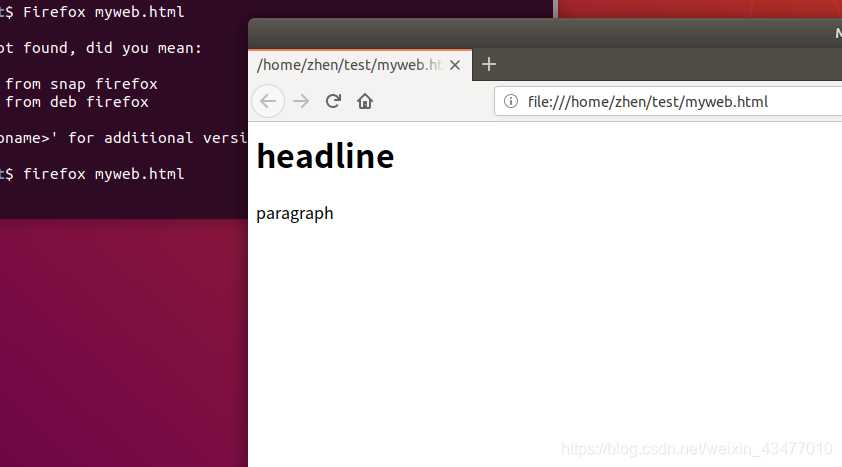
試驗一下,可用火狐開啟
| <a href=“http://www.baidu.com”>百度</a> | 超連結 |
|---|---|
| <title>xx</title> | 網頁標題 |
| <h1>xx</h1> | 標題1 |
| <p> xx</p> | 段落內容 |
| <img src=“www.xxx.com/x.jpg”/> | 圖片 |
{kind=link}
<!DOCTYPE html>表示文件型別宣告,它的目的是要告訴標準通用標記語言解析器,它應該使用什麼樣的文件型別定義(DTD)來解析文件。
2.1連結標籤
頁內跳轉和javascrpt的響應

2.2 table標籤
方便記憶
tr-table row
th-table head
td-table data
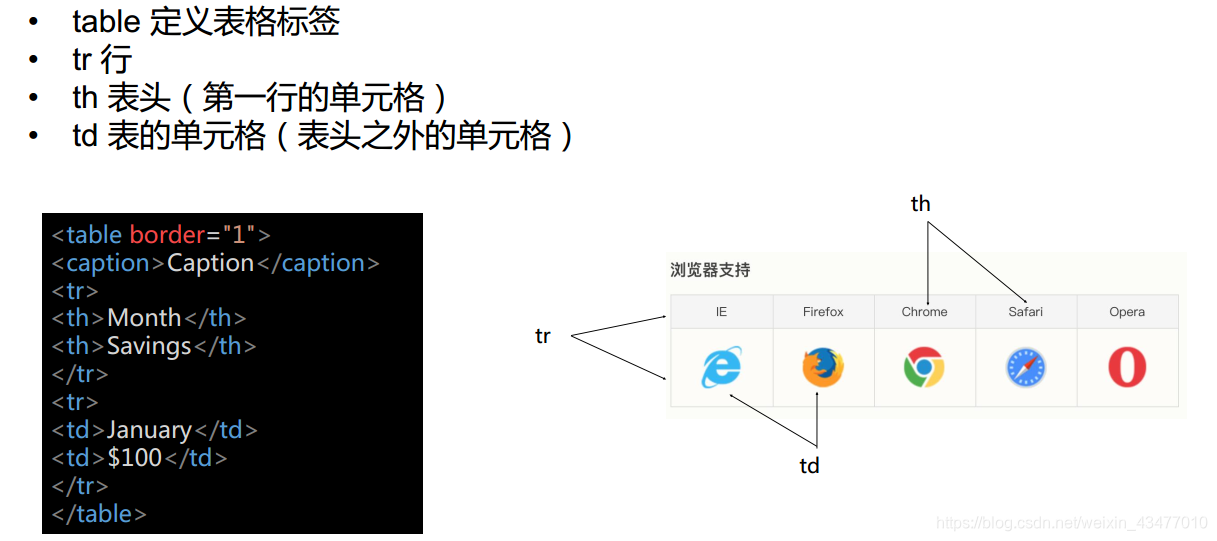
其中boder表示表格邊框,caption是大標題
<table>
<captioon> 表格標題</captioon>
<tr> #按行輸入,第一行為table head
<th> head1 </th>
<th> head2 </th>
</tr> # 由table head組成的第一行鍵入完畢
<tr> #按行輸入,鍵入的為td,即單元格內容
<td> data1</td>
<td> data1</td>
</tr> # 由td組成的第二行鍵入完畢
......
</table>

2.3 DOM屬性
給標題h1中加入一個a標籤,帶name屬性,值為turnmoil,則可用超鏈跳至此處


常見的屬性由這幾種。

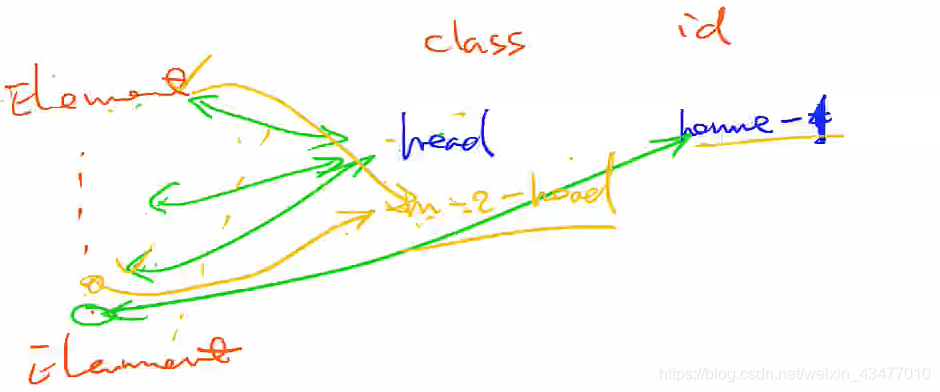
由一個class可以找到一組elements,而id只對應一個element
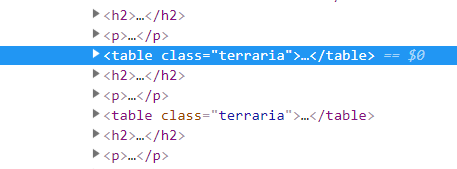
查詢是否有同樣的標籤出現在網頁,右鍵檢查,點進console,鍵入document.get(用tab補全)
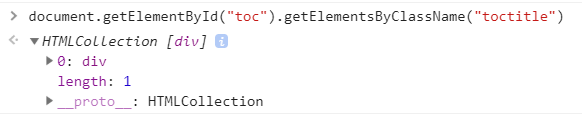
這是按照class的名字來檢索的,當然也可以使用tag的名字,用的是document.getElementsByTagName
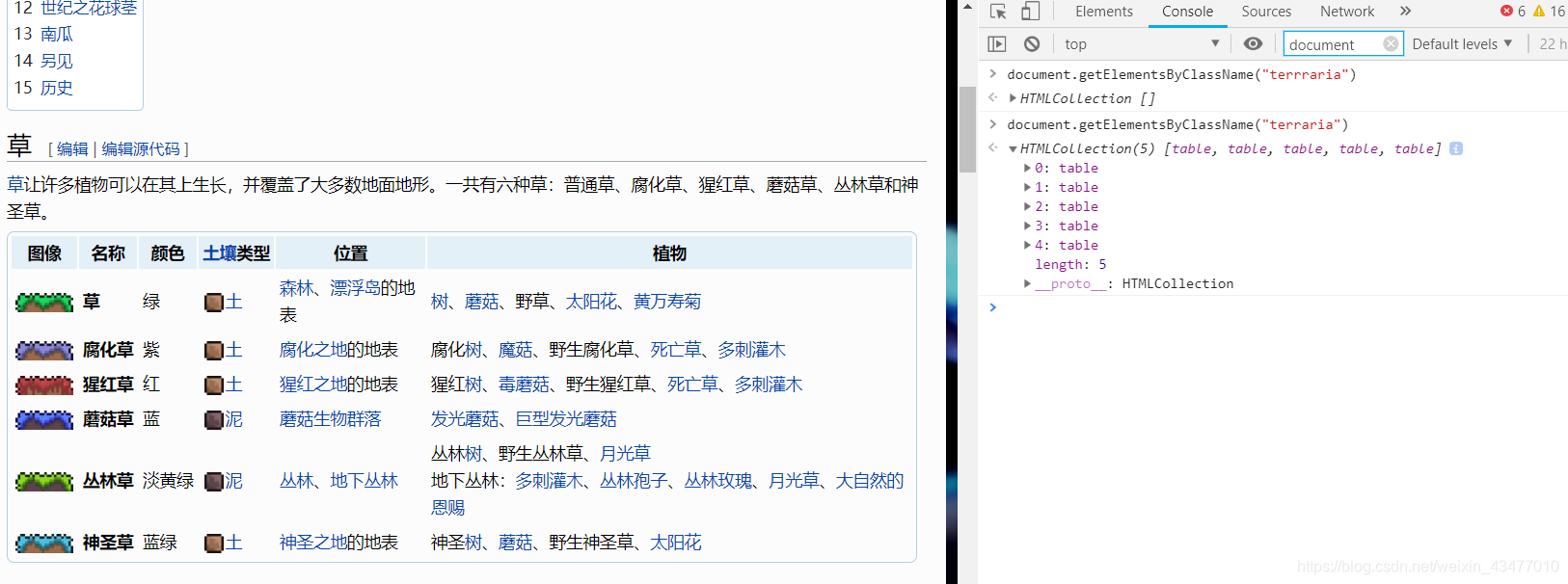
更進一步的查詢

2.4 CSS
style屬性

加上style屬性,直接更改外觀樣式。

若要全部都修改,可以用外嵌的方法,先給需要修改的地方加一個class名,再以此建一個css檔案,放在在開頭,則所有相關的地方都被修改了。此處.main-content就是選擇所有class="main-content"的元素的意思。關於更多css選擇器,可以看CSS選擇器。



3.第一個爬蟲
3.1 requests包初探

試試爬一下本篇文章~

成功了,在一堆字元中找到本篇文章
requests.get返回一個類,裡面一個屬性就是status_code,返回為200,表示爬取成功。

若返回的是json格式的,用resp.json()即可(resp是requests.get賦值的變數),就轉為了字典格式。
成功呼叫 .json() 並不完全意味著響應的成功。有的伺服器會在失敗的響應中包含一個 JSON 物件(比如 HTTP 500 的錯誤細節)。這種 JSON 會被解碼返回。要檢查請求是否成功,請檢查.status_code的值是否和你的期望相同。
resp.encoding是編碼,本文返回的是UTF-8
看來是正確的。
讓爬蟲更像人類,需要設定headers,
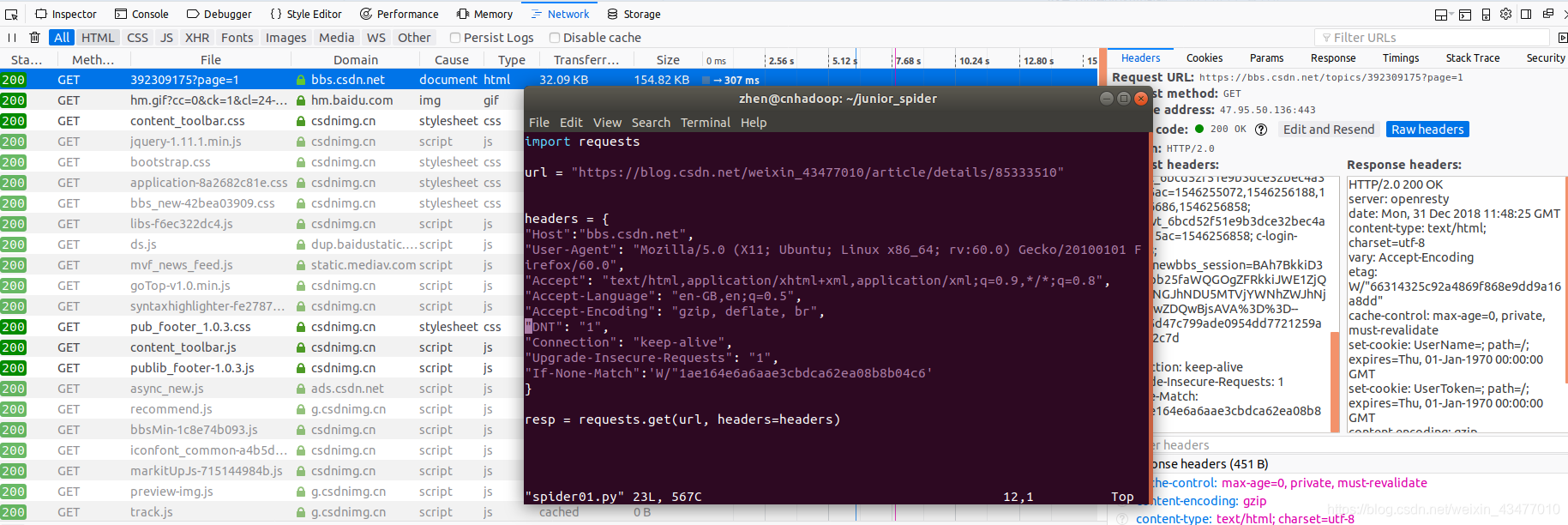
若直接複製會出現報錯,UnicodeEncodeError: 'latin-1' codec can't encode character '\u2026' in position 30,則是因為直接對header進行復制,應該要點開再複製,因為user-agent太長,中間可能會省略了

注意是要的request header,而不是response header,而且諸如Postman-token, If-Modified-Since 的內容要去掉,本次把cookie也拿掉了。此外,用resp.headers可以返回請求頭
3.2 字元編碼和檔案讀寫
但是如果encoding發生錯誤,會導致亂碼。這裡的新浪文字應該是utf-8,但是requests包把它當成了iso8859-1的編碼(多為西歐語系在用,字元少,而中文字元多,不適合),這裡open中的"w+",可參見link:
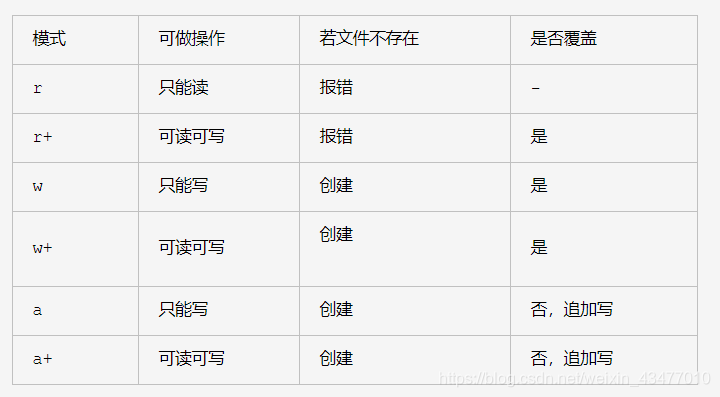
若後面不加b,則說明以字串方式(unicode)開啟

比如這裡,需要用ab來開啟。比如網上下載圖片儲存,就要用b,因為是二進位制的不是字串。
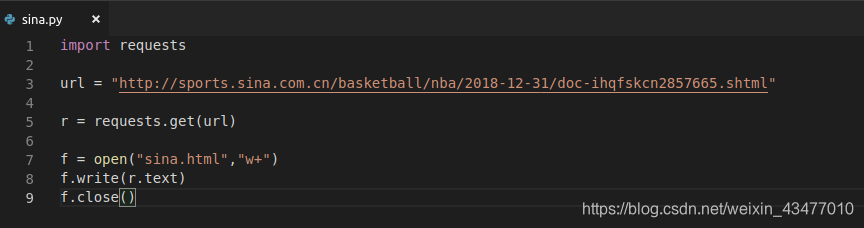

編碼不同,讀出來的內容也就不同。

一些編碼相關的知識:

UTF-8可以1到7個位元組

py2.7轉unicode可以直接u"你好"

str—>(encode)—>bytes,bytes—>(decode)—>str,decode的作用是將其他編碼的字串轉換成unicode編碼,encode的作用是將unicode編碼轉換成其他編碼的字串。
在linux系統下,執行如下程式碼 len(“你好python”) 輸出結果正確的是:
Python2.7下中文字串預設是utf-8編碼。
utf-8編碼的一箇中文佔3個位元組,2箇中文是6個位元組,加6個英文字母,輸出結果是12
Python3.6下字串預設是Unicode字元編碼, 2個漢字字元加6個英文字元,輸出結果是 8
我們加入encoding,得到的網頁就是utf-8了。但是返回r.content就不行,因為是encoding不改變content只改變text,所以是位元組流(python提示為bytes,而python中的str格式為unicode),要用wb讀寫。
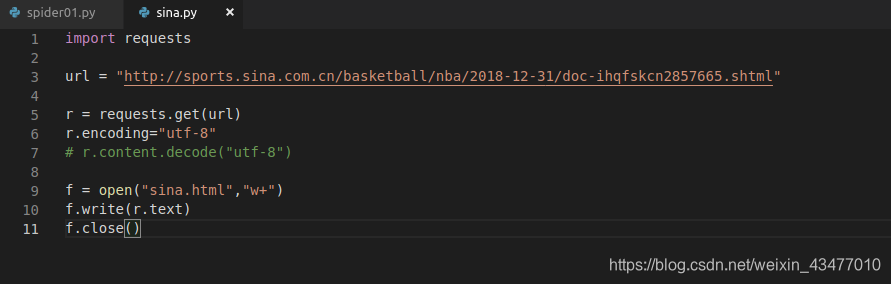
3.3 爬取檔案的命名
直接命名法
如果爬取整個網站,可能會出現同名的情況,所以命名是很重要的
比如新浪的網頁,有一個時間2018-12-31的文件,所以doc-ihqfskcn2857665是不是唯一的,我們不知道。
http://sports.sina.com.cn/basketball/nba/2018-12-31/doc-ihqfskcn2857665.shtml
而馬蜂窩網站的遊記,是直接用一串數字代表,應該就是唯一的
https://www.mafengwo.cn/i/11505790.html
其中,http為協議(也可能為https,ftp和file),www.mafengwo.cn為域名,也叫domain;而basketball/nba/2018-12-31為路徑,path;最後的doc-ihqfskcn2857665為網頁的名字。我們可以用字串的內建函式rfind來找(也就是從右邊開始搜尋,找到右邊第一個/的下一個字元到結尾的index,直接冒號後面不加東西也是可以的)

得到:

獲得domain:
start_pos = url.find("//")+2
end_pos = url.find("/", start_pos)
domain = url[start_pos: start_end]
filename = domain + "_" + filename # 這裡的filename也就是之前的url[url.rfind("/")+1:]
可能會在尾部一個?,其後面跟著一個引數,可能是瀏覽器資訊或跳轉資訊,如果留著可能造成爬取網頁重複(ref, usr等引數,比如https://baike.baidu.com/item/百科/29?fr=aladdin,去掉?fr=aladdin對內容沒影響),也可能是用來指明網頁的引數(如https://www.youtube.com/watch?v=w3eOMmTjCOQ&index=8&list=PLUM8x224JrX-4MT-9Fp5omT_r5nazCurz),所以不一定都能刪除,可以自己刪除看看會不會對網頁內容有影響。但大多數情況下對內容沒影響,簡單的處理方法就是直接刪除url[url.find("?")]。
MD5命名
也就是用連線的hash值直接對檔案命名。每個文字的變化都會讓md5發生明顯變化。另外md5可能會重名,只是概率特別小。在ubuntu中,可以用md5sum 檔名,來查詢檔案的md5值

我們可以使用hashlib包來搞定,方法如下:
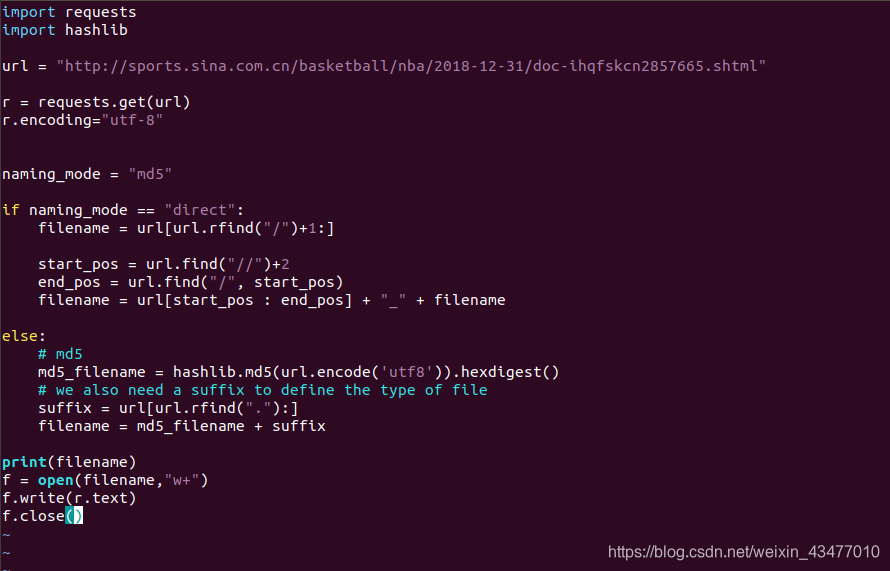
列印:

如果我們使用md5的方法,我們在url的資訊就丟失了,比如一些分類資訊和url的路徑有關,這時我們用資料庫儲存這些資訊。
我們也能用時間戳來命名,但是要用小的時間,比如毫秒。
百度的消歧義方法:同名的底下再加一個引數在後面

3.4 with語法
可以用函式with來省略close的步驟。
with open(filename, "w") as f:
f.write(resp.text)
實質就是

上下文管理協議,即with語句,為了讓一個物件相容with語句,必須在這個物件的類中宣告__enter__和__exit__方法

with a() as b, 用_enter_的返回值給a賦值,當with下的語句結束後,呼叫_exit_方法

給個例子

先執行__init__做初始化,
再根據with語法:
先執行__enter__
再執行do_something
最後無論有無異常出現都必須執行__exit__