
自然語言處理 學習筆記(三)
個人學習nlp筆記:學習材料CS124、COSC572和《Speech and Language Processing》第三版

自然語言處理 學習筆記(三)
- 1.樸素貝葉斯
- 1.1 樸素貝葉斯推導
- 1.2 樸素貝葉斯訓練
- 1.3樸素貝葉斯和語言模型
- 1.4效果評估:Precision,Recall, F-measure & accuracy
- 1.5 實踐經驗
- 1.6 模型比較的統計檢驗
- 1.7 特徵選擇
- 2.情感分析
1.樸素貝葉斯
本質上就是機器學習中的監督學習的分類方法,情感是否正向(0或1)就是我們所預測
等等等等

1.1 樸素貝葉斯推導
本文提到的是multinomial 樸素貝葉斯,即特徵向量不是連續的,是0~x的整數。其中的特徵向量其實就是詞袋向量(bag-of-words),即每個單詞在一篇文章或句子中的計陣列成的一維向量。

是引數,省略



最大後驗的貝葉斯和樸素貝葉斯分類器
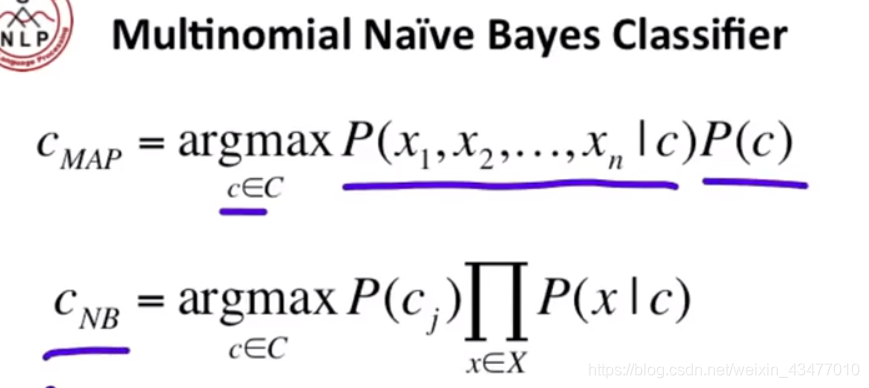

1.2 樸素貝葉斯訓練
先驗
等於類別c出現的概率

假定
是獨立的,則likelihood
等於在c類中,單詞
出現的概率(出現的次數處以c類中出現的所有單詞次數合)

樸素貝葉斯中的Laplace平滑:

下面是簡化版流程和虛擬碼


1.3樸素貝葉斯和語言模型
樸素貝葉斯有點像多個unigram,以情感positive或者negative為例子,就像訓練了一個
和一個
,如果
的概率較大,則句子的情感被分為negative


我們也可以使用詞袋模型的子空間(去掉很多諸如I,and等中性詞),不過詞袋模型丟失了很多資訊,比如詞在原文中的位置等等。


1.4效果評估:Precision,Recall, F-measure & accuracy
以二分類問題為例:
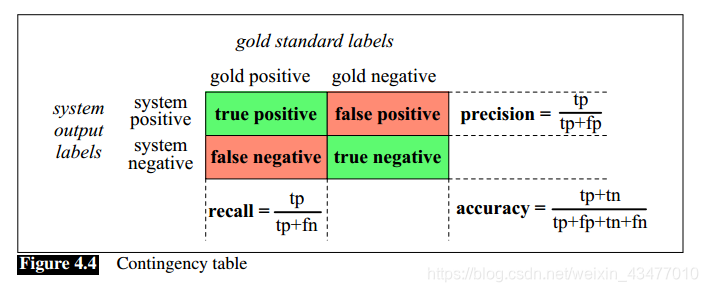
contingency table -> 列聯表
gold label -> 人類給定的標籤,也就是所謂正確的label
false positive -> select as positive falsely
在一些例子中,比如判斷一個詞是不是一個鞋的品牌名字,這種情況下,可能我們99.9%的詞都不是鞋的品牌(eg.1000個詞,只有十個positive的),那我們豈不是所以都標“negative”,那準確率也有99.9%了?所以此時就應該考慮召回率或準確度,在這個例子中:
換個例子
分類器選出來40個positive,其中8個正確
| gold positive | gold negative | |
|---|---|---|
| system positive | 8 | 32 |
| system negative | 2 | 958 |
此時
Recall和Precision之間存在一種權衡的關係,增加Recall的同時Precision會降低,所以我們可以用F-score,一個recall和precision的結合(調和平均)來計算


調和平均是一個比較保守的評估方法,對比於算術平均,其的值會更接近兩個數中比較小的那個,所以其給Recall和Precion中比較小的那個更大的權重。
多分類問題:
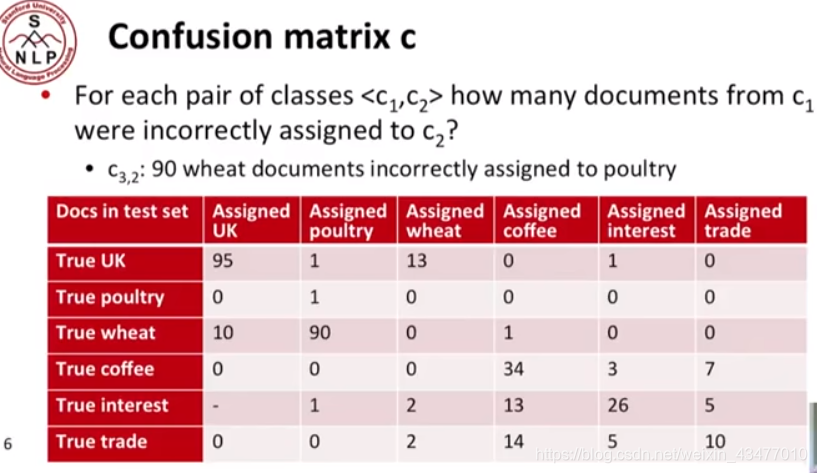

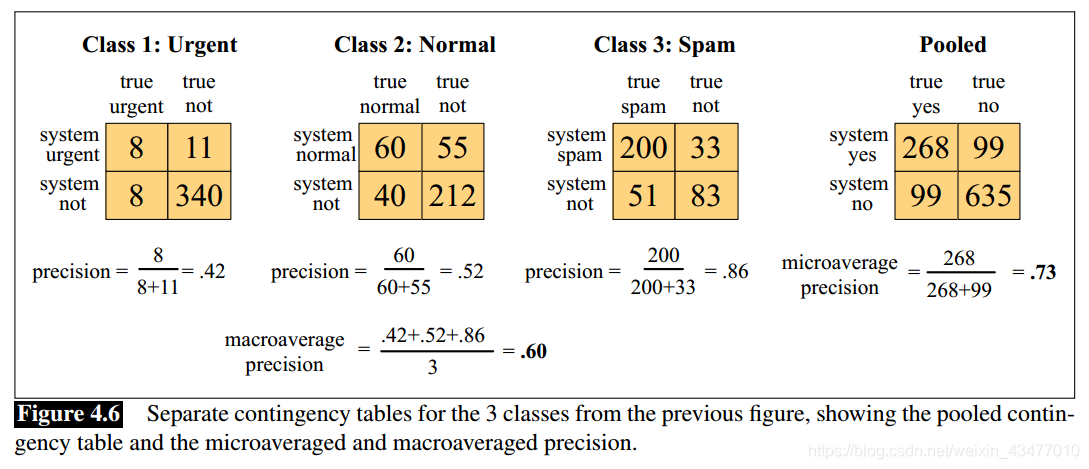
使用microaverage和macroaverage使資料更直觀:
macroaverage是從巨集觀角度上,總和,再求準確度,而microaverage是按每個類求準確度再平均
交叉驗證:

1.5 實踐經驗
樸素貝葉斯很適合小資料,而且即使在這樣的情況下也不會過擬合

資料量合適時候

資料量足夠時,分類器的影響不大
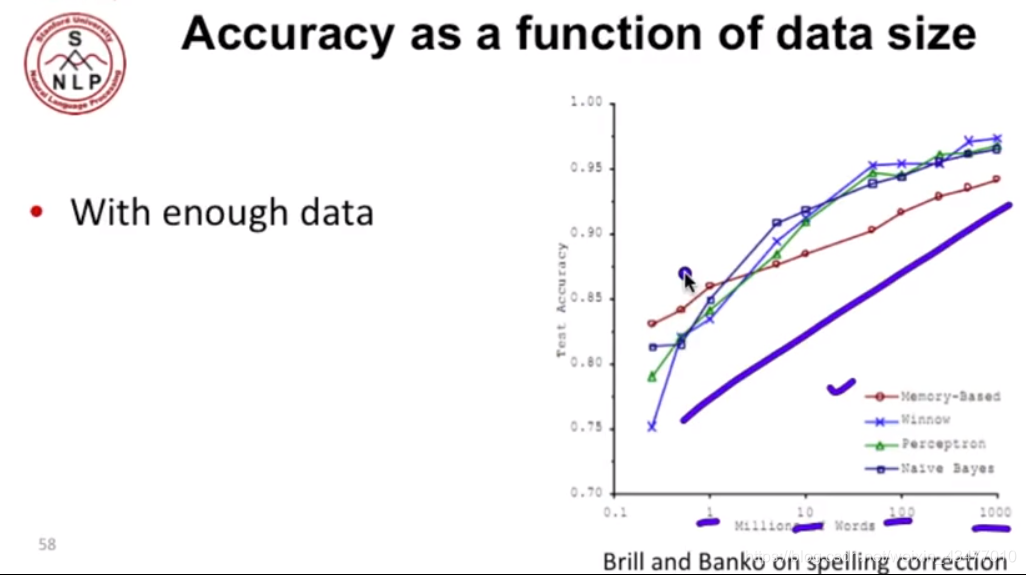
不同領域的特徵和術語的處理也很重要,而詞幹提取幫助不大。給與比如標題等更大的權重也是不錯的選擇

part number 零件號碼
1.6 模型比較的統計檢驗
我們可以通過macro-averaged F1進行比較,看那個得分高,但是你不知道是不是因為test分割的巧合,導致其恰巧準確率高,所以我們可以引入統計學的方法來檢驗。模型A和B的分類結果的差為