Tensorflow簡單神經網路解決Kaggle比賽Titanic問題
又到了假期,忙碌了一個學期,終於可以休息一下了。
一直想再Kaggle上參加一次比賽,在學校要上課,還跟老師做個專案,現在有時間了,就馬上用Kaggle的入門比賽試試手。
一場比賽,總的來說收穫不小,平時學習的時候總是眼高手低,結果中間出現令人吐血的失誤 >_<
Kaggle比賽介紹
簡而言之,Kaggle 是玩資料、ML 的開發者們展示功力、揚名立萬的江湖,網址:https://www.kaggle.com/
Kaggle雖然高手雲集,但是對於萌新們來說也是非常友好的,這次的Titanic問題就是適合萌新Getting Started的入門題。
Titanic問題概述
Titanic: Machine Learning from Disaster
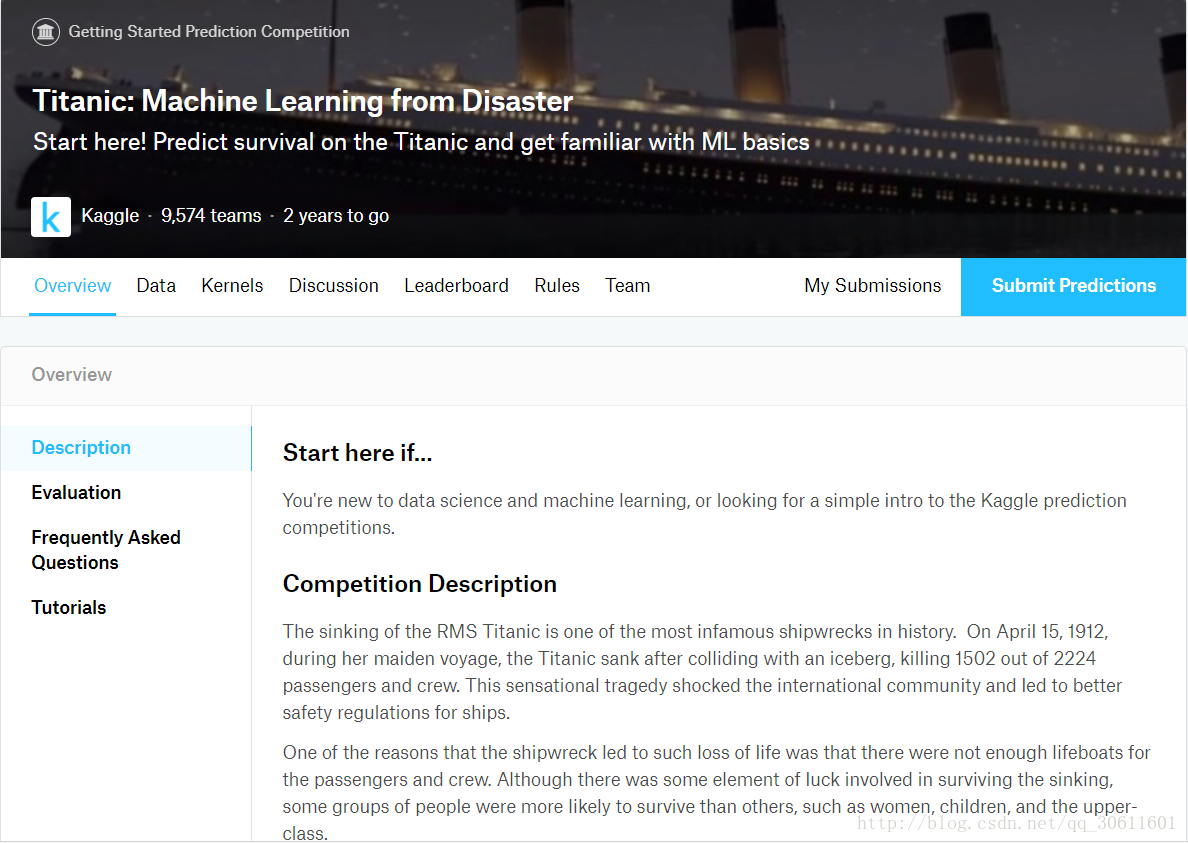
比賽說明
RMS泰坦尼克號的沉沒是歷史上最臭名昭著的沉船之一。 1912年4月15日,在首航期間,泰坦尼克號撞上一座冰山後沉沒,2224名乘客和機組人員中有1502人遇難。這一聳人聽聞的悲劇震撼了國際社會,導致了更好的船舶安全條例。
沉船導致生命損失的原因之一是乘客和船員沒有足夠的救生艇。雖然倖存下來的運氣有一些因素,但一些人比其他人更有可能生存,比如婦女,兒童和上層階級。
在這個挑戰中,我們要求你完成對什麼樣的人可能生存的分析。特別是,我們要求你運用機器學習的工具來預測哪些乘客倖存下來的悲劇。
目標
這是你的工作,以預測是否有乘客倖存下來的泰坦尼克號或不。
對於測試集中的每個PassengerId,您必須預測Survived變數的0或1值。
度量值
您的分數是您正確預測的乘客的百分比。這被稱為“準確性”。
提交檔案格式
你應該提交一個csv檔案,正好有418個條目和一個標題行。如果您有額外的列(超出PassengerId和Survived)或行,您的提交將會顯示錯誤。
該檔案應該有2列:
PassengerId(按任意順序排序)
生存(包含你的二元預測:1存活,0死亡)
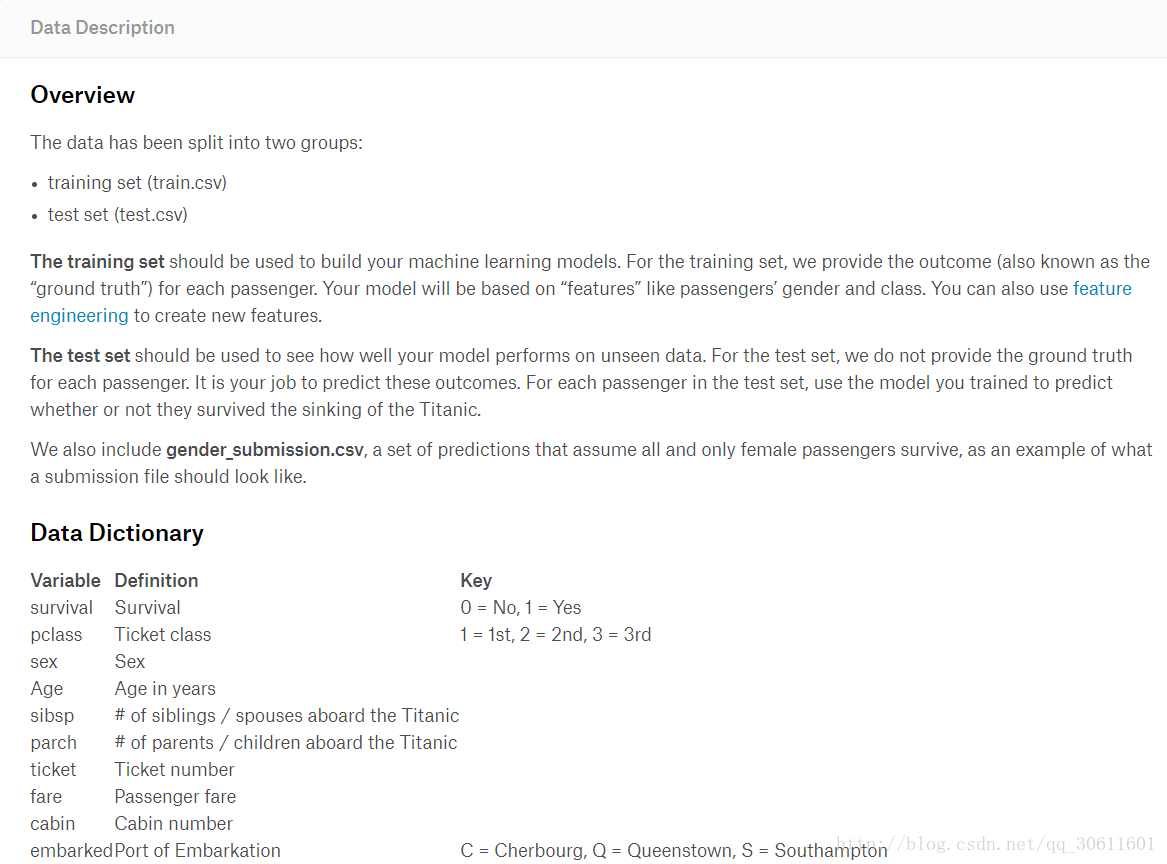
資料總覽
首先,我們先把一些庫和訓練資料匯入
import 簡單的看一下訓練資料的資訊,其中Embarked有兩個缺失值,Age缺失值較多,Cabin有效值太少了跟本沒什麼用。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
None
資料清洗
在我們開始搭建神經網路進行訓練之前,資料清洗是必要的。這一步可以簡單一些,不過如果想要得到更好的效果,清洗之前的資料分析還是不可少的。這裡的資料分析,我就不再贅述了,給大家推薦一篇部落格,上面有很詳細的分析過程——Kaggle_Titanic生存預測
我們用隨機森林演算法,對’Age’的缺失值進行預測,當然這裡也可以用其他迴歸演算法,來進行預測
from sklearn.ensemble import RandomForestRegressor
age = train_data[['Age','Survived','Fare','Parch','SibSp','Pclass']]
age_notnull = age.loc[(train_data.Age.notnull())]
age_isnull = age.loc[(train_data.Age.isnull())]
X = age_notnull.values[:,1:]
Y = age_notnull.values[:,0]
rfr = RandomForestRegressor(n_estimators=1000,n_jobs=-1)
rfr.fit(X,Y)
predictAges = rfr.predict(age_isnull.values[:,1:])
train_data.loc[(train_data.Age.isnull()),'Age'] = predictAges如果對上一步覺得太麻煩,或不喜歡的話,可以更簡單一點,直接把缺失值都給0
train_data = train_data.fillna(0) #缺失欄位填0然後,對於性別’Sex’,我們將其二值化’male’為0,’female’為1
train_data.loc[train_data['Sex']=='male','Sex'] = 0
train_data.loc[train_data['Sex']=='female','Sex'] = 1我們把’Embarked’也填補下缺失值,因為缺失值較少,所以我們直接給它填補上它的眾數’S’,把’S’,’C’,’Q’定性轉換為0,1,2,這樣便於機器進行學習
train_data['Embarked'] = train_data['Embarked'].fillna('S')
train_data.loc[train_data['Embarked'] == 'S','Embarked'] = 0
train_data.loc[train_data['Embarked'] == 'C','Embarked'] = 1
train_data.loc[train_data['Embarked'] == 'Q','Embarked'] = 2最後,把’Cabin’這個與生存關係不重要而且有效資料極少的標籤丟掉,再加上一個’Deceased’,代表的是是否遇難,這一步很重要,很重要,很重要!我在做的時候沒加這個,後面網路的y的標籤我也只設了1,訓練出的模型跟沒訓練一樣,所有的都是0。發現的時候,死的心都有了╥﹏╥…(希望不會有初學者和我犯一樣的錯誤 ToT )
train_data.drop(['Cabin'],axis=1,inplace=True)
train_data['Deceased'] = train_data['Survived'].apply(lambda s: 1 - s)然後,我們再檢視一下資料資訊
train_data.info()這次資訊就整齊多了
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 891 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Embarked 891 non-null object
Deceased 891 non-null int64
dtypes: float64(2), int64(6), object(4)
memory usage: 83.6+ KB
模型搭建
現在我們把資料的X,Y進行分離,這裡我們只選取了6個標籤作為X,如果想讓結果儘可能準確,請讀者自行完善。
dataset_X = train_data[['Sex','Age','Pclass','SibSp','Parch','Fare']]
dataset_Y = train_data[['Deceased','Survived']]這裡,我們進行訓練集和驗證集的劃分,在訓練過程中,我們可以更好的觀察訓練情況,避免過擬合
from sklearn.model_selection import train_test_split
X_train,X_val,Y_train,Y_val = train_test_split(dataset_X.as_matrix(),
dataset_Y.as_matrix(),
test_size = 0.2,
random_state = 42)做完以上工作,我們就可以開始搭建神經網路了,這裡,我搭建的是一個簡單兩層的神經網路,啟用函式使用的是線性整流函式Relu,並使用了交叉驗證和Adam優化器(也可以使用梯度下降進行優化),設定學習率為0.001
x = tf.placeholder(tf.float32,shape = [None,6],name = 'input')
y = tf.placeholder(tf.float32,shape = [None,2],name = 'label')
weights1 = tf.Variable(tf.random_normal([6,6]),name = 'weights1')
bias1 = tf.Variable(tf.zeros([6]),name = 'bias1')
a = tf.nn.relu(tf.matmul(x,weights1) + bias1)
weights2 = tf.Variable(tf.random_normal([6,2]),name = 'weights2')
bias2 = tf.Variable(tf.zeros([2]),name = 'bias2')
z = tf.matmul(a,weights2) + bias2
y_pred = tf.nn.softmax(z)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=z))
correct_pred = tf.equal(tf.argmax(y,1),tf.argmax(y_pred,1))
acc_op = tf.reduce_mean(tf.cast(correct_pred,tf.float32))
train_op = tf.train.AdamOptimizer(0.001).minimize(cost)下面開始訓練,訓練之前我先定義了個Saver,epoch為30次
# 存檔入口
saver = tf.train.Saver()
# 在Saver宣告之後定義的變數將不會被儲存
# non_storable_variable = tf.Variable(777)
ckpt_dir = './ckpt_dir'
if not os.path.exists(ckpt_dir):
os.makedirs(ckpt_dir)
with tf.Session() as sess:
tf.global_variables_initializer().run()
ckpt = tf.train.latest_checkpoint(ckpt_dir)
if ckpt:
print('Restoring from checkpoint: %s' % ckpt)
saver.restore(sess, ckpt)
for epoch in range(30):
total_loss = 0.
for i in range(len(X_train)):
feed_dict = {x: [X_train[i]],y:[Y_train[i]]}
_,loss = sess.run([train_op,cost],feed_dict=feed_dict)
total_loss +=loss
print('Epoch: %4d, total loss = %.12f' % (epoch,total_loss))
if epoch % 10 == 0:
accuracy = sess.run(acc_op,feed_dict={x:X_val,y:Y_val})
print("Accuracy on validation set: %.9f" % accuracy)
saver.save(sess, ckpt_dir + '/logistic.ckpt')
print('training complete!')
accuracy = sess.run(acc_op,feed_dict={x:X_val,y:Y_val})
print("Accuracy on validation set: %.9f" % accuracy)
pred = sess.run(y_pred,feed_dict={x:X_val})
correct = np.equal(np.argmax(pred,1),np.argmax(Y_val,1))
numpy_accuracy = np.mean(correct.astype(np.float32))
print("Accuracy on validation set (numpy): %.9f" % numpy_accuracy)
saver.save(sess, ckpt_dir + '/logistic.ckpt')
'''
測試資料的清洗和訓練資料一樣,兩者可以共同完成
'''
# 讀測試資料
test_data = pd.read_csv('test.csv')
#資料清洗, 資料預處理
test_data.loc[test_data['Sex']=='male','Sex'] = 0
test_data.loc[test_data['Sex']=='female','Sex'] = 1
age = test_data[['Age','Sex','Parch','SibSp','Pclass']]
age_notnull = age.loc[(test_data.Age.notnull())]
age_isnull = age.loc[(test_data.Age.isnull())]
X = age_notnull.values[:,1:]
Y = age_notnull.values[:,0]
rfr = RandomForestRegressor(n_estimators=1000,n_jobs=-1)
rfr.fit(X,Y)
predictAges = rfr.predict(age_isnull.values[:,1:])
test_data.loc[(test_data.Age.isnull()),'Age'] = predictAges
test_data['Embarked'] = test_data['Embarked'].fillna('S')
test_data.loc[test_data['Embarked'] == 'S','Embarked'] = 0
test_data.loc[test_data['Embarked'] == 'C','Embarked'] = 1
test_data.loc[test_data['Embarked'] == 'Q','Embarked'] = 2
test_data.drop(['Cabin'],axis=1,inplace=True)
#特徵選擇
X_test = test_data[['Sex', 'Age', 'Pclass', 'SibSp', 'Parch', 'Fare']]
#評估模型
predictions = np.argmax(sess.run(y_pred, feed_dict={x: X_test}), 1)
#儲存結果
submission = pd.DataFrame({
"PassengerId": test_data["PassengerId"],
"Survived": predictions
})
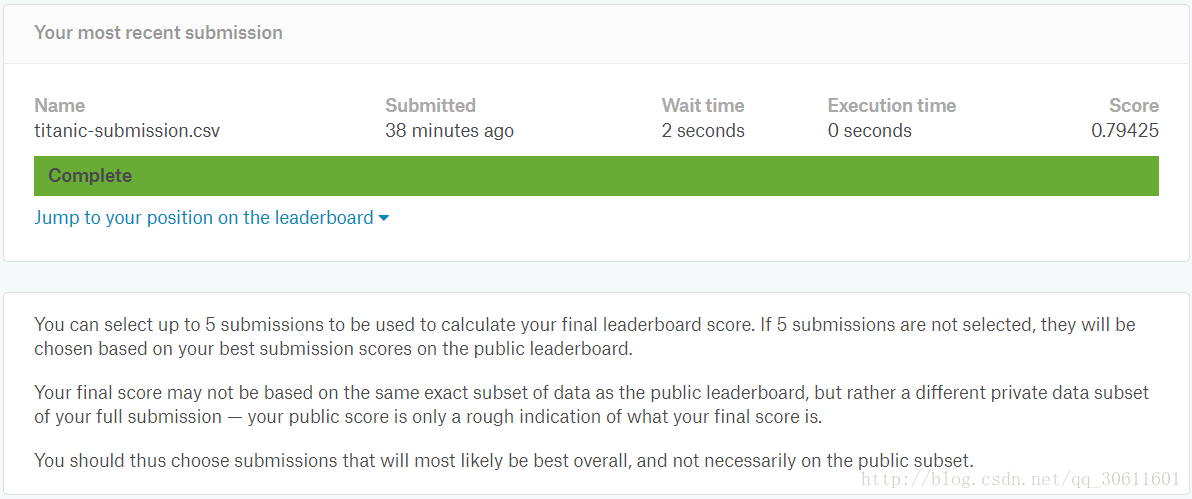
submission.to_csv("titanic-submission.csv", index=False) 我們把生成的提交檔案在Kaggle官網上進行提交,Score為0.79425,效果還可以,不過還有很多需要改進的地方