
找到100億個URL中的重複URL以及搜尋詞彙的topK問題
阿新 • • 發佈:2019-01-02
有一個包含100億個URL的檔案,假設每個URL佔用64B,請找出其中所有重複的URL。
這類問題一種解決方案(我只想到了這一種)
將檔案通過雜湊函式成多個小的檔案,由於雜湊函式所有重複的URL只可能在同一個檔案中,在每個檔案中利用一個雜湊表做次數統計。就能找到重複的URL。這時候要注意的就是給了多少記憶體,我們要根據檔案大小結合記憶體大小決定要分割多少檔案
topK問題和重複URL其實是一樣的重複的多了才會變成topK,其實就是在上述方法後獲得所有的重複URL排個序,但是有點沒必要,因為我們要找topK時,最極端的情況也就是topK在用一個檔案中,所以我們只需要每個檔案的topK個URL,之後再進行排序,這樣就比找出全部的URL在排序方法優秀。還有一個topK個URL到最後還是需要排序,所以我們在找每個檔案的topK時,是否只需要找到topK個,其中順序不用管,那麼我們就可以用大小為K的小根堆遍歷雜湊表。這樣又可以降低查詢的時間。
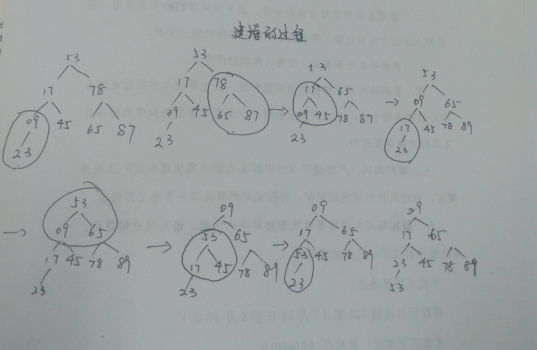
這裡我來講一下為什麼用小根堆。
小根堆是一棵完全二叉樹存在如下特性
(1)若樹根結點存在左孩子,則根結點的值(或某個域的值)小於等於左孩子結點的值(或某個域的值);
(2)若樹根結點存在右孩子,則根結點的值(或某個域的值)小於等於右孩子結點的值(或某個域的值);
(3)以左、右孩子為根的子樹又各是一個堆。
建最小堆的過程,從最後一個葉節點的父節點開始,往前逐個檢查各個節點,看其是不是符合父節點小於它的子節點,如果不小於,則將它的 子節點中最小的那個節點與父節點對換;否則,不交換,
限於篇幅,我將在下一篇中,寫一下最小堆的c++實現