
Scrapy實現對新浪微博某關鍵詞的爬取以及不同url中重複內容的過濾
阿新 • • 發佈:2018-12-14
工作原因需要爬取微博上相關微博內容以及評論。直接scrapy上手,發現有部分重複的內容出現。(標題重複,內容重複,但是url不重複)
1.scrapy爬取微博內容
為了降低爬取難度,直接爬取微博的移動端:(電腦訪問到移動版本微博,之後F12調出控制檯來操作)
點選搜尋欄:輸入相關搜尋關鍵詞:
我們要搜尋的“范冰冰” 其實做了URL編碼:
class SinaspiderSpider(scrapy.Spider): name = 'weibospider' allowed_domains = ['m.weibo.cn'] start_urls = ['https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E8%8C%83%E5%86%B0%E5%86%B0&page_type=searchall'] Referer = {"Referer": "https://m.weibo.cn/p/searchall?containerid=100103type%3D1%26q%3D"+quote("范冰冰")} def start_requests(self): yield Request(url="https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D"+quote("范冰冰")+"&page_type=searchall&page=1",headers=self.Referer,meta={"page":1,"keyword":"范冰冰"})
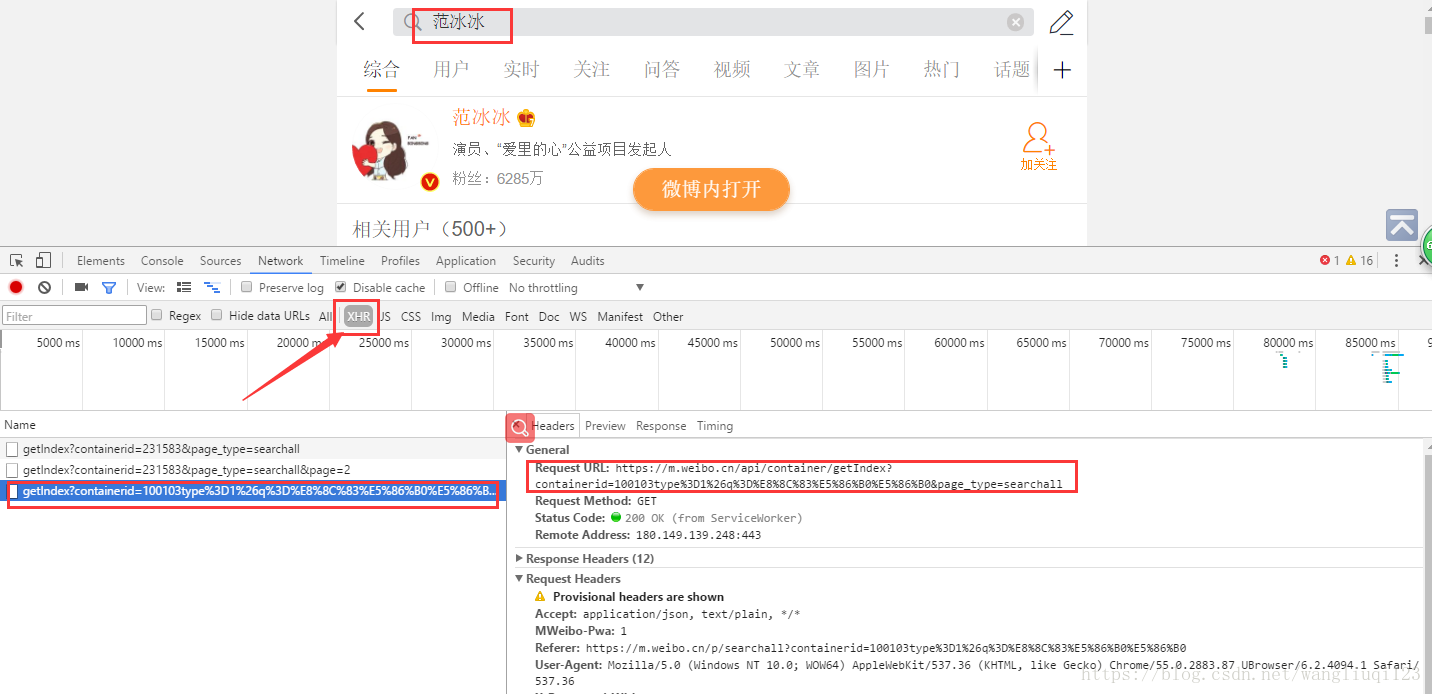
之後我們滾動往下拉發現url是有規律的:
https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E8%8C%83%E5%86%B0%E5%86%B0&page_type=searchall&page=2 https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E8%8C%83%E5%86%B0%E5%86%B0&page_type=searchall&page=3 https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E8%8C%83%E5%86%B0%E5%86%B0&page_type=searchall&page=4 https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E8%8C%83%E5%86%B0%E5%86%B0&page_type=searchall&page=5 https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E8%8C%83%E5%86%B0%E5%86%B0&page_type=searchall&page=6 https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E8%8C%83%E5%86%B0%E5%86%B0&page_type=searchall&page=7
在原來的基礎上新增了一個引數“&page=2” 這些引數從哪裡來的呢?我們如何判斷多少頁的時候就沒有了呢?
開啟我們最開始的那條URL:
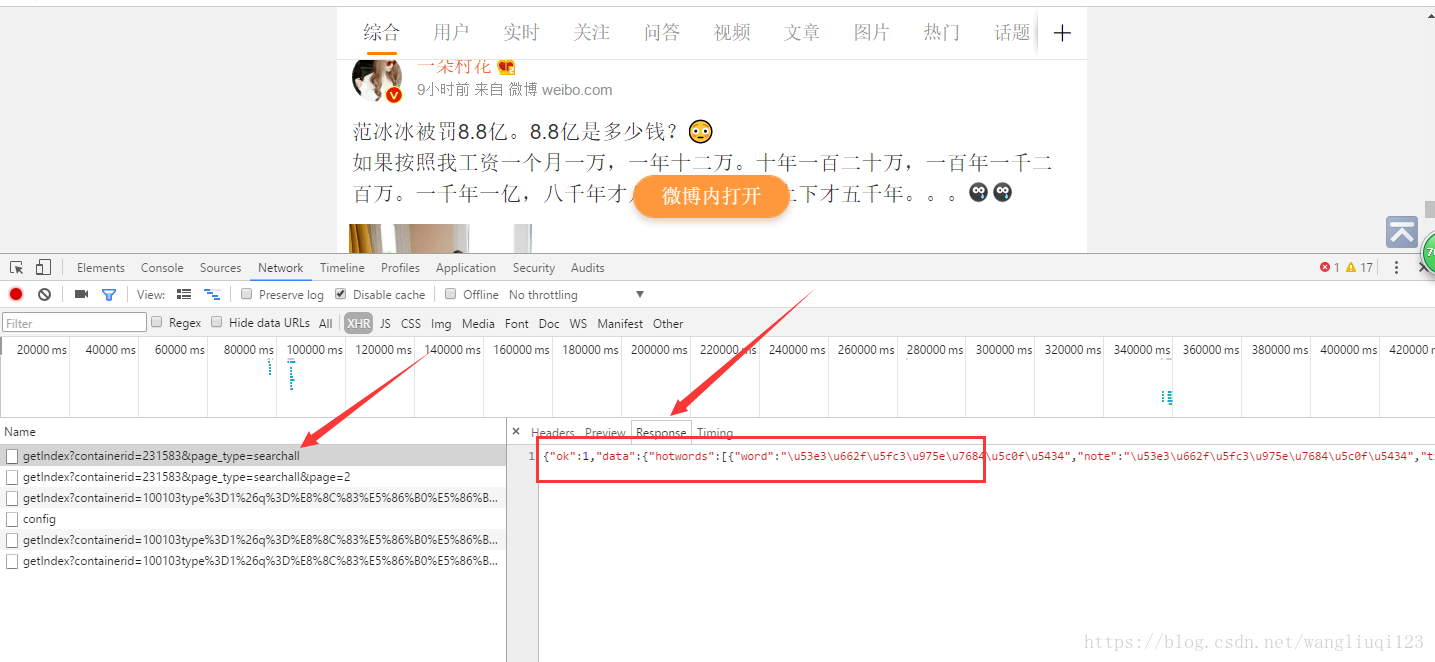
複製這段json,然後通過下面兩個網站格式化一下,便於我們觀察規律:
線上工具有特別豐富的功能讓我們更好的檢視json:
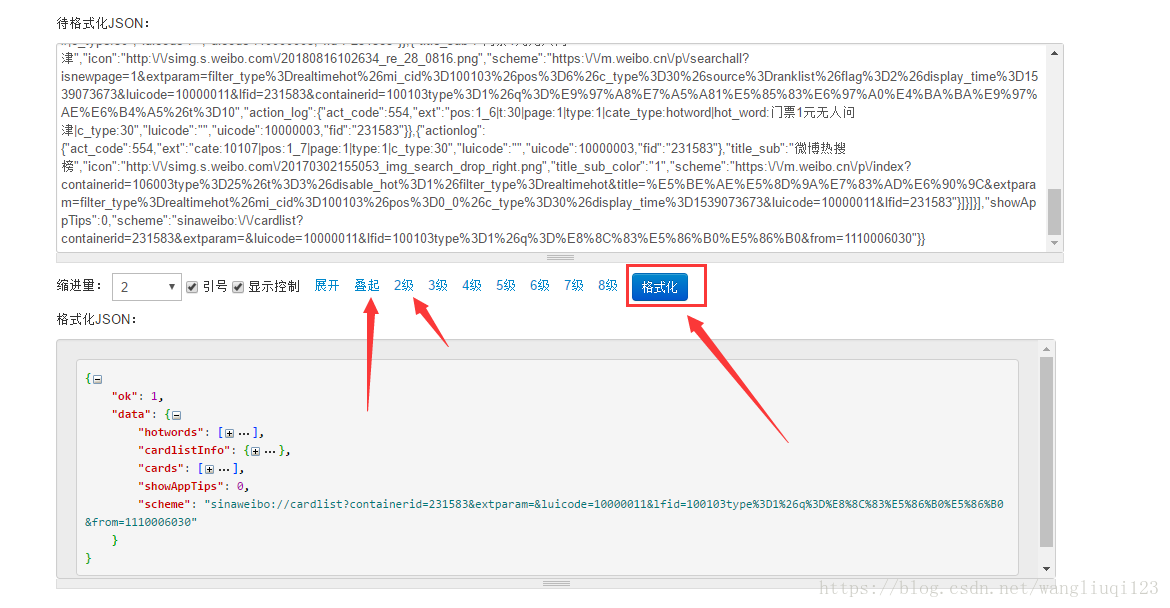
我們發現JSON中儲存著我們要的頁面資訊:
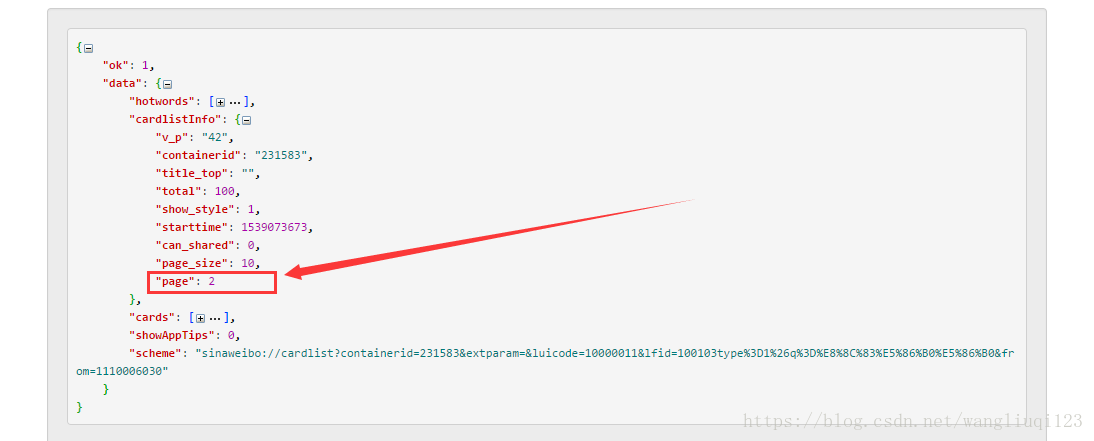
其他的資訊一次類推在JSON或者URL中觀察:
微博爬取parse函式:
def parse(self, response): base_url = "https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D"+quote("范冰冰")+"&page_type=searchall&page=" results = json.loads(response.text,encoding="utf-8") page = response.meta.get("page") keyword = response.meta.get("keyword") # 下一頁 next_page = results.get("data").get("cardlistInfo").get("page") if page != next_page: yield Request(url=base_url+str(next_page), headers=self.Referer, meta={"page":next_page,"keyword":keyword}) result = results.get("data").get("cards") # 獲取微博 for j in result: card_type = j.get("card_type") show_type = j.get("show_type") # 過濾 if show_type ==1 and card_type ==11 : for i in j.get("card_group"): reposts_count = i.get("mblog").get("reposts_count") comments_count = i.get("mblog").get("comments_count") attitudes_count = i.get("mblog").get("attitudes_count") # 過濾到評論 轉發 喜歡都為0 的微博 if reposts_count and comments_count and attitudes_count: message_id = i.get("mblog").get("id") status_url = "https://m.weibo.cn/comments/hotflow?id=%s&mid=%s&max_id_type=0" # 返回微博評論爬取 yield Request(url=status_url%(message_id,message_id),callback=self.commentparse, meta={"keyword":keyword,"message_id":message_id}) title = keyword status_url = "https://m.weibo.cn/status/%s" # response1 = requests.get(status_url%message_id) if i.get("mblog").get("page_info"): content = i.get("mblog").get("page_info").get("page_title") content1 = i.get("mblog").get("page_info").get("content1") content2 = i.get("mblog").get("page_info").get("content2") else: content = "" content1 = "" content2 = "" text = i.get("mblog").get("text").encode(encoding="utf-8") textLength = i.get("mblog").get("textLength") isLongText = i.get("mblog").get("isLongText") create_time = i.get("mblog").get("created_at") spider_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") user = i.get("mblog").get("user").get("screen_name") message_url = i.get("scheme") longText = i.get("mblog").get("longText").get("longTextContent") if isLongText else "" reposts_count = reposts_count comments_count = comments_count attitudes_count = attitudes_count weiboitemloader = WeiBoItemLoader(item=WeibopachongItem()) weiboitemloader.add_value("title",title ) weiboitemloader.add_value("message_id",message_id ) weiboitemloader.add_value("content",content ) weiboitemloader.add_value("content1",content1 ) weiboitemloader.add_value("content2",content2 ) weiboitemloader.add_value("text",text ) weiboitemloader.add_value("textLength",textLength ) weiboitemloader.add_value("create_time",create_time ) weiboitemloader.add_value("spider_time",spider_time ) weiboitemloader.add_value("user1",user ) weiboitemloader.add_value("message_url",message_url ) weiboitemloader.add_value("longText1",longText ) weiboitemloader.add_value("reposts_count",reposts_count ) weiboitemloader.add_value("comments_count",comments_count ) weiboitemloader.add_value("attitudes_count",attitudes_count ) yield weiboitemloader.load_item()
2.scrapy爬取微博評論
評論在微博正文中往下拉滑鼠可以獲得URL規律,下面是微博評論解析函式:
def commentparse(self,response):
status_after_url = "https://m.weibo.cn/comments/hotflow?id=%s&mid=%s&max_id=%s&max_id_type=%s"
message_id = response.meta.get("message_id")
keyword = response.meta.get("keyword")
results = json.loads(response.text, encoding="utf-8")
if results.get("ok"):
max_id = results.get("data").get("max_id")
max_id_type = results.get("data").get("max_id_type")
if max_id:
# 評論10 個為一段,下一段在上一段JSON中定義:
yield Request(url=status_after_url%(message_id,message_id,str(max_id),str(max_id_type)),callback=self.commentparse,meta={"keyword":keyword,"message_id":message_id})
datas = results.get("data").get("data")
for data in datas:
text1 = data.get("text")
like_count = data.get("like_count")
user1 = data.get("user").get("screen_name")
user_url = data.get("user").get("profile_url")
emotion = SnowNLP(text1).sentiments
weibocommentitem = WeiboCommentItem()
weibocommentitem["title"] = keyword
weibocommentitem["message_id"] = message_id
weibocommentitem["text1"] = text1
weibocommentitem["user1"] = user1
weibocommentitem["user_url"] = user_url
weibocommentitem["emotion"] = emotion
yield weibocommentitem最後非同步存入MYSQL:
item:
import scrapy
from scrapy.loader import ItemLoader
from scrapy.loader.processors import Compose
def get_First(values):
if values is not None:
return values[0]
class WeiBoItemLoader(ItemLoader):
default_output_processor = Compose(get_First)
class WeibopachongItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
message_id = scrapy.Field()
content = scrapy.Field()
content1 = scrapy.Field()
content2 = scrapy.Field()
text = scrapy.Field()
textLength = scrapy.Field()
create_time = scrapy.Field()
spider_time = scrapy.Field()
user1 = scrapy.Field()
message_url = scrapy.Field()
longText1 = scrapy.Field()
reposts_count = scrapy.Field()
comments_count = scrapy.Field()
attitudes_count = scrapy.Field()
def get_insert_sql(self):
insert_sql = """
insert into t_public_opinion_realtime_weibo(title,message_id,content,content1,content2,text,textLength,create_time,spider_time,user1,message_url,longText1,reposts_count,comments_count,attitudes_count)values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
parms = (self["title"],self["message_id"],self["content"],self["content1"],self["content2"],self["text"],self["textLength"],self["create_time"],self["spider_time"],self["user1"],self["message_url"],self["longText1"],self["reposts_count"],self["comments_count"],self["attitudes_count"])
return insert_sql, parms
class WeiboCommentItem(scrapy.Item):
title = scrapy.Field()
message_id = scrapy.Field()
text1 = scrapy.Field()
user1 = scrapy.Field()
user_url = scrapy.Field()
emotion = scrapy.Field()
def get_insert_sql(self):
insert_sql = """
insert into t_public_opinion_realtime_weibo_comment(title,message_id,text1,user1,user_url,emotion)
values (%s,%s,%s,%s,%s,%s)
"""
parms = (self["title"],self["message_id"],self["text1"],self["user1"],self["user_url"],self["emotion"])
return insert_sql, parmsPipline:非同步插入:
# 插入
class MysqlTwistedPipline(object):
def __init__(self,dbpool):
self.dbpool=dbpool
@classmethod
def from_settings(cls,setting):
dbparms=dict(
host=setting["MYSQL_HOST"],
db=setting["MYSQL_DBNAME"],
user=setting["MYSQL_USER"],
passwd=setting["MYSQL_PASSWORD"],
charset='utf8mb4',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True,
)
dbpool=adbapi.ConnectionPool("MySQLdb",**dbparms)
return cls(dbpool)
#mysql非同步插入執行
def process_item(self, item, spider):
query=self.dbpool.runInteraction(self.do_insert,item)
query.addErrback(self.handle_error,item,spider)
def handle_error(self,failure,item,spider):
#處理非同步插入的異常
print (failure)
def do_insert(self,cursor,item):
insert_sql,parms=item.get_insert_sql()
print(parms)
cursor.execute(insert_sql, parms)按照規則來寫爬蟲還是難免有重複:

所以需要在插入內容前對資料進行去重處理
3.scrapy+Redis實現對重複微博的過濾
這裡使用Redis中的Set集合來實現,也可以用Python中的Set來做,資料量不大的情況下,Redis中Set有Sadd方法,當成功插入資料後,會返回1。如果插入重複資料則會返回0。
redis_db = redis.Redis(host='127.0.0.1', port=6379, db=0)
result = redis_db.sadd("wangliuqi","12323")
print(result)
result1 = redis_db.sadd("wangliuqi","12323")
print(result1)
結果:=========》》》》》》》》
1
0在Scrapy中新增一個pipline,然後對每一個要儲存的item進行判斷,如果是重複的微博則對其進行丟棄操作:
RemoveReDoPipline:
class RemoveReDoPipline(object):
def __init__(self,host):
self.conn = MySQLdb.connect(host, 'root', 'root', 'meltmedia', charset="utf8", use_unicode=True)
self.redis_db = redis.Redis(host='127.0.0.1', port=6379, db=0)
sql = "SELECT message_id FROM t_public_opinion_realtime_weibo"
# 獲取全部的message_id,這是區分是不是同一條微博的標識
df = pd.read_sql(sql, self.conn)
# 全部放入Redis中
for mid in df['message_id'].get_values():
self.redis_db.sadd("weiboset", mid)
# 獲取setting檔案配置
@classmethod
def from_settings(cls,setting):
host=setting["MYSQL_HOST"]
return cls(host)
def process_item(self, item, spider):
# 只對微博的Item過濾,微博評論不需要過濾直接return:
if isinstance(item,WeibopachongItem):
if self.redis_db.sadd("weiboset",item["message_id"]):
return item
else:
print("重複內容:", item['text'])
raise DropItem("same title in %s" % item['text'])
else:
return item
最後別忘了在setting檔案中把pipline配置進去,並且要配置到儲存資料pipline前面才可以。否則起不到過濾效果:
ITEM_PIPELINES = {
'weibopachong.pipelines.MysqlTwistedPipline': 200,
'weibopachong.pipelines.RemoveReDoPipline': 100,
}