
CNTK API文件翻譯(17)——多對多神經網路處理文字資料(1)
(本期教程需要翻譯的內容實在是太多了,將其分割成兩期,本期主要講理論和模型建立,下期主要講訓練、測試、優化等)
背景和簡介
本教程將帶你過一遍多對多神經網路基礎,以及如何在CNTK中實現它。具體來說,我們將實現一個多對多模型用來實現字音轉換。我們首先會介紹多對多網路的基本理論、解釋資料細節以及如何下載資料。
Andrej Karpathy對常用的物種神經網路結構模式有一個很好的視覺化表達,如圖:
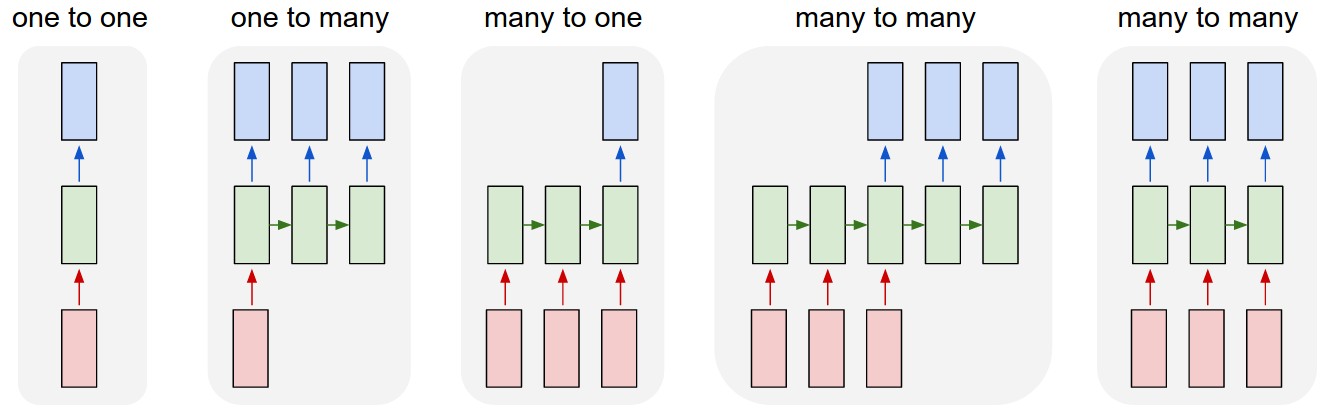
本教程中,我們將討論第四個模式:輸入和輸出的大小不一定要一樣的多對多神經網路,也叫sequence-to-sequence networks(其實文章標題應該是這個,但是我不知道怎麼翻譯)。輸入方式一個動態長度的序列,輸出方也是一個動態長度的序列。這是對我們之前用於預測類別的多對一模型的擴充套件,現在我們要預測類別列表。
quence-to-sequence networks的應用場景幾乎是無限的。他非常適合機器翻譯(比如英語句子是輸入序列,法語句子是輸出序列);自動提取文字概要(比如完整文章是輸入序列,總結概要是輸出序列);詞語發音模型(比如字元是輸入序列,發音是輸出序列);以及解析語法分析樹的生成(比如規則文字是輸入序列,語法樹是輸出序列)。
基本理論
sequence-to-sequence模型由兩個主要部分組成:(1)一個編碼器;(2)一個解碼器。編碼器和解碼器都是遞迴網路層,他們可以由vanilla神經網路實現,也可以由LSTM或者GRU實現(本教程中使用LSTM)。在基本sequence-to-sequence模型中,編碼器將文字處理成解碼器可用的固定表達方式。解碼器使用一些機制將處理過的資訊解碼成一個輸出序列。解碼器是一個由編碼器用強烈語境增強的語言模,所以解碼器產生的所有樣本都會再次返回到解碼器中用於語境資訊。在一個從英語到德語的翻譯任務中,大部分基本構架看起來都是這樣。
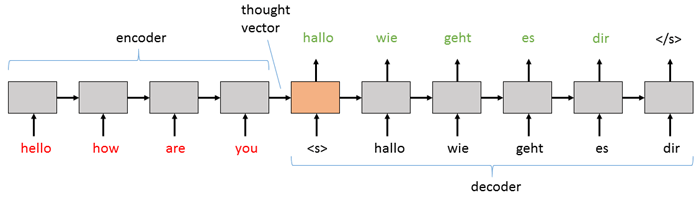
基本的sequence-to-sequence網路在實現解碼RNN時會使用編碼器的最後隱藏狀態作為解碼器的初始狀態,以此實現資訊從編碼器傳遞到解碼器。之後的輸入資料會是一個“序列開始”的標記(在上圖中是)用來指示解碼器開始生成輸出序列。然後無論解碼器生成什麼單詞(或者音符或者圖片),都會在下一步返回到輸入序列中。解碼器持續產生輸出序列,知道遇到“序列結束”標記(上圖中的)。
基本sequence-to-sequence神經網路的一個更復雜和強大的版本是使用注意力模型(Attention Model,AM)。雖然上述模型工作良好,不過如果輸入的序列太長時,就需要進行分解。在每步運算中,隱藏狀態h會根據最新的資訊更新,因此在每次處理之後h都會被削弱。進一步說,即使在相對較短的序列中,最後一次運算會使用最後一次的資訊,導致語言向量多多稍稍會偏向於最後一個詞。為了解決這個問題,我們使用“注意力”機制,讓解碼器不僅僅能夠訪問輸入資料的隱藏狀態,還能夠了解在解碼的每步中權重最大的隱藏向量。在本教程中我們將實現一個既可以沒有注意力模型執行,也可以加入注意力模型執行的sequence-to-sequence神經網路。
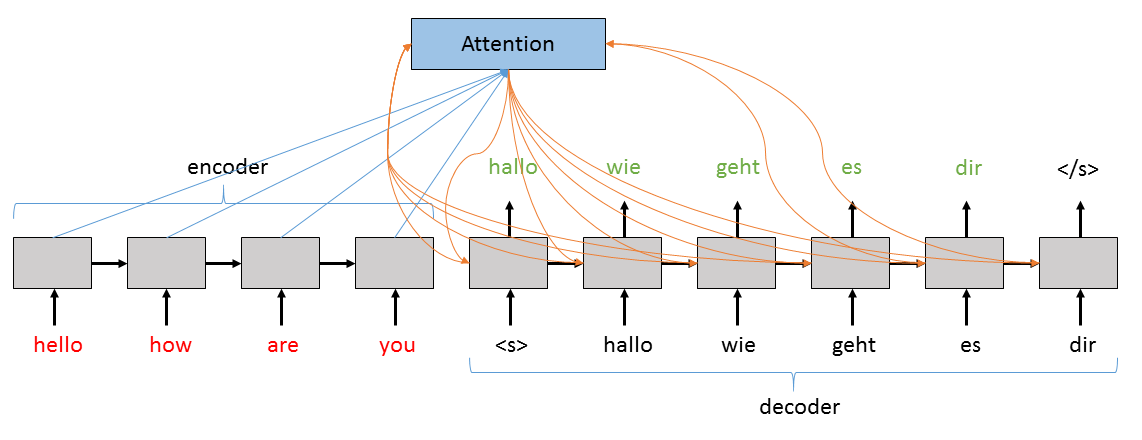
上圖所示的注意力層儲存解碼器中隱藏狀態的當前值、編碼器隱藏狀態的所有值以及計算模型使用的隱藏狀態的增強版本。更具體的說,編碼器隱藏狀態的貢獻值代表了他的所有隱藏狀態的加權和,其中最高的權重對應瞭解碼器在決定下一個詞是考慮的增強隱藏狀態的最大貢獻以及最重要的隱藏狀態。
問題:字音轉換
字音轉換問題是將單詞中的字母作為輸入序列,然後輸出對應的音的轉換任務。換句話說,這個系統用於對給定的單詞生成清晰的發音。
例子
字母的字素轉換成對應的音素:
字素:| T | A | N | G | E | R |
音素:| ~T | ~AE | ~NG | ~ER |
任務和模型結構
如上所述,我們要解決的問題是建立一個模型,輸入一些序列,然後根據輸入的內容生成和輸出序列。模型的工作就是將輸出的序列與輸入的序列對映起來。編碼器的工作是設法將輸入資料生成一個合適的表達方式,能夠讓解碼器輸出較好的結果。LSTM可以用於編碼器和解碼器。
注意LSTM是眾多可以用於實現RNN的模組中的普通一員,這些模組都是在遞迴的每步中執行的程式碼。在CNTK的層級庫中,有三個內建模組:(vanilla)RNN、GRU、以及LSTM。不同的程式的輸入資料有點不同,他們在不同的任務和神經網路中也有自己的優勢和劣勢。為了讓這些模組迴圈執行網路中的所有要素,我們建立一個整體的遞迴。這種操作將RNN層展開成幾步操作。
匯入CNTK和其他用得著的模組
CNTK是一個Python模組,包含幾個子模組比如io,learner,graph等。我們也會大量的用到numpy。
from __future__ import print_function
import numpy as np
import os
import cntk as C在下面的程式碼中,我們通過檢查在CNTK內部定義的環境變數來選擇正確的裝置(GPU或者CPU)來執行程式碼,如果不檢查的話,會使用CNTK的預設策略來使用最好的裝置(如果GPU可用的話就使用GPU,否則使用CPU)
# Define a test environment
def isTest():
return ('TEST_DEVICE' in os.environ)
# Select the right target device when this notebook is being tested:
if 'TEST_DEVICE' in os.environ:
if os.environ['TEST_DEVICE'] == 'cpu':
C.device.try_set_default_device(C.device.cpu())
else:
C.device.try_set_default_device(C.device.gpu(0))下載資料
在本教程中我們將使用來自http://www.speech.cs.cmu.edu/cgi-bin/cmudict的簡單預處理過的CMUDict(Version 0.7b)資料集。CMUDict資料使用了卡耐基梅隆大學的發音詞典,是一個可以被電腦識別的開源美式英語發音字典。資料是CNTK標準文字格式,下面是資料中的一些示例序列組,其中左列輸入序列(s0),右列是輸出序列。
0 |S0 3:1 |# <s> |S1 3:1 |# <s>
0 |S0 4:1 |# A |S1 32:1 |# ~AH
0 |S0 5:1 |# B |S1 36:1 |# ~B
0 |S0 4:1 |# A |S1 31:1 |# ~AE
0 |S0 7:1 |# D |S1 38:1 |# ~D
0 |S0 12:1 |# I |S1 47:1 |# ~IY
0 |S0 1:1 |# </s> |S1 1:1 |# </s>下面的程式碼將下載需要用到的資料檔案(訓練、測試、用於視覺化驗證的單獨序列以及一個小的詞彙檔案),然後將他們放入本地資料夾(訓練檔案大概34M,測試檔案大概4M,驗證檔案和詞彙檔案都小於1K).
import requests
def download(url, filename):
""" utility function to download a file """
response = requests.get(url, stream=True)
with open(filename, "wb") as handle:
for data in response.iter_content():
handle.write(data)
MODEL_DIR = "."
DATA_DIR = os.path.join('..', 'Examples', 'SequenceToSequence', 'CMUDict', 'Data')
# If above directory does not exist, just use current.
if not os.path.exists(DATA_DIR):
DATA_DIR = '.'
dataPath = {
'validation': 'tiny.ctf',
'training': 'cmudict-0.7b.train-dev-20-21.ctf',
'testing': 'cmudict-0.7b.test.ctf',
'vocab_file': 'cmudict-0.7b.mapping',
}
for k in sorted(dataPath.keys()):
path = os.path.join(DATA_DIR, dataPath[k])
if os.path.exists(path):
print("Reusing locally cached:", path)
else:
print("Starting download:", dataPath[k])
url = "https://github.com/Microsoft/CNTK/blob/v2.0/Examples/SequenceToSequence/CMUDict/Data/%s?raw=true"%dataPath[k]
download(url, path)
print("Download completed")
dataPath[k] = path資料讀取器
為了高校的讀取、打亂資料以及將資料傳入我們的神經網路,我們使用CNTKTextFormat讀取器。我們將建立一個簡短的函式用來定義資料流的名稱以及如何與原始訓練/測試資料對應,我們在測試或者訓練的時候呼叫他。
# Helper function to load the model vocabulary file
def get_vocab(path):
# get the vocab for printing output sequences in plaintext
vocab = [w.strip() for w in open(path).readlines()]
i2w = { i:w for i,w in enumerate(vocab) }
w2i = { w:i for i,w in enumerate(vocab) }
return (vocab, i2w, w2i)
# Read vocabulary data and generate their corresponding indices
vocab, i2w, w2i = get_vocab(dataPath['vocab_file'])
def create_reader(path, is_training):
return MinibatchSource(CTFDeserializer(path, StreamDefs(
features = StreamDef(field='S0', shape=input_vocab_dim, is_sparse=True),
labels = StreamDef(field='S1', shape=label_vocab_dim, is_sparse=True)
)), randomize = is_training, max_sweeps = INFINITELY_REPEAT if is_training else 1)
input_vocab_dim = 69
label_vocab_dim = 69
# Print vocab and the correspoding mapping to the phonemes
print("Vocabulary size is", len(vocab))
print("First 15 letters are:")
print(vocab[:15])
print()
print("Print dictionary with the vocabulary mapping:")
print(i2w)我們使用上訴的程式碼建立訓練資料的讀取器,讓我們現在建立他。
# Train data reader
train_reader = create_reader(dataPath['training'], True)
# Validation data reader
valid_reader = create_reader(dataPath['validation'], True)現在讓我們設定模型的超引數
我們有大量的配置引數來空值我們的神經網路:輸入資料的大小、類似我們是否使用詞向量的選項、是否使用注意力模型等。我們在下個部分建立網路模型時就會用到他們,所以我們先做定義他們。
hidden_dim = 512
num_layers = 2
attention_dim = 128
attention_span = 20
attention_axis = -3
use_attention = True
use_embedding = True
embedding_dim = 200
vocab = ([w.strip() for w in open(dataPath['vocab_file']).readlines()]) # all lines of vocab_file in a list
length_increase = 1.5我們還將定義兩個引數:序列開始的標誌(有時候也叫“BOS”)和序列結束的標誌(有時候也叫“EOS”)。在本例中,他們分別是和。
開始標記和結束標記在sequence-to-sequenc神經網路中之所以重要因為兩個原因。序列開始標記是解碼器的入口,換句話說,因為我們生成了一個輸出序列,RNN又需要一些輸入序列,序列中的開始資訊激活了解碼器,讓解碼器生成第一個資訊。結束訊號之所以重要是因為解碼器在序列結束時將輸出結束訊號。不然神經網路將不知道需要生成多長的序列。下面的程式碼我們將會把序列開始標記設定成一個常量,這樣在之後傳入解碼器LSTM網路時就能一直是這個初始狀態。然後我們設定結束標記,解碼器就通過他就可以知道何時停止生產訊號。
sentence_start =C.Constant(np.array([w=='<s>' for w in vocab], dtype=np.float32))
sentence_end_index = vocab.index('</s>')第一步:設定網路輸入資料
CNTK中的動態軸
在理解CNTK時的一個重要概念就是兩種不同軸的理念:
- 靜態軸,變數大小的傳統軸
- 動態軸,具有未知大小,直到計算時變數綁定了具體的資料。
動態軸在遞迴神經網路中尤其重要。CNTK通過自動繫結到取樣包實現允許序列長度可變實現儘可能的高效,而不是提前確定最大序列長度、強行將序列填滿浪費計算資源。
在我們初始化序列是,有兩個重要的動態軸需要考慮。第一個是批次軸,用來表徵有多少個序列為一批。第一個動態軸是序列內特有的動態軸。後者之所以屬於序列,是因為序列的長度隨著輸入資料的變化而變化。比如在sequence to sequence神經網路中,我們有兩個序列,輸入序列和輸出(標籤)序列,這個神經網路強大的重要一環是輸入序列的長度和輸入序列的長度不需要彼此一致,所以輸入序列和輸出序列都需要自己的動態軸。
我們先建立變數inputAxis表示輸入序列的動態軸,labelAxis表示輸出序列的動態軸。然後然後我們通過這兩個軸建立序列來定義模型的輸入資料。注意變數InputSequence和LabelSequence看著像定義了一個變數,實際上是申明瞭一個型別。這表示InputSequence是包含了一個具有inputAxis軸的序列。
# Source and target inputs to the model
inputAxis = C.Axis('inputAxis')
labelAxis = C.Axis('labelAxis')
InputSequence = C.layers.SequenceOver[inputAxis]
LabelSequence = C.layers.SequenceOver[labelAxis]第二步:定義網路
如前面所說,一個最基本的sequence-to-sequence神經網路是由一個RNN (LSTM)編碼器,後面接著一個RNN (LSTM)解碼器,然後這跟著一個全連線輸出層組成的。我們將使用CNTK的層級庫實現編碼器和解碼器,他們都將被建立成CNTK的函式物件。我們的create_model函式中既建立了編碼器函式物件,也建立瞭解碼器函式物件。編碼器函式物件會直接被解碼器函式物件使用,解碼器函式物件將會成為 create_model的返回值。
我們首先將輸入資料進行向量化。所以在之後的應用中,無論我們有沒有將資料向量化,都可以直接傳入由編碼器和解碼器組成的Sequential模組使用,如果use_embedding引數的值是False,我們就使用identity函式。下面我們定義編碼器層。
首先我們將資料通過embed函式(用於向量化),然後將資料持久化。這會給我們的訓練帶來額外的標量引數,不過會讓我們的網路在訓練時更快的收斂。然後在編碼器中除了最後一層外我們需要的的每個LSTM層,我們都對其進行迴圈。如果我們不適用注意力模型,最後一個迴圈將會是一個Fold,因為我們只將最後的隱藏狀態傳遞給解碼器。如果我們使用注意力模型,我們會使用另外一個正常的LSTM迴圈,解碼器會把注意力放在後面。
下面我們看看如何對具有注意力模型的sequence-to-sequence神經網路如何分層。如下面的程式碼中所示,編碼器和解碼器中每層的輸出資料都會被用作上一層的輸入資料。注意力模型主要處理編碼器的頂層和解碼器的第一層。
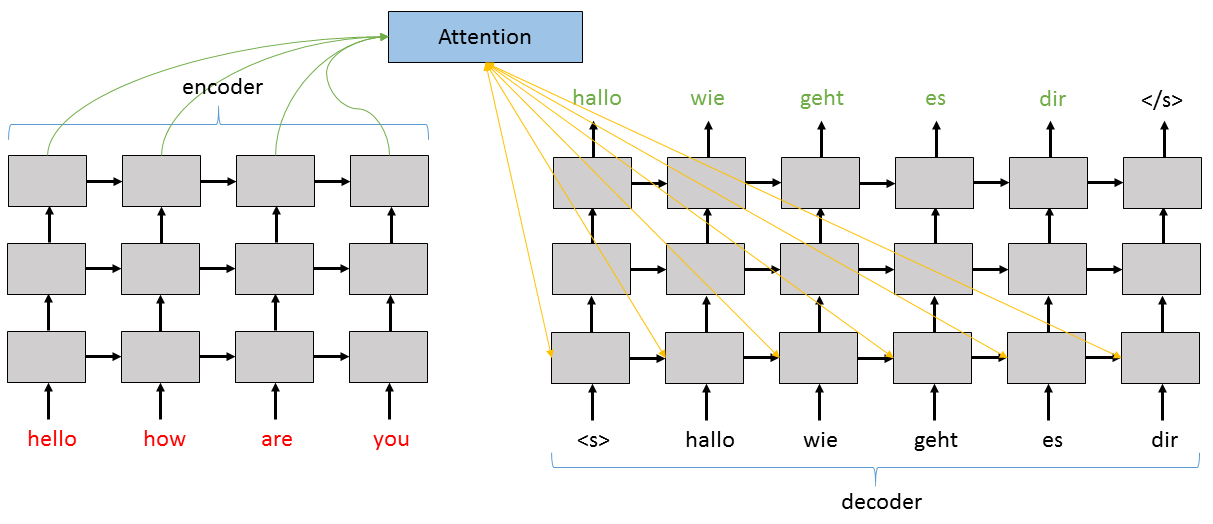
對於解碼器,我們定義了一些子層:用於解碼器輸入資料的Stabilizer,用於解碼器每個層的Recurrence模組,用於LSTM棧輸出的Stabilizer以及最後的Dense輸出層。如果我們使用注意力模型,我們也需要建立一個注意力模型函式attention_model,用於返回增強版的解碼器隱藏狀態,裡面著重記錄了生成下一個輸出訊號時需要用到的編碼器的隱藏狀態。
然後我們建立解碼器函式物件。裝飾器@Function將一個普通的Python函式轉換成CNTK特有的函式物件,給定輸入引數,得到返回值。解碼器在訓練和測試時工作有點不同。在訓練時,解碼器迴圈的輸入由標籤值組成。在測試或評估是,解碼器的輸入會是模型真實的輸出值。對於貪婪解碼器——在本教程中實現的——的輸入值是最後的全連線層的hardmax輸出。
解碼器函式物件具有兩個引數:(1)輸入序列,(2)解碼歷史。首先讓輸入序列在我們之前構造好的編碼函式中執行一遍。然後我們得到了執行歷史,如果有需要還要將其向量化。然後再向量化好的資料用於解碼器遞迴之前,先將其持久化。在遞迴中的每層種,我們都會在迴圈的LSTM中執行一遍向量化好的歷史資料(用r表示)。如果我們不使用注意力模型,我們直接使用它的初始值,也就是編碼器最後的隱藏狀態執行。如果我們使用注意力模型,我們就會使用額外的輸入資料h_att用於attention_model函式,然後將其與輸入資料x結合,最後將這種增強過的x用於解碼器遞迴中。
最後,我們將解碼器的輸出值持久化,將其輸入最後的全連線層proj_out,最後使用Label層將輸出資料標記,讓之後的層可以直接獲取。
# create the s2s model
def create_model(): # :: (history*, input*) -> logP(w)*
# Embedding: (input*) --> embedded_input*
embed = C.layers.Embedding(embedding_dim, name='embed') if use_embedding else identity
# Encoder: (input*) --> (h0, c0)
# Create multiple layers of LSTMs by passing the output of the i-th layer
# to the (i+1)th layer as its input
# Note: We go_backwards for the plain model, but forward for the attention model.
with C.layers.default_options(enable_self_stabilization=True, go_backwards=not use_attention):
LastRecurrence = C.layers.Fold if not use_attention else C.layers.Recurrence
encode = C.layers.Sequential([
embed,
C.layers.Stabilizer(),
C.layers.For(range(num_layers-1), lambda:
C.layers.Recurrence(C.layers.LSTM(hidden_dim))),
LastRecurrence(C.layers.LSTM(hidden_dim), return_full_state=True),
(C.layers.Label('encoded_h'), C.layers.Label('encoded_c')),
])
# Decoder: (history*, input*) --> unnormalized_word_logp*
# where history is one of these, delayed by 1 step and <s> prepended:
# - training: labels
# - testing: its own output hardmax(z) (greedy decoder)
with C.layers.default_options(enable_self_stabilization=True):
# sub-layers
stab_in = C.layers.Stabilizer()
rec_blocks = [C.layers.LSTM(hidden_dim) for i in range(num_layers)]
stab_out = C.layers.Stabilizer()
proj_out = C.layers.Dense(label_vocab_dim, name='out_proj')
# attention model
if use_attention: # maps a decoder hidden state and all the encoder states into an augmented state
# :: (h_enc*, h_dec) -> (h_dec augmented)
attention_model = C.layers.AttentionModel(attention_dim,
attention_span,
attention_axis,
name='attention_model')
# layer function
@C.Function
def decode(history, input):
encoded_input = encode(input)
r = history
r = embed(r)
r = stab_in(r)
for i in range(num_layers):
# LSTM(hidden_dim) # :: (dh, dc, x) -> (h, c)
rec_block = rec_blocks[i]
if use_attention:
if i == 0:
@C.Function
def lstm_with_attention(dh, dc, x):
h_att = attention_model(encoded_input.outputs[0], dh)
x = C.splice(x, h_att)
return rec_block(dh, dc, x)
r = C.layers.Recurrence(lstm_with_attention)(r)
else:
r = C.layers.Recurrence(rec_block)(r)
else:
# unlike Recurrence(), the RecurrenceFrom() layer takes the initial hidden state as a data input
# :: h0, c0, r -> h
r = C.layers.RecurrenceFrom(rec_block)(*(encoded_input.outputs + (r,)))
r = stab_out(r)
r = proj_out(r)
r = C.layers.Label('out_proj_out')(r)
return r
return decode我們上面定義的網路是一個需要被封裝之後才能使用的抽象模型,在本教程中,我們首先將使用它建立一個“訓練”版本,然後我們將建立一個貪婪“解碼”版本,也就是我們上面說的解碼器的歷史將會是網路的hardmax輸出。接下來讓我們設定模型的封裝器。
歡迎掃碼關注我的微信公眾號獲取最新文章
