機器學習練習(五)——高斯異常點檢測
阿新 • • 發佈:2019-01-02
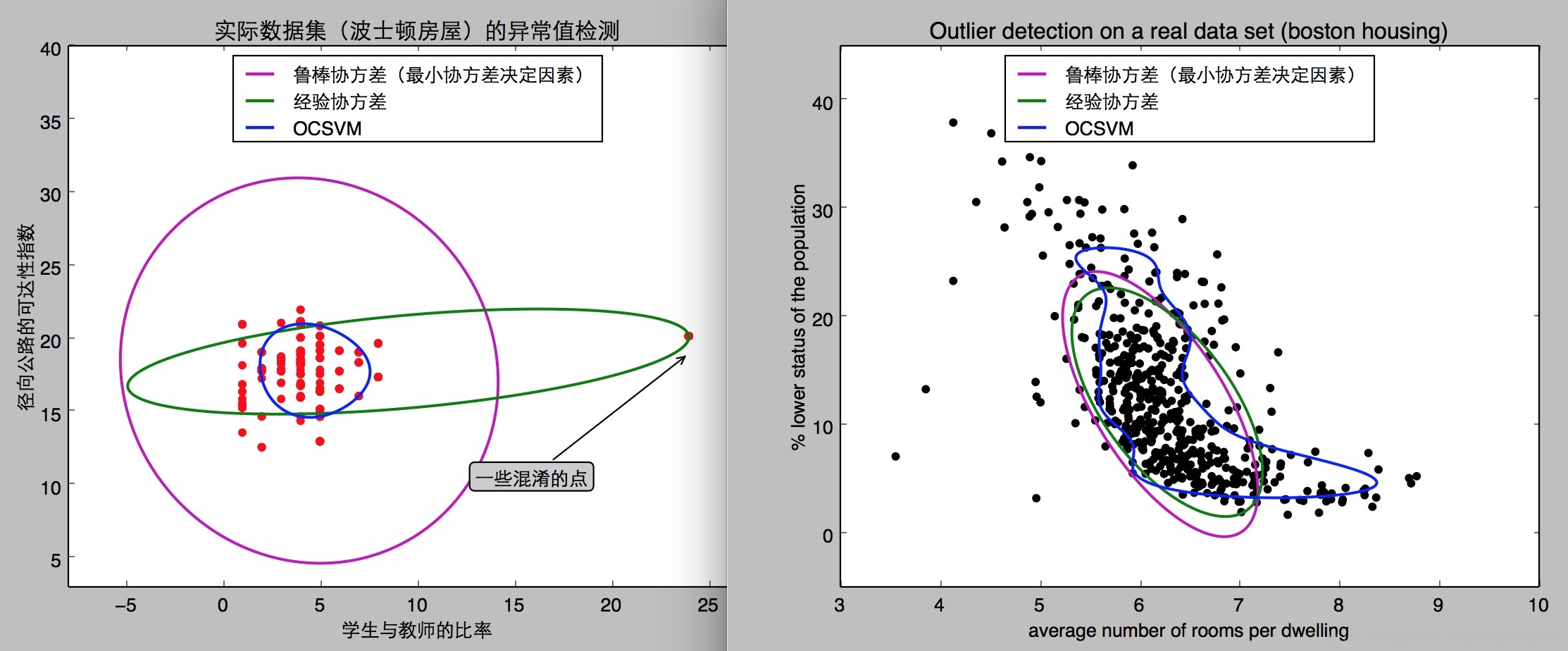
#coding:utf-8 import numpy as np from sklearn.covariance import EllipticEnvelope from sklearn.svm import OneClassSVM import matplotlib.pyplot as plt import matplotlib.font_manager from sklearn.datasets import load_boston ''' 機器學習 魯棒的基於高斯概率密度的異常點檢測(novelty detection) ellipticalenvelope演算法 演算法理解: 這個演算法的思想很好理解, 就是求出訓練集在空間中的重心, 和方差, 然後根據高斯概率密度估算每個點被分配到重心的概率. 資料說明: [ 0CRIM,城鎮人均犯罪率, 1ZN,佔地面積超過25,000平方呎的住宅用地比例, 2INDUS,每個城鎮非零售商業地的比例, 3,查爾斯河虛擬變數(= 1有河;否則為0), 4,一氧化氮濃度(百萬分之一), 5,每間住宅的平均客房數, 6,1940年之前建成的自用單位比例, 7,加權距離到五個波士頓就業中心, 8,徑向公路的可達性指數, 9,每10,000美元的稅賦全值財產稅率, 10,學生與教師的比率, 11,1000*(Bk-0.63)^2 其中Bk是城鎮中黑人的比例, 12,%降低人口狀態, 13,自住房價值在1000美元的中位數,[資料不包含該項] ] ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD','TAX', 'PTRATIO', 'B', 'LSTAT'] [0.00632, 18.0, 2.31, 0.0, 0.538, 6.575, 65.2, 4.09, 1.0, 296.0, 15.3, 396.9, 4.98] ''' # Get data #X1[徑向公路的可達性指數,學生與教師的比率,] X1 = load_boston()['data'][:, [8, 10]] # two clusters #X2[每間住宅的平均客房數,降低人口狀態,] X2 = load_boston()['data'][:, [5, 12]] # "banana"-shaped # Define "classifiers" to be used classifiers = { #EllipticEnvelope:一種用於在高斯分散式資料集中檢測異常值的物件。contamination:資料集的汙染量,即資料集中異常值的比例。 u"經驗協方差": EllipticEnvelope(support_fraction=1,contamination=0.261), #基於協方差的穩健估計,假設資料是高斯分佈的,那麼在這樣的案例中執行效果將優於One-Class SVM; u"魯棒協方差(最小協方差決定因素)":EllipticEnvelope(contamination=0.261), #SVM 利用One-Class SVM,它有能力捕獲資料集的形狀,因此對於強非高斯資料有更加優秀的效果,例如兩個截然分開的資料集; "OCSVM": OneClassSVM(nu=0.261, gamma=0.05)} colors = ['m', 'g', 'b'] legend1 = {} legend2 = {} # Learn a frontier for outlier detection with several classifiers xx1, yy1 = np.meshgrid(np.linspace(-8, 28, 500), np.linspace(3, 40, 500)) xx2, yy2 = np.meshgrid(np.linspace(3, 10, 500), np.linspace(-5, 45, 500)) for i, (clf_name, clf) in enumerate(classifiers.items()): plt.figure(1) clf.fit(X1) #decision_function 計算給定觀察的決策函式 #我們知道資料集中一部分的異常值。由此我們通過對decision_function設定閾值來分離出相應的部分,而不是使用'預測'方法。 Z1 = clf.decision_function(np.c_[xx1.ravel(), yy1.ravel()]) #reshape 將Z1矩陣轉換成 xx1的行列形式 Z1 = Z1.reshape(xx1.shape) #畫函式影象的 contour:表示繪製輪廓 使陣列的等值線圖。水平值自動選擇。 legend1[clf_name] = plt.contour(xx1, yy1, Z1, levels=[0], linewidths=2, colors=colors[i]) plt.figure(2) clf.fit(X2) Z2 = clf.decision_function(np.c_[xx2.ravel(), yy2.ravel()]) Z2 = Z2.reshape(xx2.shape) legend2[clf_name] = plt.contour(xx2, yy2, Z2, levels=[0], linewidths=2, colors=colors[i]) legend1_values_list = list(legend1.values()) legend1_keys_list = list(legend1.keys()) # Plot the results (= shape of the data points cloud) plt.figure(1) # two clusters plt.title(u"實際資料集(波士頓房屋)的異常值檢測") #畫點圖 plt.scatter(X1[:, 0], X1[:, 1], color='red') #設定註釋文字框 fc設定透明度 bbox_args = dict(boxstyle="round", fc="0.8") #arrow_args 表示使用箭頭線 arrow_args = dict(arrowstyle="->") #控制註解 xy=(24,19)表示箭頭的終點位置 xytext=(13, 10)註解文字框的位置 plt.annotate(u"一些混淆的點", xy=(24, 19),xycoords="data", textcoords="data",xytext=(13, 10), bbox=bbox_args, arrowprops=arrow_args) plt.xlim((xx1.min(), xx1.max())) plt.ylim((yy1.min(), yy1.max())) #loc 控制說明的擺放位置 plt.legend((legend1_values_list[0].collections[0], legend1_values_list[1].collections[0], legend1_values_list[2].collections[0]), (legend1_keys_list[0], legend1_keys_list[1], legend1_keys_list[2]), loc="upper center", prop=matplotlib.font_manager.FontProperties(size=12)) plt.ylabel(u"徑向公路的可達性指數") plt.xlabel(u"學生與教師的比率") legend2_values_list = list(legend2.values()) legend2_keys_list = list(legend2.keys()) plt.figure(2) # "banana" shape plt.title("Outlier detection on a real data set (boston housing)") plt.scatter(X2[:, 0], X2[:, 1], color='black') plt.xlim((xx2.min(), xx2.max())) plt.ylim((yy2.min(), yy2.max())) plt.legend((legend2_values_list[0].collections[0], legend2_values_list[1].collections[0], legend2_values_list[2].collections[0]), (legend2_keys_list[0], legend2_keys_list[1], legend2_keys_list[2]), loc="upper center", prop=matplotlib.font_manager.FontProperties(size=12)) plt.ylabel("% lower status of the population") plt.xlabel("average number of rooms per dwelling") plt.show()