
機器學習筆記(五)—— 邏輯迴歸
邏輯迴歸演算法是二分類問題中最常用的幾種分類演算法之一,通過變形,也能夠在多分類問題中發揮餘熱。今天我將從向大家揭開這個簡單演算法的神祕面紗!
一、Sigmoid函式
在迴歸問題中,我們曾經提到,對於資料集
,我們可以找到合適的係數
使其通過
來預測結果
。
邏輯迴歸的思路與迴歸演算法一致,我們需要找到一個合適的係數
,通過
來得到一個結果
,然後對
進行判斷,從而得到分類結果。因此,如果來判斷
便是邏輯迴歸最重要的一個點。
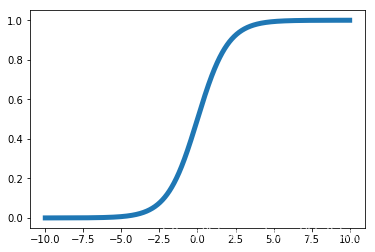
Sigmoid函式的
值分佈在
之間,它的函式表示式為
,影象如下圖所示。
也就是說,對於n維資料集
,如果我能夠找到合適的係數
,並將
代入Sigmoid函式中,使得結果
在
範圍內分佈,大小代表了樣本為正樣本的概率。例如
,說明該樣本有80%的可能性為正樣本,有20%的可能性為負樣本。通過這種方法,我們就能夠對樣本集進行二分類操作。
二、邏輯迴歸的損失函式
當我們確定好邏輯迴歸的模型 後,我們接下來的任務就是如何去評價這個模型的好壞,也就是找打一個損失函式,來表示預測的輸出 和訓練資料類別 之間的區別。
2.1 最大似然估計
假設對於給定的資料集
預測函式為:
則對對於輸入X其分類結果為1和為0的概率分別為:
(注:預設類別1為正類別)
即:
那麼基於最大似然估計,得到似然函式:
對數似然函式則為:
也就是說,如果我們希望
與
之間的差別最小,那麼我們需要使最大對數似然函式
取最大值,此時我們所求得的
就是我們所需要的係數。
所以我們的損失函式為: