
基於深度學習的推薦演算法實現(以MovieLens 1M資料 為例)
前言
本專案使用文字卷積神經網路,並使用MovieLens資料集完成電影推薦的任務。
推薦系統在日常的網路應用中無處不在,比如網上購物、網上買書、新聞app、社交網路、音樂網站、電影網站等等等等,有人的地方就有推薦。根據個人的喜好,相同喜好人群的習慣等資訊進行個性化的內容推薦。比如開啟新聞類的app,因為有了個性化的內容,每個人看到的新聞首頁都是不一樣的。
這當然是很有用的,在資訊爆炸的今天,獲取資訊的途徑和方式多種多樣,人們花費時間最多的不再是去哪獲取資訊,而是要在眾多的資訊中尋找自己感興趣的,這就是資訊超載問題。為了解決這個問題,推薦系統應運而生。
協同過濾是推薦系統應用較廣泛的技術,該方法蒐集使用者的歷史記錄、個人喜好等資訊,計算與其他使用者的相似度,利用相似使用者的評價來預測目標使用者對特定專案的喜好程度。優點是會給使用者推薦未瀏覽過的專案,缺點呢,對於新使用者來說,沒有任何與商品的互動記錄和個人喜好等資訊,存在冷啟動問題,導致模型無法找到相似的使用者或商品。
為了解決冷啟動的問題,通常的做法是對於剛註冊的使用者,要求使用者先選擇自己感興趣的話題、群組、商品、性格、喜歡的音樂型別等資訊,比如豆瓣FM:
先來看看資料
本專案使用的是MovieLens 1M 資料集,包含6000個使用者在近4000部電影上的1億條評論。
資料集分為三個檔案:使用者資料users.dat,電影資料movies.dat和評分資料ratings.dat。
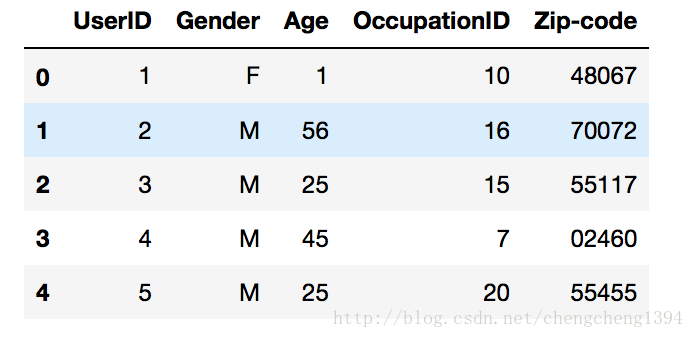
使用者資料
分別有使用者ID、性別、年齡、職業ID和郵編等欄位。
資料中的格式:UserID::Gender::Age::Occupation::Zip-code
- Gender is denoted by a “M” for male and “F” for female
-
Age is chosen from the following ranges:
- 1: “Under 18”
- 18: “18-24”
- 25: “25-34”
- 35: “35-44”
- 45: “45-49”
- 50: “50-55”
- 56: “56+”
-
Occupation is chosen from the following choices:
- 0: “other” or not specified
- 1: “academic/educator”
- 2: “artist”
- 3: “clerical/admin”
- 4: “college/grad student”
- 5: “customer service”
- 6: “doctor/health care”
- 7: “executive/managerial”
- 8: “farmer”
- 9: “homemaker”
- 10: “K-12 student”
- 11: “lawyer”
- 12: “programmer”
- 13: “retired”
- 14: “sales/marketing”
- 15: “scientist”
- 16: “self-employed”
- 17: “technician/engineer”
- 18: “tradesman/craftsman”
- 19: “unemployed”
- 20: “writer”
其中UserID、Gender、Age和Occupation都是類別欄位,其中郵編欄位是我們不使用的。
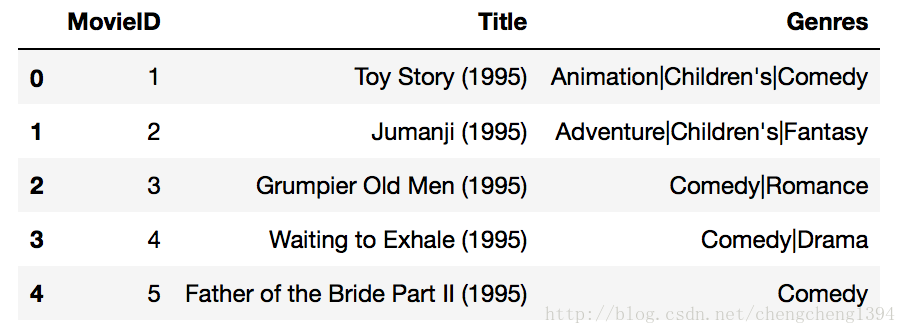
電影資料
分別有電影ID、電影名和電影風格等欄位。
資料中的格式:MovieID::Title::Genres
- Titles are identical to titles provided by the IMDB (including
year of release) -
Genres are pipe-separated and are selected from the following genres:
- Action
- Adventure
- Animation
- Children’s
- Comedy
- Crime
- Documentary
- Drama
- Fantasy
- Film-Noir
- Horror
- Musical
- Mystery
- Romance
- Sci-Fi
- Thriller
- War
- Western
MovieID是類別欄位,Title是文字,Genres也是類別欄位
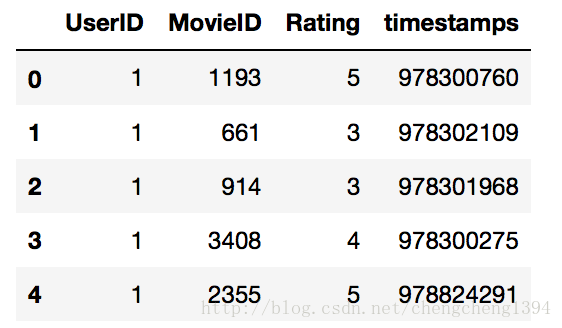
評分資料
分別有使用者ID、電影ID、評分和時間戳等欄位。
資料中的格式:UserID::MovieID::Rating::Timestamp
- UserIDs range between 1 and 6040
- MovieIDs range between 1 and 3952
- Ratings are made on a 5-star scale (whole-star ratings only)
- Timestamp is represented in seconds since the epoch as returned by time(2)
- Each user has at least 20 ratings
評分欄位Rating就是我們要學習的targets,時間戳欄位我們不使用。
說說資料預處理
- UserID、Occupation和MovieID不用變。
- Gender欄位:需要將‘F’和‘M’轉換成0和1。
- Age欄位:要轉成7個連續數字0~6。
- Genres欄位:是分類欄位,要轉成數字。首先將Genres中的類別轉成字串到數字的字典,然後再將每個電影的Genres欄位轉成數字列表,因為有些電影是多個Genres的組合。
- Title欄位:處理方式跟Genres欄位一樣,首先建立文字到數字的字典,然後將Title中的描述轉成數字的列表。另外Title中的年份也需要去掉。
- Genres和Title欄位需要將長度統一,這樣在神經網路中方便處理。空白部分用‘< PAD >’對應的數字填充。
資料預處理的程式碼可以在專案中找到:load_data函式
模型設計
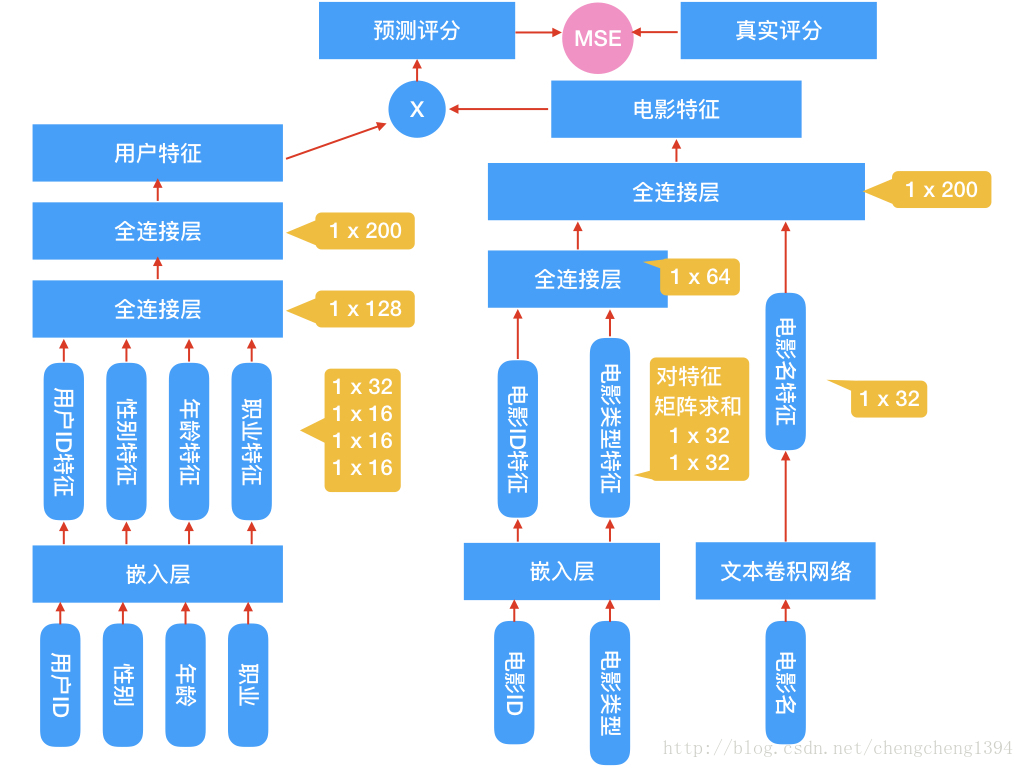
通過研究資料集中的欄位型別,我們發現有一些是類別欄位,通常的處理是將這些欄位轉成one hot編碼,但是像UserID、MovieID這樣的欄位就會變成非常的稀疏,輸入的維度急劇膨脹,這是我們不願意見到的,畢竟我這小筆記本不像大廠動輒能處理數以億計維度的輸入:)
所以在預處理資料時將這些欄位轉成了數字,我們用這個數字當做嵌入矩陣的索引,在網路的第一層使用了嵌入層,維度是(N,32)和(N,16)。
電影型別的處理要多一步,有時一個電影有多個電影型別,這樣從嵌入矩陣索引出來是一個(n,32)的矩陣,因為有多個型別嘛,我們要將這個矩陣求和,變成(1,32)的向量。
電影名的處理比較特殊,沒有使用迴圈神經網路,而是用了文字卷積網路,下文會進行說明。
從嵌入層索引出特徵以後,將各特徵傳入全連線層,將輸出再次傳入全連線層,最終分別得到(1,200)的使用者特徵和電影特徵兩個特徵向量。
我們的目的就是要訓練出使用者特徵和電影特徵,在實現推薦功能時使用。得到這兩個特徵以後,就可以選擇任意的方式來擬合評分了。我使用了兩種方式,一個是上圖中畫出的將兩個特徵做向量乘法,將結果與真實評分做迴歸,採用MSE優化損失。因為本質上這是一個迴歸問題,另一種方式是,將兩個特徵作為輸入,再次傳入全連線層,輸出一個值,將輸出值迴歸到真實評分,採用MSE優化損失。
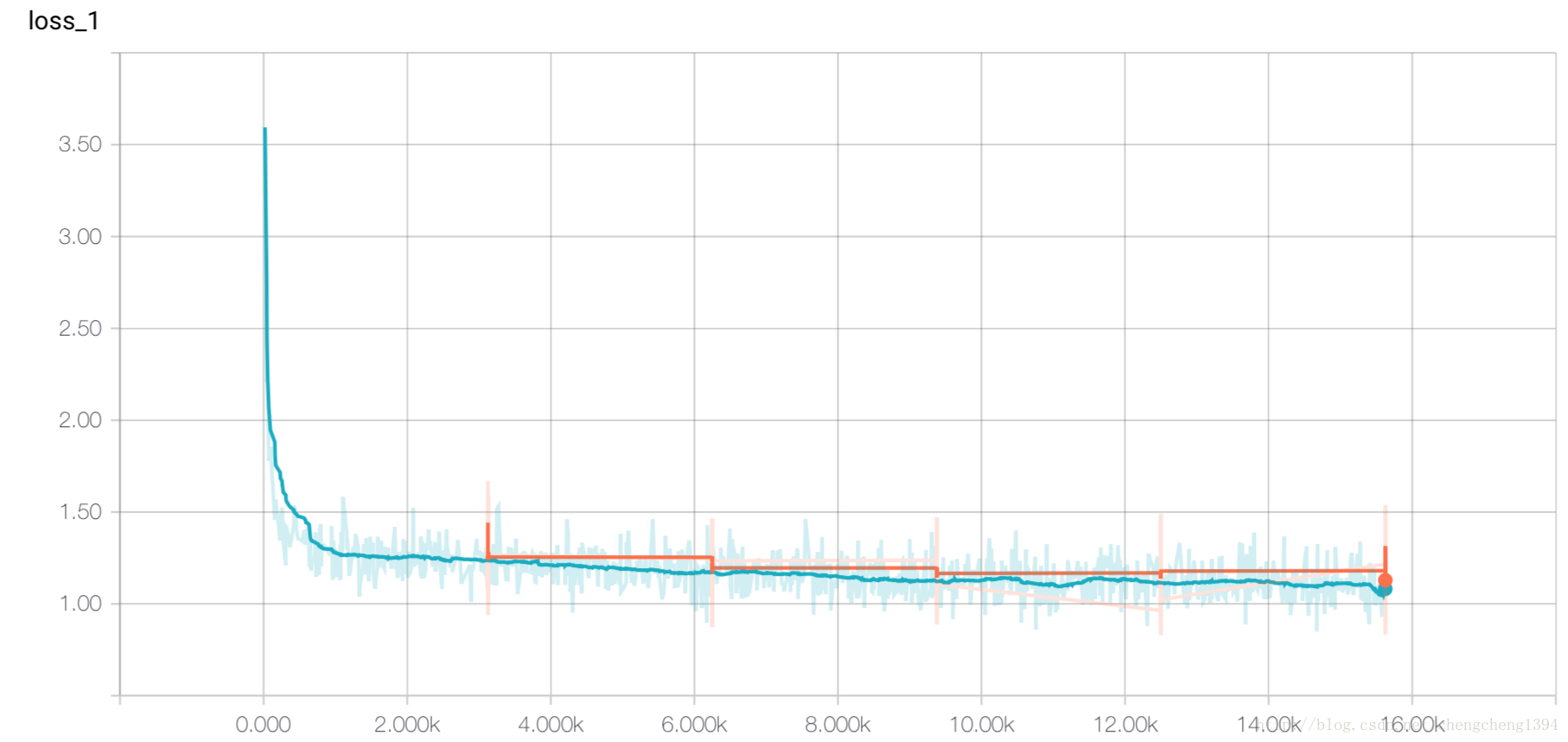
實際上第二個方式的MSE loss在0.8附近,第一個方式在1附近,5次迭代的結果。
文字卷積網路
將卷積神經網路用於文字的文章建議你閱讀Understanding
Convolutional Neural Networks for NLP
網路的第一層是詞嵌入層,由每一個單詞的嵌入向量組成的嵌入矩陣。下一層使用多個不同尺寸(視窗大小)的卷積核在嵌入矩陣上做卷積,視窗大小指的是每次卷積覆蓋幾個單詞。這裡跟對影象做卷積不太一樣,影象的卷積通常用2x2、3x3、5x5之類的尺寸,而文字卷積要覆蓋整個單詞的嵌入向量,所以尺寸是(單詞數,向量維度),比如每次滑動3個,4個或者5個單詞。第三層網路是max pooling得到一個長向量,最後使用dropout做正則化,最終得到了電影Title的特徵。
核心程式碼講解
完整程式碼請見專案
#嵌入矩陣的維度
embed_dim = 32
#使用者ID個數
uid_max = max(features.take(0,1)) + 1 # 6040
#性別個數
gender_max = max(features.take(2,1)) + 1 # 1 + 1 = 2
#年齡類別個數
age_max = max(features.take(3,1)) + 1 # 6 + 1 = 7
#職業個數
job_max = max(features.take(4,1)) + 1# 20 + 1 = 21
#電影ID個數
movie_id_max = max(features.take(1,1)) + 1 # 3952
#電影型別個數
movie_categories_max = max(genres2int.values()) + 1 # 18 + 1 = 19
#電影名單詞個數
movie_title_max = len(title_set) # 5216
#對電影型別嵌入向量做加和操作的標誌,考慮過使用mean做平均,但是沒實現mean
combiner = "sum"
#電影名長度
sentences_size = title_count # = 15
#文字卷積滑動視窗,分別滑動2, 3, 4, 5個單詞
window_sizes = {2, 3, 4, 5}
#文字卷積核數量
filter_num = 8
#電影ID轉下標的字典,資料集中電影ID跟下標不一致,比如第5行的資料電影ID不一定是5
movieid2idx = {val[0]:i for i, val in enumerate(movies.values)}超參
# Number of Epochs
num_epochs = 5
# Batch Size
batch_size = 256
dropout_keep = 0.5
# Learning Rate
learning_rate = 0.0001
# Show stats for every n number of batches
show_every_n_batches = 20
save_dir = './save'輸入
定義輸入的佔位符
def get_inputs():
uid = tf.placeholder(tf.int32, [None, 1], name="uid")
user_gender = tf.placeholder(tf.int32, [None, 1], name="user_gender")
user_age = tf.placeholder(tf.int32, [None, 1], name="user_age")
user_job = tf.placeholder(tf.int32, [None, 1], name="user_job")
movie_id = tf.placeholder(tf.int32, [None, 1], name="movie_id")
movie_categories = tf.placeholder(tf.int32, [None, 18], name="movie_categories")
movie_titles = tf.placeholder(tf.int32, [None, 15], name="movie_titles")
targets = tf.placeholder(tf.int32, [None, 1], name="targets")
LearningRate = tf.placeholder(tf.float32, name = "LearningRate")
dropout_keep_prob = tf.placeholder(tf.float32, name = "dropout_keep_prob")
return uid, user_gender, user_age, user_job, movie_id, movie_categories, movie_titles, targets, LearningRate, dropout_keep_prob構建神經網路
定義User的嵌入矩陣
def get_user_embedding(uid, user_gender, user_age, user_job):
with tf.name_scope("user_embedding"):
uid_embed_matrix = tf.Variable(tf.random_uniform([uid_max, embed_dim], -1, 1), name = "uid_embed_matrix")
uid_embed_layer = tf.nn.embedding_lookup(uid_embed_matrix, uid, name = "uid_embed_layer")
gender_embed_matrix = tf.Variable(tf.random_uniform([gender_max, embed_dim // 2], -1, 1), name= "gender_embed_matrix")
gender_embed_layer = tf.nn.embedding_lookup(gender_embed_matrix, user_gender, name = "gender_embed_layer")
age_embed_matrix = tf.Variable(tf.random_uniform([age_max, embed_dim // 2], -1, 1), name="age_embed_matrix")
age_embed_layer = tf.nn.embedding_lookup(age_embed_matrix, user_age, name="age_embed_layer")
job_embed_matrix = tf.Variable(tf.random_uniform([job_max, embed_dim // 2], -1, 1), name = "job_embed_matrix")
job_embed_layer = tf.nn.embedding_lookup(job_embed_matrix, user_job, name = "job_embed_layer")
return uid_embed_layer, gender_embed_layer, age_embed_layer, job_embed_layer將User的嵌入矩陣一起全連線生成User的特徵
def get_user_feature_layer(uid_embed_layer, gender_embed_layer, age_embed_layer, job_embed_layer):
with tf.name_scope("user_fc"):
#第一層全連線
uid_fc_layer = tf.layers.dense(uid_embed_layer, embed_dim, name = "uid_fc_layer", activation=tf.nn.relu)
gender_fc_layer = tf.layers.dense(gender_embed_layer, embed_dim, name = "gender_fc_layer", activation=tf.nn.relu)
age_fc_layer = tf.layers.dense(age_embed_layer, embed_dim, name ="age_fc_layer", activation=tf.nn.relu)
job_fc_layer = tf.layers.dense(job_embed_layer, embed_dim, name = "job_fc_layer", activation=tf.nn.relu)
#第二層全連線
user_combine_layer = tf.concat([uid_fc_layer, gender_fc_layer, age_fc_layer, job_fc_layer], 2) #(?, 1, 128)
user_combine_layer = tf.contrib.layers.fully_connected(user_combine_layer, 200, tf.tanh) #(?, 1, 200)
user_combine_layer_flat = tf.reshape(user_combine_layer, [-1, 200])
return user_combine_layer, user_combine_layer_flat定義Movie ID的嵌入矩陣
def get_movie_id_embed_layer(movie_id):
with tf.name_scope("movie_embedding"):
movie_id_embed_matrix = tf.Variable(tf.random_uniform([movie_id_max, embed_dim], -1, 1), name = "movie_id_embed_matrix")
movie_id_embed_layer = tf.nn.embedding_lookup(movie_id_embed_matrix, movie_id, name = "movie_id_embed_layer")
return movie_id_embed_layer對電影型別的多個嵌入向量做加和
def get_movie_categories_layers(movie_categories):
with tf.name_scope("movie_categories_layers"):
movie_categories_embed_matrix = tf.Variable(tf.random_uniform([movie_categories_max, embed_dim], -1, 1), name = "movie_categories_embed_matrix")
movie_categories_embed_layer = tf.nn.embedding_lookup(movie_categories_embed_matrix, movie_categories, name = "movie_categories_embed_layer")
if combiner == "sum":
movie_categories_embed_layer = tf.reduce_sum(movie_categories_embed_layer, axis=1, keep_dims=True)
# elif combiner == "mean":
return movie_categories_embed_layerMovie Title的文字卷積網路實現
def get_movie_cnn_layer(movie_titles):
#從嵌入矩陣中得到電影名對應的各個單詞的嵌入向量
with tf.name_scope("movie_embedding"):
movie_title_embed_matrix = tf.Variable(tf.random_uniform([movie_title_max, embed_dim], -1, 1), name = "movie_title_embed_matrix")
movie_title_embed_layer = tf.nn.embedding_lookup(movie_title_embed_matrix, movie_titles, name = "movie_title_embed_layer")
movie_title_embed_layer_expand = tf.expand_dims(movie_title_embed_layer, -1)
#對文字嵌入層使用不同尺寸的卷積核做卷積和最大池化
pool_layer_lst = []
for window_size in window_sizes:
with tf.name_scope("movie_txt_conv_maxpool_{}".format(window_size)):
filter_weights = tf.Variable(tf.truncated_normal([window_size, embed_dim, 1, filter_num],stddev=0.1),name = "filter_weights")
filter_bias = tf.Variable(tf.constant(0.1, shape=[filter_num]), name="filter_bias")
conv_layer = tf.nn.conv2d(movie_title_embed_layer_expand, filter_weights, [1,1,1,1], padding="VALID", name="conv_layer")
relu_layer = tf.nn.relu(tf.nn.bias_add(conv_layer,filter_bias), name ="relu_layer")
maxpool_layer = tf.nn.max_pool(relu_layer, [1,sentences_size - window_size + 1 ,1,1], [1,1,1,1], padding="VALID", name="maxpool_layer")
pool_layer_lst.append(maxpool_layer)
#Dropout層
with tf.name_scope("pool_dropout"):
pool_layer = tf.concat(pool_layer_lst, 3, name ="pool_layer")
max_num = len(window_sizes) * filter_num
pool_layer_flat = tf.reshape(pool_layer , [-1, 1, max_num], name = "pool_layer_flat")
dropout_layer = tf.nn.dropout(pool_layer_flat, dropout_keep_prob, name = "dropout_layer")
return pool_layer_flat, dropout_layer將Movie的各個層一起做全連線
def get_movie_feature_layer(movie_id_embed_layer, movie_categories_embed_layer, dropout_layer):
with tf.name_scope("movie_fc"):
#第一層全連線
movie_id_fc_layer = tf.layers.dense(movie_id_embed_layer, embed_dim, name = "movie_id_fc_layer", activation=tf.nn.relu)
movie_categories_fc_layer = tf.layers.dense(movie_categories_embed_layer, embed_dim, name = "movie_categories_fc_layer", activation=tf.nn.relu)
#第二層全連線
movie_combine_layer = tf.concat([movie_id_fc_layer, movie_categories_fc_layer, dropout_layer], 2) #(?, 1, 96)
movie_combine_layer = tf.contrib.layers.fully_connected(movie_combine_layer, 200, tf.tanh) #(?, 1, 200)
movie_combine_layer_flat = tf.reshape(movie_combine_layer, [-1, 200])
return movie_combine_layer, movie_combine_layer_flat構建計算圖
tf.reset_default_graph()
train_graph = tf.Graph()
with train_graph.as_default():
#獲取輸入佔位符
uid, user_gender, user_age, user_job, movie_id, movie_categories, movie_titles, targets, lr, dropout_keep_prob = get_inputs()
#獲取User的4個嵌入向量
uid_embed_layer, gender_embed_layer, age_embed_layer, job_embed_layer = get_user_embedding(uid, user_gender, user_age, user_job)
#得到使用者特徵
user_combine_layer, user_combine_layer_flat = get_user_feature_layer(uid_embed_layer, gender_embed_layer, age_embed_layer, job_embed_layer)
#獲取電影ID的嵌入向量
movie_id_embed_layer = get_movie_id_embed_layer(movie_id)
#獲取電影型別的嵌入向量
movie_categories_embed_layer = get_movie_categories_layers(movie_categories)
#獲取電影名的特徵向量
pool_layer_flat, dropout_layer = get_movie_cnn_layer(movie_titles)
#得到電影特徵
movie_combine_layer, movie_combine_layer_flat = get_movie_feature_layer(movie_id_embed_layer,
movie_categories_embed_layer,
dropout_layer)
#計算出評分,要注意兩個不同的方案,inference的名字(name值)是不一樣的,後面做推薦時要根據name取得tensor
with tf.name_scope("inference"):
#將使用者特徵和電影特徵作為輸入,經過全連線,輸出一個值的方案
# inference_layer = tf.concat([user_combine_layer_flat, movie_combine_layer_flat], 1) #(?, 200)
# inference = tf.layers.dense(inference_layer, 1,
# kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
# kernel_regularizer=tf.nn.l2_loss, name="inference")
#簡單的將使用者特徵和電影特徵做矩陣乘法得到一個預測評分
inference = tf.matmul(user_combine_layer_flat, tf.transpose(movie_combine_layer_flat))
with tf.name_scope("loss"):
# MSE損失,將計算值迴歸到評分
cost = tf.losses.mean_squared_error(targets, inference )
loss = tf.reduce_mean(cost)
# 優化損失
# train_op = tf.train.AdamOptimizer(lr).minimize(loss) #cost
global_step = tf.Variable(0, name="global_step", trainable=False)
optimizer = tf.train.AdamOptimizer(lr)
gradients = optimizer.compute_gradients(loss) #cost
train_op = optimizer.apply_gradients(gradients, global_step=global_step)訓練網路
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import matplotlib.pyplot as plt
import time
import datetime
losses = {'train':[], 'test':[]}
with tf.Session(graph=train_graph) as sess:
#蒐集資料給tensorBoard用
# Keep track of gradient values and sparsity
grad_summaries = []
for g, v in gradients:
if g is not None:
grad_hist_summary = tf.summary.histogram("{}/grad/hist".format(v.name.replace(':', '_')), g)
sparsity_summary = tf.summary.scalar("{}/grad/sparsity".format(v.name.replace(':', '_')), tf.nn.zero_fraction(g))
grad_summaries.append(grad_hist_summary)
grad_summaries.append(sparsity_summary)
grad_summaries_merged = tf.summary.merge(grad_summaries)
# Output directory for models and summaries
timestamp = str(int(time.time()))
out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
print("Writing to {}\n".format(out_dir))
# Summaries for loss and accuracy
loss_summary = tf.summary.scalar("loss", loss)
# Train Summaries
train_summary_op = tf.summary.merge([loss_summary, grad_summaries_merged])
train_summary_dir = os.path.join(out_dir, "summaries", "train")
train_summary_writer = tf.summary.FileWriter(train_summary_dir, sess.graph)
# Inference summaries
inference_summary_op = tf.summary.merge([loss_summary])
inference_summary_dir = os.path.join(out_dir, "summaries", "inference")
inference_summary_writer = tf.summary.FileWriter(inference_summary_dir, sess.graph)
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
for epoch_i in range(num_epochs):
#將資料集分成訓練集和測試集,隨機種子不固定
train_X,test_X, train_y, test_y = train_test_split(features,
targets_values,
test_size = 0.2,
random_state = 0)
train_batches = get_batches(train_X, train_y, batch_size)
test_batches = get_batches(test_X, test_y, batch_size)
#訓練的迭代,儲存訓練損失
for batch_i in range(len(train_X) // batch_size):
x, y = next(train_batches)
categories = np.zeros([batch_size, 18])
for i in range(batch_size):
categories[i] = x.take(6,1)[i]
titles = np.zeros([batch_size, sentences_size])
for i in range(batch_size):
titles[i] = x.take(5,1)[i]
feed = {
uid: np.reshape(x.take(0,1), [batch_size, 1]),
user_gender: np.reshape(x.take(2,1), [batch_size, 1]),
user_age: np.reshape(x.take(3,1), [batch_size, 1]),
user_job: np.reshape(x.take(4,1), [batch_size, 1]),
movie_id: np.reshape(x.take(1,1), [batch_size, 1]),
movie_categories: categories, #x.take(6,1)
movie_titles: titles, #x.take(5,1)
targets: np.reshape(y, [batch_size, 1]),
dropout_keep_prob: dropout_keep, #dropout_keep
lr: learning_rate}
step, train_loss, summaries, _ = sess.run([global_step, loss, train_summary_op, train_op], feed) #cost
losses['train'].append(train_loss)
train_summary_writer.add_summary(summaries, step) #
# Show every <show_every_n_batches> batches
if (epoch_i * (len(train_X) // batch_size) + batch_i) % show_every_n_batches == 0:
time_str = datetime.datetime.now().isoformat()
print('{}: Epoch {:>3} Batch {:>4}/{} train_loss = {:.3f}'.format(
time_str,
epoch_i,
batch_i,
(len(train_X) // batch_size),
train_loss))
#使用測試資料的迭代
for batch_i in range(len(test_X) // batch_size):
x, y = next(test_batches)
categories = np.zeros([batch_size, 18])
for i in range(batch_size):
categories[i] = x.take(6,1)[i]
titles = np.zeros([batch_size, sentences_size])
for i in range(batch_size):
titles[i] = x.take(5,1)[i]
feed = {
uid: np.reshape(x.take(0,1), [batch_size, 1]),
user_gender: np.reshape(x.take(2,1), [batch_size, 1]),
user_age: np.reshape(x.take(3,1), [batch_size, 1]),
user_job: np.reshape(x.take(4,1), [batch_size, 1]),
movie_id: np.reshape(x.take(1,1), [batch_size, 1]),
movie_categories: categories, #x.take(6,1)
movie_titles: titles, #x.take(5,1)
targets: np.reshape(y, [batch_size, 1]),
dropout_keep_prob: 1,
lr: learning_rate}
step, test_loss, summaries = sess.run([global_step, loss, inference_summary_op], feed) #cost
#儲存測試損失
losses['test'].append(test_loss)
inference_summary_writer.add_summary(summaries, step) #
time_str = datetime.datetime.now().isoformat()
if (epoch_i * (len(test_X) // batch_size) + batch_i) % show_every_n_batches == 0:
print('{}: Epoch {:>3} Batch {:>4}/{} test_loss = {:.3f}'.format(
time_str,
epoch_i,
batch_i,
(len(test_X) // batch_size),
test_loss))
# Save Model
saver.save(sess, save_dir) #, global_step=epoch_i
print('Model Trained and Saved')在 TensorBoard 中檢視視覺化結果
獲取 Tensors
def get_tensors(loaded_graph):
uid = loaded_graph.get_tensor_by_name("uid:0")
user_gender = loaded_graph.get_tensor_by_name("user_gender:0")
user_age = loaded_graph.get_tensor_by_name("user_age:0")
user_job = loaded_graph.get_tensor_by_name("user_job:0")
movie_id = loaded_graph.get_tensor_by_name("movie_id:0")
movie_categories = loaded_graph.get_tensor_by_name("movie_categories:0")
movie_titles = loaded_graph.get_tensor_by_name("movie_titles:0")
targets = loaded_graph.get_tensor_by_name("targets:0")
dropout_keep_prob = loaded_graph.get_tensor_by_name("dropout_keep_prob:0")
lr = loaded_graph.get_tensor_by_name("LearningRate:0")
#兩種不同計算預測評分的方案使用不同的name獲取tensor inference
# inference = loaded_graph.get_tensor_by_name("inference/inference/BiasAdd:0")
inference = loaded_graph.get_tensor_by_name("inference/MatMul:0")#
movie_combine_layer_flat = loaded_graph.get_tensor_by_name("movie_fc/Reshape:0")
user_combine_layer_flat = loaded_graph.get_tensor_by_name("user_fc/Reshape:0")
return uid, user_gender, user_age, user_job, movie_id, movie_categories, movie_titles, targets, lr, dropout_keep_prob, inference, movie_combine_layer_flat, user_combine_layer_flat指定使用者和電影進行評分
這部分就是對網路做正向傳播,計算得到預測的評分
def rating_movie(user_id_val, movie_id_val):
loaded_graph = tf.Graph() #
with tf.Session(graph=loaded_graph) as sess: #
# Load saved model
loader = tf.train.import_meta_graph(load_dir + '.meta')
loader.restore(sess, load_dir)
# Get Tensors from loaded model
uid, user_gender, user_age, user_job, movie_id, movie_categories, movie_titles, targets, lr, dropout_keep_prob, inference,_, __ = get_tensors(loaded_graph) #loaded_graph
categories = np.zeros([1, 18])
categories[0] = movies.values[movieid2idx[movie_id_val]][2]
titles = np.zeros([1, sentences_size])
titles[0] = movies.values[movieid2idx[movie_id_val]][1]
feed = {
uid: np.reshape(users.values[user_id_val-1][0], [1, 1]),
user_gender: np.reshape(users.values[user_id_val-1][1], [1, 1]),
user_age: np.reshape(users.values[user_id_val-1][2], [1, 1]),
user_job: np.reshape(users.values[user_id_val-1][3], [1, 1]),
movie_id: np.reshape(movies.values[movieid2idx[movie_id_val]][0], [1, 1]),
movie_categories: categories, #x.take(6,1)
movie_titles: titles, #x.take(5,1)
dropout_keep_prob: 1}
# Get Prediction
inference_val = sess.run([inference], feed)
return (inference_val)

生成Movie特徵矩陣
將訓練好的電影特徵組合成電影特徵矩陣並儲存到本地
loaded_graph = tf.Graph() #
movie_matrics = []
with tf.Session(graph=loaded_graph) as sess: #
# Load saved model
loader = tf.train.import_meta_graph(load_dir + '.meta')
loader.restore(sess, load_dir)
# Get Tensors from loaded model
uid, user_gender, user_age, user_job, movie_id, movie_categories, movie_titles, targets, lr, dropout_keep_prob, _, movie_combine_layer_flat, __ = get_tensors(loaded_graph) #loaded_graph
for item in movies.values:
categories = np.zeros([1, 18])
categories[0] = item.take(2)
titles = np.zeros([1, sentences_size])
titles[0] = item.take(1)
feed = {
movie_id: np.reshape(item.take(0), [1, 1]),
movie_categories: categories, #x.take(6,1)
movie_titles: titles, #x.take(5,1)
dropout_keep_prob: 1}
movie_combine_layer_flat_val = sess.run([movie_combine_layer_flat], feed)
movie_matrics.append(movie_combine_layer_flat_val)
pickle.dump((np.array(movie_matrics).reshape(-1, 200)), open('movie_matrics.p', 'wb'))
movie_matrics = pickle.load(open('movie_matrics.p', mode='rb'))生成User特徵矩陣
將訓練好的使用者特徵組合成使用者特徵矩陣並儲存到本地
loaded_graph = tf.Graph() #
users_matrics = []
with tf.Session(graph=loaded_graph) as sess: #
# Load saved model
loader = tf.train.import_meta_graph(load_dir + '.meta')
loader.restore(sess, load_dir)
# Get Tensors from loaded model
uid, user_gender, user_age, user_job, movie_id, movie_categories, movie_titles, targets, lr, dropout_keep_prob, _, __,user_combine_layer_flat = get_tensors(loaded_graph) #loaded_graph
for item in users.values:
feed = {
uid: np.reshape(item.take(0), [1, 1]),
user_gender: np.reshape(item.take(1), [1, 1]),
user_age: np.reshape(item.take(2), [1, 1]),
user_job: np.reshape(item.take(3), [1, 1]),
dropout_keep_prob: 1}
user_combine_layer_flat_val = sess.run([user_combine_layer_flat], feed)
users_matrics.append(user_combine_layer_flat_val)
pickle.dump((np.array(users_matrics).reshape(-1, 200)), open('users_matrics.p', 'wb'))
users_matrics = pickle.load(open('users_matrics.p', mode='rb'))開始推薦電影
使用生產的使用者特徵矩陣和電影特徵矩陣做電影推薦
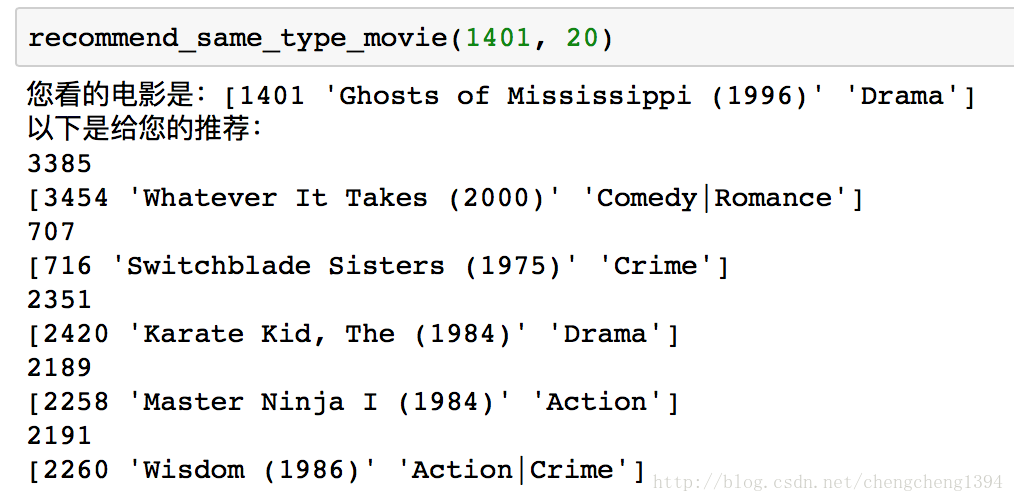
推薦同類型的電影
思路是計算當前看的電影特徵向量與整個電影特徵矩陣的餘弦相似度,取相似度最大的top_k個,這裡加了些隨機選擇在裡面,保證每次的推薦稍稍有些不同。
def recommend_same_type_movie(movie_id_val, top_k = 20):
loaded_graph = tf.Graph() #
with tf.Session(graph=loaded_graph) as sess: #
# Load saved model
loader = tf.train.import_meta_graph(load_dir + '.meta')
loader.restore(sess, load_dir)
norm_movie_matrics = tf.sqrt(tf.reduce_sum(tf.square(movie_matrics), 1, keep_dims=True))
normalized_movie_matrics = movie_matrics / norm_movie_matrics
#推薦同類型的電影
probs_embeddings = (movie_matrics[movieid2idx[movie_id_val]]).reshape([1, 200])
probs_similarity = tf.matmul(probs_embeddings, tf.transpose(normalized_movie_matrics))
sim = (probs_similarity.eval())
# results = (-sim[0]).argsort()[0:top_k]
# print(results)
print("您看的電影是:{}".format(movies_orig[movieid2idx[movie_id_val]]))
print("以下是給您的推薦:")
p = np.squeeze(sim)
p[np.argsort(p)[:-top_k]] = 0
p = p / np.sum(p)
results = set()
while len(results) != 5:
c = np.random.choice(3883, 1, p=p)[0]
results.add(c)
for val in (results):
print(val)
print(movies_orig[val])
return results
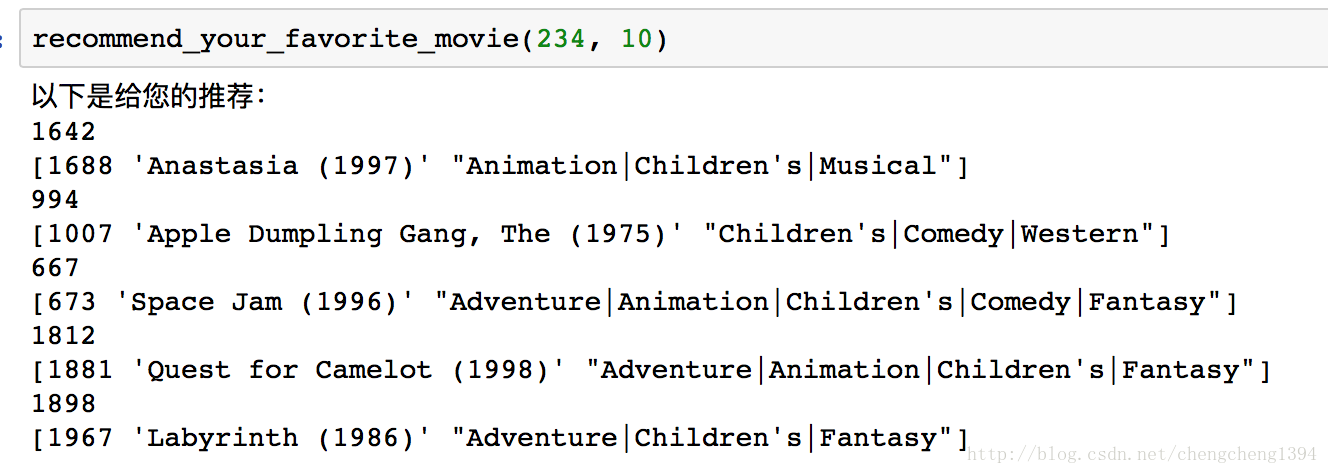
推薦您喜歡的電影
思路是使用使用者特徵向量與電影特徵矩陣計算所有電影的評分,取評分最高的top_k個,同樣加了些隨機選擇部分。
def recommend_your_favorite_movie(user_id_val, top_k = 10):
loaded_graph = tf.Graph() #
with tf.Session(graph=loaded_graph) as sess: #
# Load saved model
loader = tf.train.import_meta_graph(load_dir + '.meta')
loader.restore(sess, load_dir)
#推薦您喜歡的電影
probs_embeddings = (users_matrics[user_id_val-1]).reshape([1, 200])
probs_similarity = tf.matmul(probs_embeddings, tf.transpose(movie_matrics))
sim = (probs_similarity.eval())
# print(sim.shape)
# results = (-sim[0]).argsort()[0:top_k]
# print(results)
# sim_norm = probs_norm_similarity.eval()
# print((-sim_norm[0]).argsort()[0:top_k])
print("以下是給您的推薦:")
p = np.squeeze(sim)
p[np.argsort(p)[:-top_k]] = 0
p = p / np.sum(p)
results = set()
while len(results) != 5:
c = np.random.choice(3883, 1, p=p)[0]
results.add(c)
for val in (results):
print(val)
print(movies_orig[val])
return results
看過這個電影的人還看了(喜歡)哪些電影
- 首先選出喜歡某個電影的top_k個人,得到這幾個人的使用者特徵向量。
- 然後計算這幾個人對所有電影的評分
- 選擇每個人評分最高的電影作為推薦
- 同樣加入了隨機選擇
import random
def recommend_other_favorite_movie(movie_id_val, top_k = 20):
loaded_graph = tf.Graph() #
with tf.Session(graph=loaded_graph) as sess: #
# Load saved model
loader = tf.train.import_meta_graph(load_dir + '.meta')
loader.restore(sess, load_dir)
probs_movie_embeddings = (movie_matrics[movieid2idx[movie_id_val]]).reshape([1, 200])
probs_user_favorite_similarity = tf.matmul(probs_movie_embeddings, tf.transpose(users_matrics))
favorite_user_id = np.argsort(probs_user_favorite_similarity.eval())[0][-top_k:]
# print(normalized_users_matrics.eval().shape)
# print(probs_user_favorite_similarity.eval()[0][favorite_user_id])
# print(favorite_user_id.shape)
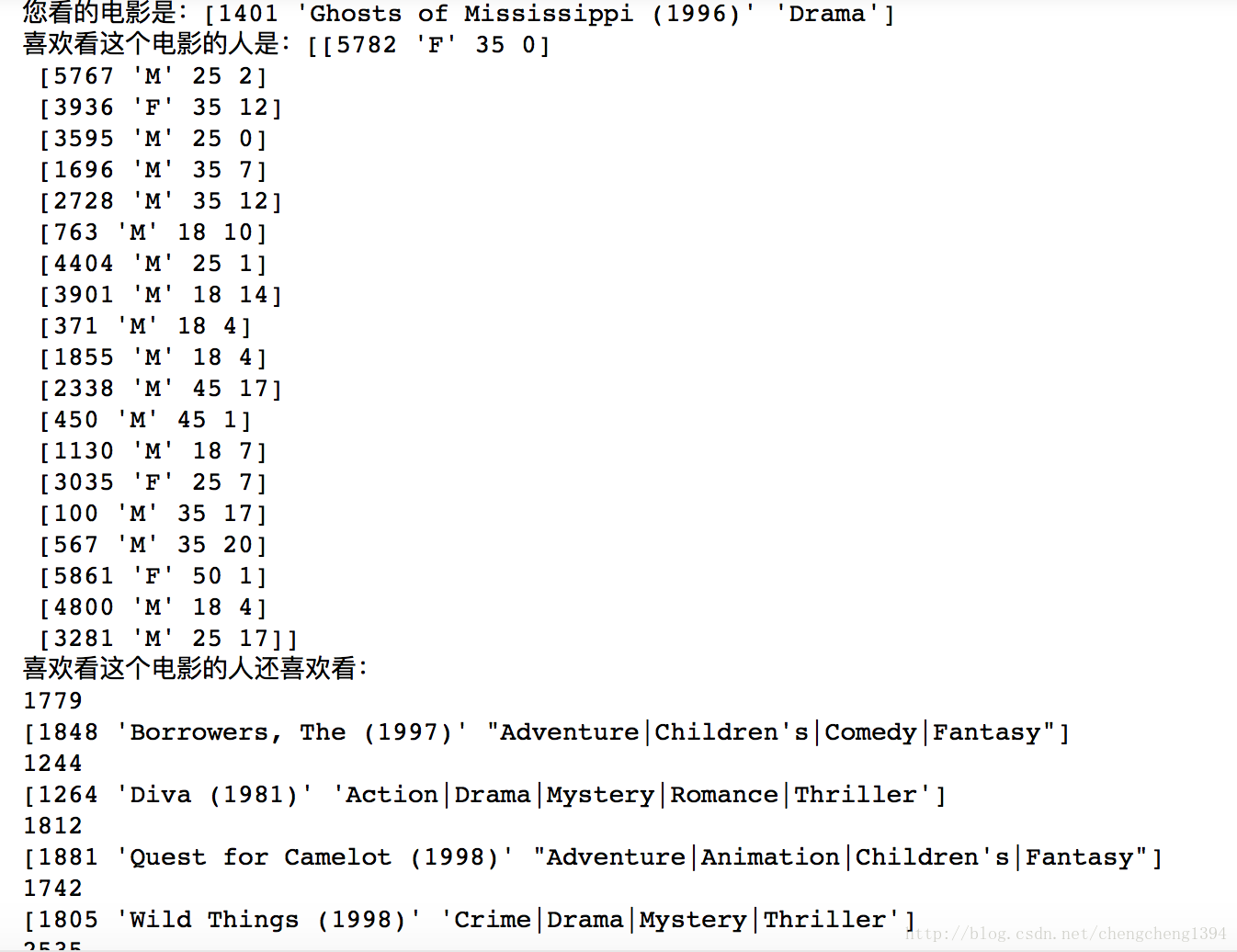
print("您看的電影是:{}".format(movies_orig[movieid2idx[movie_id_val]]))
print("喜歡看這個電影的人是:{}".format(users_orig[favorite_user_id-1]))
probs_users_embeddings = (users_matrics[favorite_user_id-1]).reshape([-1, 200])
probs_similarity = tf.matmul(probs_users_embeddings, tf.transpose(movie_matrics))
sim = (probs_similarity.eval())
# results = (-sim[0]).argsort()[0:top_k]
# print(results)
# print(sim.shape)
# print(np.argmax(sim, 1))
p = np.argmax(sim, 1)
print("喜歡看這個電影的人還喜歡看:")
results = set()
while len(results) != 5:
c = p[random.randrange(top_k)]
results.add(c)
for val in (results):
print(val)
print(movies_orig[val])
return results
結論
以上就是實現的常用的推薦功能,將網路模型作為迴歸問題進行訓練,得到訓練好的使用者特徵矩陣和電影特徵矩陣進行推薦。