
Shell-Sort 增量排序演算法 總結
阿新 • • 發佈:2019-01-02
1.Shell - Sort
希爾排序(Shell Sort)是插入排序的一種。是針對直接插入排序演算法的改進。該方法又稱縮小增量排序,因DL.Shell於1959年提出而得名。我們都知道直接插入排序演算法是相對來說比較低效的演算法,但是正是插入排序演算法的特性決定了我們在資料量小的時候,資料基本有序的時候的排序效果往往比一些高階排序演算法構架行之有效,更加快速 在我們開始瞭解Shell-Sort演算法之前,我們先來複習一下插入排序演算法 在這裡我們先給出插入排序的虛擬碼:
data - the array wait to sort n - the count of the elements of the array //本虛擬碼針對升序排列 for i=2 to (n-1) temp = data[i] j=i-1 while j>=0 and temp<data[j] //這裡不加等號保證排序的穩定性 data[j+1]=data[j] j-- data[j+1]=temp
從上面我們可以看出,直接插入排序演算法的在我們的陣列基本有序的時候複雜度非常的高效,但是一旦出現了雜糅的情況我們的耗時就非常的大,基本在O(n^2)的時間複雜度水平 我們注意到,我們的直接插入排序演算法的效率低下的原因在於我們每次找到我們的帶插入的位置後,我們都需要遍歷這個位置的路徑,大致我們的交換次數變得非常的冗長 所以,聰明的Shell就想到了一種非穩定的基於直接插入排序演算法的高效的排序演算法,也就是大名鼎鼎的 Shell - Sort
2.Shell - Sort 的原理
我們先引出我們的優化的機理,我們對於直接插入排序的優化基於一點就是 - 直接插入排序在基本有序的時候插入效率非常的高效,所以說我們的優化的核心就浮出水面了 我們不斷的令待排陣列的的有序度上升,讓陣列的有序性逐步增加,每一次我們優化之後,陣列都變得更加相對的有序,這時候下一次的插入排序的效率就會變得更加的高效 在這裡,機智的科學家發明了Shell -Sort,也就是增量排序的想法來處理這個問題 我們每次選擇一個增量,保證一個增量範圍內的陣列都是有序的,我們不斷縮小我們的增量直到1,這是後我們最後增量位1的過程就相當於是一個直接插入排序,但是之前的操作已經保證我們的陣列已經非常的有序,我們的最後的直接插入排序的過程的時間複雜度也變得非常的高效 每一個Shell - Sort需要幾趟,每一趟都相當於一次斷層的直接插入排序,如圖所示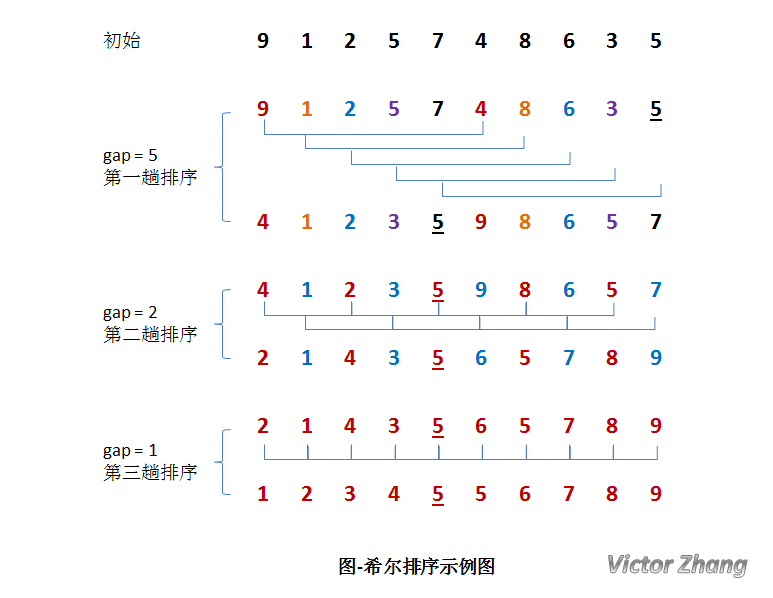
3.Shell - Path的選擇
現在的事實已經證明了,希爾排序的核心在於我們的增量的選取,我們的增量選取要求最後都是要歸終與一個為1的增量上 但是不同的選取導致我們的希爾排序的效率是不一樣的 實踐證明了有很多非常優秀的步長選擇方案是的我們的希爾排序在中小規模上的排序時間效率甚至超過了快速排序步長的選擇是希爾排序的重要部分。只要最終步長為1任何步長序列都可以工作。
演算法最開始以一定的步長進行排序。然後會繼續以一定步長進行排序,最終演算法以步長為1進行排序。當步長為1時,演算法變為插入排序,這就保證了資料一定會被排序。
Donald Shell 最初建議步長選擇為N/2並且對步長取半直到步長達到1。雖然這樣取可以比O(N2)類的演算法(插入排序)更好,但這樣仍然有減少平均時間和最差時間的餘地。可能希爾排序最重要的地方在於當用較小步長排序後,以前用的較大步長仍然是有序的。比如,如果一個數列以步長5進行了排序然後再以步長3進行排序,那麼該數列不僅是以步長3有序,而且是以步長5有序。如果不是這樣,那麼演算法在迭代過程中會打亂以前的順序,那就
不會以如此短的時間完成排序了。
|
步長序列 |
最壞情況下複雜度 |
|
|
|
|
|
|
|
(3**(t-k)-1)/2 |
待查 |
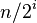


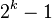
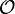

已知的最好步長序列是由Sedgewick提出的(1, 5, 19, 41, 109,...),該序列的項來自
9*4^i-9*2^i+1 或者是 4^i-3*2^i+1這兩個算式。
這項研究也表明“比較在希爾排序中是最主要的操作,而不是交換。”用這樣步長序列的希爾排序比插入排序和堆排序都要快,甚至在小陣列中比快速排序還快,但是在涉及大量資料時希爾排序還是比快速排序慢。
希爾排序的虛擬碼如下:
data - array wait to sort
n - the count of the array
dlta - the array save the dlta_path
for path=0 to length_dlta
for i=path to n //一趟分段直接插入排序
temp = data[i]
j=i-path
while j>=0 and temp<data[j]
data[j+path]=data[j]
j-=path
data[j+path]=temp3.Code of Python
from random import*
from time import*
from math import*
def shell_sort_0(data,n):
time=clock()
path=int(n/2);
while path:
i=path
while i<n:
temp=data[i]
j=i-path
while j>=0 and temp<data[j]:
data[j+path]=data[j]
j-=path
data[j+path]=temp
i+=1
path=int(path/2)
return clock()-time
def init_data(data,n):
for i in range(n):
data.append(randint(1,100000))
def make_dlta(dlta,n):
t=(int)(log(2*n+1,3))
for i in range(t):
dlta.append((int)(0.5*(3**(t-i)-1)))
def shell_sort_1(dlta,data,n):
time=clock()
for path in dlta:
i=path
while i<n:
temp=data[i]
j=i-path
while j>=0 and temp<data[j]:
data[j+path]=data[j]
j-=path
data[j+path]=temp
i+=1
return clock()-time
data=[]
n=eval(input("請輸入資料量:"))
init_data(data,n)
p=[]
dlta=[]
p=[i for i in data]
print("-----------")
print("time:%lf"%(shell_sort_0(p,n)))
p=[i for i in data]
make_dlta(dlta,n)
print("-----------")
print("time:%lf"%(shell_sort_1(dlta,p,n)))
time=clock()
p.sort()
print("time:%lf"%(clock()-time))