
nodejs Stream使用中的陷阱
阿新 • • 發佈:2019-01-02
文章轉自:http://my.oschina.net/sundq/blog/189505
最近公司有個專供下載檔案的http伺服器出現了記憶體洩露的問題,該伺服器是用node寫的,後來測試發現只有在下載很大檔案的時候才會出現記憶體洩露的情況。最後乾脆抓了一個profile看看,發現有很多等待發送的buff佔用著記憶體,我的profile如下(怎麼抓取profile,大家可以google一下):
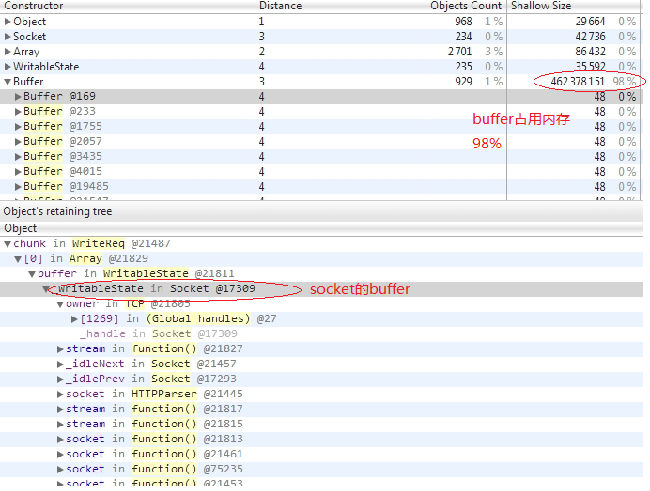
於是查看了一下發送資料的程式碼,如下:
| 1 2 3 4 5 6 7 |
var fReadStream = fs.createReadStream(filename);
fReadStream.on('data', function (chunk) {
res.write(chunk);
});
fReadStream.on('end', function () {
res.end();
});
|
開始覺得沒有什麼問題,於是在google上查了一下node http處理大檔案的方法,結果發現有人使用pipe方法,於是將程式碼修改如下:
| 1 2 |
var fReadStream = fs.createReadStream(filename);
fReadStream.pipe(res)
|
測試了一下,發現OK,但是還是不明白為什麼會這樣,於是研究一個一下pipe方法的程式碼,發現pipe有如下程式碼:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
function pipeOnDrain(src) {//可寫流可以執行寫操作
return function() {
var dest = this;
var state = src._readableState;
state.awaitDrain--;
if (state.awaitDrain === 0)flow(src);//寫資料
};
}
function flow(src) {//寫操作函式
var state = src._readableState;
var chunk;
state.awaitDrain = 0;
function write(dest, i, list) {
var written = dest.write(chunk);
if (false === written) {//判斷寫資料是否成功
state.awaitDrain++;//計數器
}
}
while (state.pipesCount && null !== (chunk = src.read())) {
if (state.pipesCount === 1)
write(state.pipes, 0, null);
else
state.pipes.forEach(write);
src.emit('data', chunk);
// if anyone needs a drain, then we have to wait for that.
if (state.awaitDrain > 0)
return;
}
// if every destination was unpiped, either before entering this
// function, or in the while loop, then stop flowing.
//
// NB: This is a pretty rare edge case.
if (state.pipesCount === 0) {
state.flowing = false;
// if there were data event listeners added, then switch to old mode.
if (EE.listenerCount(src, 'data') > 0)
emitDataEvents(src);
return;
}
// at this point, no one needed a drain, so we just ran out of data
// on the next readable event, start it over again.
state.ranOut = true;
}
|
原來pipe方法每次寫資料的時候,都會判斷是否寫成功,如果寫失敗,會等待可寫流觸發"drain"事件,表示可寫流可以繼續寫資料了,然後pipe才會繼續寫資料。
這下明白了,我們第一次使用的程式碼沒有判斷res.write(chunk)是否執行成功,就繼續寫,這樣如果檔案比較大,而可寫流的寫速度比較慢的話,會導致大量的buff快取在記憶體中,就會導致記憶體撐爆的情況。
總結:
在使用流的過程中,一定要注意可讀流和可寫流讀和寫之間的平衡,負責會導致記憶體洩露,而pipe就實現了這樣的功能。稍微研究了一下文件,發現stream類有pause()和resume()兩個方法,這樣的話我們也可以自己控制讀寫的平衡。程式碼如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
var http = require("http");
var fs = require("fs");
var filename = "file.iso";
var serv = http.createServer(function (req, res) {
var stat = fs.statSync(filename);
res.writeHeader(200, {"Content-Length": stat.size});
var fReadStream = fs.createReadStream(filename);
fReadStream.on('data', function (chunk) {
if(!res.write(chunk)){//判斷寫緩衝區是否寫滿(node的官方文件有對write方法返回值的說明)
fReadStream.pause();//如果寫緩衝區不可用,暫停讀取資料
}
});
fReadStream.on('end', function () {
res.end();
});
res.on("drain", function () {//寫緩衝區可用,會觸發"drain"事件
fReadStream.resume();//重新啟動讀取資料
});
});
serv.listen(8888);
|