
爬蟲通過URL請求403錯誤
阿新 • • 發佈:2019-01-02
之前獲取網站資料,本來是已經完成了,今天一試發現包403了。整理了一天
先說主要程式碼
import urllib.request
# Cookie = "rxVisitor=15186102248518I5BJAVPSPA24S0U5I8RB59VE82158HN; CmLocation=100|100; CmProvid=bj; WT_FPC=id=2a5a17bd31f889e7e761499577321364:lv=1528894831117:ss=1528894326945; saplb_*=(J2EE204290020)204290050"
url = "########"
headers = {
'User-agent' 問題1:
按照網上要求添加了headers,也傳了引數,執行是還是403。
最後發現需要對data經行轉碼,編譯
data = urllib.parse.urlencode(data) #首先對data進行轉碼,轉化成str型別
data = data.encode(‘utf-8’) #post請求只支援byte型別,所以要進行再次編碼
通過除錯可以看到,網路請求是POST
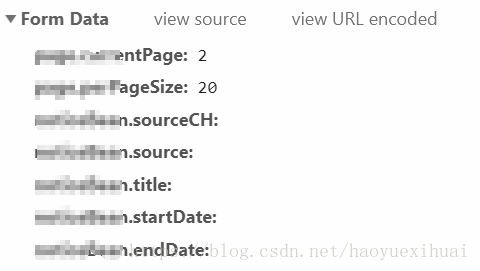
post引數
問題1,白天一直沒解決,於是想通過Selenium模擬瀏覽器方式解決,但是一直卡在翻頁上面,初步判斷是頁面內ajax分頁,需要重新載入頁面元素
有一個By Actions方式
WebElement element = driver.findElement(By("element_path"));
Actions actions = new Actions(driver);
actions.moveToElement(element).click().perform();問題2:
執行的時候結果報錯:UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x8b in position 1: invalid start byte
上網查詢,是因為表頭中有一條:
“’Accept-Encoding’: ‘gzip, deflate, br’”
意思就是gzip需要解壓,瀏覽器可以完成,本地解析就不可以,所以直接註釋掉。
(參考:https://blog.csdn.net/Hudeyu777/article/details/76023441)
問題3:
網站不需要登陸,於是直接把Cookie也註釋掉