
SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from
摘要
在本文中,我們從三維鐳射雷達點雲的角度對道路目標進行了語義分割。我們特別希望檢測和分類感興趣的例項,例如汽車、行人和騎自行車的人。我們制定這個問題作為一個逐點分類的問題,並提出一個端到端的管道稱為SqueezeSeg基於卷積神經網路(CNN):CNN需要改變鐳射雷達點雲直接輸出作為輸入,並逐點地標籤地圖,然後精製的條件隨機場(CRF)實現為複發性層。然後用傳統的聚類演算法得到例項級的標籤。我們的CNN模型是在來自KITTI1資料集的鐳射雷達點雲上訓練的,我們的逐點分割標籤來自於KITTI的3D邊框。為了獲得額外的訓練資料,我們在廣受歡迎的視訊遊戲《俠盜飛車V》(GTA-V)中構建了一個鐳射雷達模擬器,以合成大量真實的訓練資料。我們的實驗表明,SqueezeSeg以驚人的快速和穩定性,每幀(8.7±0.5)ms的高精度執行,高度可取的自主駕駛的應用程式。此外,對綜合資料的訓練可以提高對真實資料的驗證準確性。我們的原始碼和合成資料將是開源的。
1.介紹
自動駕駛系統依賴於對環境的準確、實時和魯棒的感知。自動駕駛汽車需要精確地分類和定位“道路物體”,我們將其定義為與駕駛有關的物體,如汽車、行人、自行車和其他障礙物。不同的自動駕駛解決方案可能有不同的感測器組合,但3D鐳射雷達掃描器是最普遍的元件之一。鐳射雷達掃描器直接產生環境的距離測量,然後由車輛控制器和計劃人員使用。此外,鐳射雷達掃描器在幾乎所有的光照條件下都是健壯的,無論是白天還是黑夜,有或沒有眩光和陰影。因此,基於鐳射雷達的感知任務引起了廣泛的研究關注。
在這項工作中,我們關注道路目標分割使用(Velodyne風格)三維鐳射雷達點雲。給定鐳射雷達掃描器的點雲輸出,任務的目標是隔離感興趣的物件並預測它們的類別,如圖1所示。

以前的方法包括或使用以下階段的部分:刪除地面,將剩餘的點聚到例項中,從每個叢集中提取(手工製作)特性,並根據其特性對每個叢集進行分類。這種模式,儘管它的受歡迎程度2,3,4,5,有幾個缺點:a)地面分割在上面的管道通常依賴於手工特性或決策規則,一些方法依賴於一個標量閾值6和其他需要更復雜的特性,比如表面法線7或不變的描述符4,所有這些可能無法概括,後者需要大量的預處理。b)多級管道存在複合誤差的聚合效應,上面管道中的分類或聚類演算法無法利用上下文,最重要的是物件的直接環境。c)很多去除地面的方法都依賴於迭代演算法,如RANSAC (random sample consensus) 5, GP-INSAC (Gaussian Process Incremental sample consensus)
{kind=link}
{kind=link}
本文提出了一種基於卷積神經網路(CNN)和條件隨機場(CRF)的端到端管道。CNNs和CRFs已成功應用於二維影象8、9、10、11的分割任務。為了將CNNs應用於三維鐳射雷達點雲,我們設計了一個CNN,它接受變換後的鐳射雷達點雲,並輸出標籤點地圖,通過CRF模型進一步細化。然後,通過對一個類別中的點應用傳統的聚類演算法(如DBSCAN)來獲得例項級標籤。為了將3D點雲提供給2D CNN,我們採用球面投影將稀疏的、不規則分佈的3D點雲轉換為密集的2D網格表示。所提出的CNN模型借鑑了squeeze zenet[12]的思想,經過精心設計,降低了引數大小和計算複雜度,目的是降低記憶體需求,實現目標嵌入式應用程式的實時推理速度。將CRF模型重構為一個迴圈神經網路(RNN)模組為11,可以與CNN模型進行端到端訓練。我們的模型是在基於KITTI資料集1的鐳射雷達點雲上訓練的,點分割標籤是從KITTI的3D邊框轉換而來的。為了獲得更多的訓練資料,我們利用Grand Theft Auto V (GTA-V)作為模擬器來檢索鐳射雷達點雲和點級標籤。
實驗表明,這種方法精度高、速度快、穩定性好,適用於自動駕駛。我們還發現,用人工的、噪聲注入的模擬資料替代我們的資料集進一步提高了對真實世界資料的驗證準確性。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2. 相關工作
A. 3維鐳射雷達點元的語義分割
以前的工作在鐳射雷達分割中看到了廣泛的粒度範圍,處理從特定元件到整個管道的任何事情。7提出了基於網格的地面和基於區域性表面凹凸性的目標分割。2總結了幾種基於迭代演算法的諸如RANSAC (random sample consensus)和GP-INSAC (gaussian process incremental sample consensus)的地面去除方法。最近的工作也集中在演算法效率上。5提出了有效的地面分割和聚類演算法,而[13]繞過地面分割直接提取前景物件。4將重點擴充套件到整個管道,包括分割、聚類和分類。提出了將點斑塊重新劃分為不同類別的背景和前景物件,然後使用EMST-RANSAC5進一步叢集例項。
B. 3D點雲CNN
CNN方法考慮的是二維或三維的鐳射雷達點雲。處理二維資料時考慮的是用鐳射雷達點雲投影自頂向下[14]或從許多其他檢視[15]投影的原始影象。其他工作考慮的是三維資料本身,將空間離散為體素和工程特徵,如視差、平均和飽和度[16]。無論資料準備如何,深度學習方法都考慮利用二維卷積[17]或三維卷積[18]神經網路的端對端模型。
C. 影象的語義分割
CNNs和CRFs都被用於影象的語義分割任務。8提議將經過分類訓練的CNN模型轉換為完全卷積網路來預測畫素級標籤。9提出了一種用於影象分割的CRF公式,並用均值-場迭代演算法近似求解。CNNs和CRFs合併在10中,CNN用於生成初始概率圖,CRF用於細化和恢復細節。在11中,平均場迭代被重新表述為一個遞迴神經網路(RNN)模組。
D. 模擬資料採集
獲取註釋,特別是點或畫素級的註釋對於計算機視覺任務來說通常是非常困難的。因此,合成數據集引起了越來越多的關注。在自動駕駛社群中,視訊遊戲《俠盜獵車手》被用來檢索資料,用於目標檢測和分割[19]、[20]。
3.方法描述
A. 點雲轉換
傳統CNN模型操作影象,可以由3-dimentional張量的大小 H × W × 3表示。前二維編碼空間位置,其中H和W分別為影象高度和寬度。最後一個維度編碼特性,最常見的是RGB值。然而,三維鐳射雷達點雲通常表示為一組笛卡爾座標(x, y, z),也可以包含額外的特徵,如強度或RGB值。與影象畫素的分佈不同,鐳射雷達點雲的分佈通常是稀疏而不規則的。因此,純粹地將3D空間離散為立體畫素會導致過多的空voxels。處理這樣的稀疏資料是低效的,浪費計算。
為了獲得更緊湊的表示,我們將鐳射雷達點雲投射到一個球體上,以實現密集的、基於網格的表示:
和 分別為方位角和頂角,如圖2中A所示。

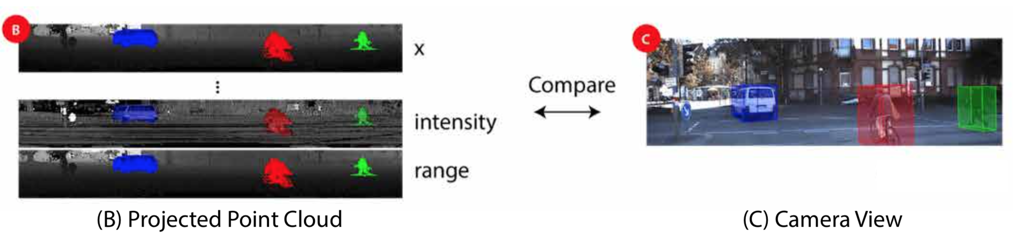
和 是離散化的解析度,( , )表示2D球面網格上的點的位置。將等式(1)應用於雲中的每個點,我們可以獲得大小為H × W × C的3D張量。在本文中,我們考慮從具有64個垂直通道的Velodyne HDL-64E LiDAR收集的資料,因此H = 64。受KITTI資料集的資料註釋的限制,我們只考慮90°的前檢視區域並將其劃分為512個網格所以W = 512。C是每個點的特徵數。在我們的實驗中,我們為每個點使用了5個特徵:3個笛卡爾座標(x,y,z),強度測量和範圍 。投影點雲的示例可以在圖2(B)中找到。可以看出,這種表示是密集且規則地分佈的,類似於普通影象(圖2(C))。
這種特徵使我們能夠避免手工製作的功能,從而提高我們的表現形式所概括的機率。
B. 網路結構
我們的卷積神經網路結構如圖3所示。

SqueezeSeg源自SqueezeNet[12],這是一種輕量級CNN,可以實現AlexNet[21]級精度,引數減少50倍。
SqueezeSeg的輸入是64 × 512 × 5張量,如上一節所述。我們從SqueezeNet移植層(conv1a到fire9)以進行特徵提取。SqueezeNet使用max-pooling來對寬度和高度尺寸的中間特徵圖進行下采樣,但由於我們的輸入張量高度遠小於寬度,我們只對寬度進行下采樣。fire9的輸出是一個下采樣的特徵對映,它對點雲的語義進行編碼。
為了獲得每個點的全解析度標籤預測,我們使用反捲積模組(更確切地說,“轉置卷積”)來對寬度維度中的特徵對映進行上取樣。 我們使用跳過連線將上取樣特徵對映新增到相同大小的低階特徵對映,如圖3所示。輸出概率圖由具有softmax啟用的卷積層(conv14)生成。概率圖由迴圈CRF層進一步細化,這將在下一節中討論。
為了減少模型引數和計算的數量,我們用fireModules [12]和fireDeconvs替換了卷積和反捲積層。兩個模組的體系結構如圖4所示。
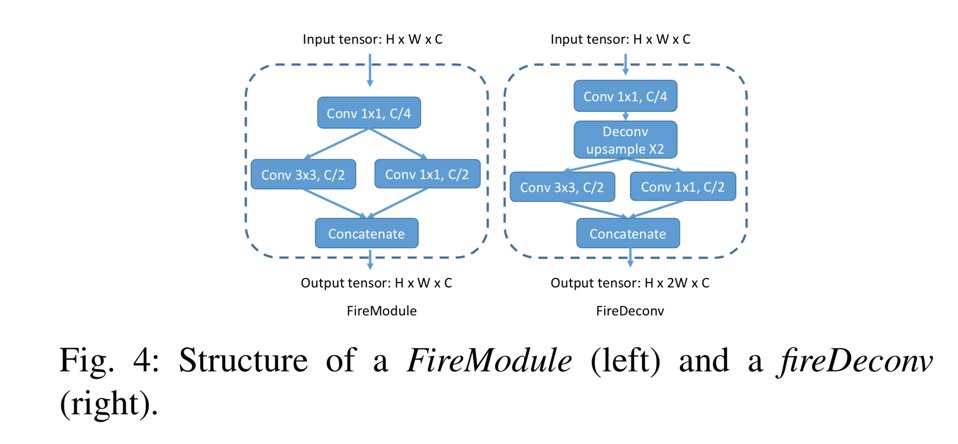
在fireModule中,大小為H×W×C的輸入張量首先被饋入1x1卷積,以將通道大小減小到C/4。接下來,使用3x3卷積來融合空間資訊。與並行1x1卷積一起,它們恢復C的通道大小。輸入1x1卷積稱為擠壓層,並行1x1和3x3卷積合稱為擴充套件層。給定匹配的輸入和輸出大小,3x3卷積層需要 引數以及 的運算量,而fireModule只需要 引數和 的計算。在fireDeconv模組中,用於對特徵貼圖進行上取樣的解卷積圖層位於擠壓和擴充套件圖層之間。要將寬度尺寸上取樣2,常規的1x4反捲積層必須包含 引數和 計算。然而,使用fireDeconv,我們只需要 引數和 計算。
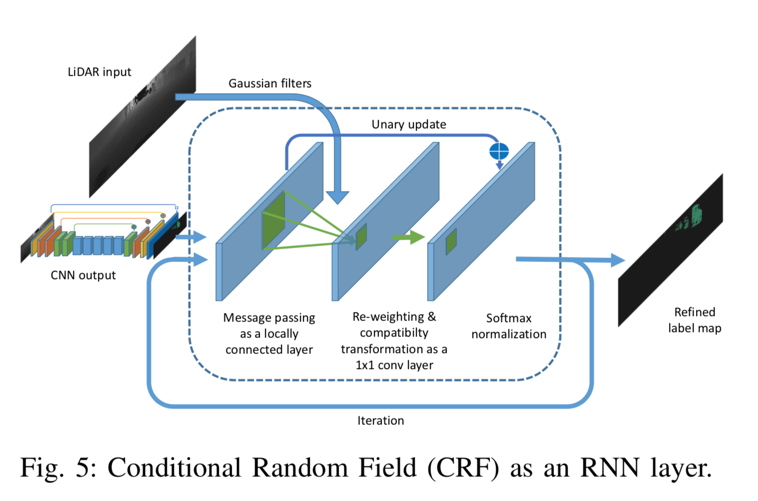
C. 條件隨機場
通過影象分割,CNN模型預測的標籤圖往往具有模糊的邊界。 這是由於在下采樣操作(例如最大池)中丟失了低階細節。 SqueezeSeg中也觀察到類似的現象。
準確的逐點標籤預測不僅需要了解物件和場景的高階語義,還需要了解低階細節。 後者對於標籤分配的一致性至關重要。 例如,如果雲中的兩個點彼此相鄰並且具有相似的強度測量值,則它們可能屬於同一物件並因此具有相同的標籤。 在10之後,我們使用條件隨機場(CRF)來細化由CNN生成的標籤圖。 對於給定的點雲和標籤預測c,其中表示第i個點的預測標籤,CRF模型使用能量函式: