
資料探勘中的模式發現(六)挖掘序列模式
序列模式挖掘
序列模式挖掘(sequence pattern mining)是資料探勘的內容之一,指挖掘相對時間或其他模式出現頻率高的模式,典型的應用還是限於離散型的序列。。
其涉及在資料示例之間找到統計上相關的模式,其中資料值以序列被遞送。通常假設這些值是離散的,因此與時間序列挖掘是密切相關的,但時間通常被認為是不同的活動。序列模式挖掘是結構化資料探勘的一種特殊情況。

基礎概念
為了幫助大家理解,我這裡講序列是如何產生的稍微描述一下。
例如,一個事務資料庫,一個事務代表一筆交易,一個單項代表交易的商品,單項屬性中的數字記錄的是商品ID
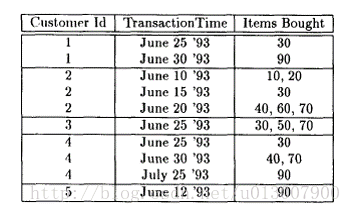
一般為了方便處理,需要把資料庫轉化為序列資料庫。方法是把使用者ID相同的記錄合併,有時每個事務的發生時間可以忽略,僅保持事務間的偏序關係。

序列(Sequence)
通常以SID表示,一個序列即是一個完整的資訊流。每個序列由不同的元素按順序有序排列,每個元素由不同專案(或者也可以稱之為事件)組成,
讓我們將其符號化
例:一條序列<(10,20)30(40,60,70)>有3個元素,分別是(10,20),30,(40,60,70);
3個事務的發生時間是由前到後。其中專案10和專案20是同時發生的,所以處在同一個元素中。這條序列是一個6-序列。
子序列(Subsequence)
設序列
支援度
序列
給定最小支援度閾值
長度為l的序列模式記為l-模式。
序列模式挖掘:找出所有的頻繁子序列,即該子序列在序列集中的出現頻率不低於最小支援度閾值。
例子:設序列資料庫如下圖所示,並設使用者指定的最小支援度min-support = 2。

序列
序列