
關於PCM音訊資料的相關轉換演算法
Introduction
Audio can be stored in many different file and compression formats, and converting between them can be a real pain. It is especially difficult in a .NET application, since the framework class library provides almost no support for the various Windows APIs
for audio compression and decompression. In this article I will explain what different types of audio file formats are available, and what steps you will need to go through to convert between formats. Then I'll explain the main audio codec related APIs that
Windows offers. I'll finish up by showing some working examples of converting files between various formats in .NET, making use of my open source
Understanding Audio Formats
Before you get started trying to convert audio between formats, you need to understand some of the basics of how audio is stored. By all means skip this section if you already know this, but it is important to have a basic grasp of some key concepts if you are to avoid the frustration of finding that the conversions you are trying to accomplish are not allowed. The first thing to understand is the difference between compressed and uncompressed audio formats. All audio formats fall into one of these two broad categories.
Uncompressed Audio (PCM)
Uncompressed audio, or linear PCM, is the format your soundcard wants to work with. It consists of a series of "samples". Each sample is a number representing how loud the audio is at a single point in time. One of the most common sampling rates is 44.1kHz, which means that we record the level of the signal 44100 times a second. This is often stored in a 16 bit integer, so you'd be storing 88200 bytes per second. If your signal is stereo, then you store a left sample followed by a right sample, so now you'd need 176400 bytes per second. This is the format that audio CDs use.
There are three main variations of PCM audio. First, there are multiple different sample rates. 44.1kHz is used on audio CDs, while DVDs typically use 48kHz. Lower sample rates are sometimes used for voice communications (e.g. telephony and radio) such as 16kHz or even 8kHz. The quality is degraded, but it is usually good enough for voice (music would not sound so good). Sometimes in professional recording studios, higher sample rates are used, such as 96kHz, although it is debatable what benefits this gives, since 44.1kHz is more than enough to record the highest frequency sound that a human ear can hear. It is worth noting that you can't just choose any sample rate you like. Most soundcards will support only a limited subset of sample rates. The most commonly suported values are 8kHz, 16kHz, 22.05kHz, 16kHz, 32kHz, 44.1kHz, and 48kHz.
Second, PCM can be recorded at different bit depths. 16 bit is by far the most common, and the one you should use by default. It is stored as a signed value (-32768 to +32767), and a silent file would contain all 0s. I strongly recommend against using 8 bit PCM. It sounds horrible. Unless you are wanting to create a special old-skool sound-effect, you should not use it. If you want to save space there are much better ways of reducing the size of your audio files. 24 bit is commonly used in recording studios, as it gives plenty of resolution even at lower recording levels, which is desirable to reduce the chance of "clipping". 24 bit can be a pain to work with as you need to find out whether samples are stored back to back, or whether they have an extra byte inserted to bring them to four byte alignment.
The final bit depth you need to know about is 32 bit IEEE floating point (in the .NET world this is a "float" or "Single"). Although 32 bits of resolution is overkill for a single audio file, it is extremely useful when you are mixing files together. If you were mixing two 16 bit files, you could easily get overflow, so typically you convert to 32 bit floating point (with -1 and 1 representing the min and max values of the 16 bit file), and then mix them together. Now the range could be between -2 and +2, so you might need reduce the overall volume of the mixed file to avoid clipping converting back down to 16 bit. Although 32 bit floating point audio is a type of PCM, it is not usually referred to as PCM, so as not to cause confusion with PCM represented as 32 bit integers (which is rare but does exist). It is quite often simply called "floating point" audio.
Note: there are other bit depths - some systems use 20 bit, or 32 bit integer. Some mixing programs use 64 bit double precision floating point numbers rather than 32 bit ones, although it would be very unusual to write audio files to disk at such a high bit depth. Another complication is that you sometimes need to know whether the samples are stored in "big endian" or "little endian" format. But the most common two bit depths you should expect to encounter are 16 bit PCM and 32 bit floating point.
The third main variation on PCM is the number of channels. This is usually either 1 (mono) or 2 (stereo), but you can of course have more (such as 5.1 which is common for movie sound-tracks). The samples for each channel are stored interleaved one after the other, and a pair or group of samples is sometimes referred to as a "frame".
Uncompressed Audio Containers
You can't just write PCM samples directly to disk and expect a media player to know how to play it. It would have no way of knowing what sample rate, bit depth and channel count you are using. So PCM samples are put inside a container. In Windows, the universal container format for PCM files is the WAV file.
A WAV file consists of a number of "chunks". The most important two are the format chunk and the data chunk. The format chunk contains a WAVEFORMAT structure (possibly with some extra bytes as well), which indicates the format of the audio in the data chunk. This includes whether it is PCM or IEEE floating point, and indicates what the sample rate, bit depth and channel count is. For convenience, it also contains other useful information, such as what the average number of bytes per second is (although for PCM you can easily calculate that for yourself).
WAV is not the only container format that PCM is stored in. If you are dealing with files from coming from Mac OS, they may be in an AIFF file. One big difference to watch out for is that AIFF files normally use big-endian byte ordering for their samples, whilst WAV files use little-endian.
Compressed Audio Formats
There are numerous audio compression formats (also called "codecs"). Their common goal is to reduce the amount of storage space required for audio, since PCM takes up a lot of disk space. To achieve this various compromises are often made to the sound quality, although there are some "lossless" audio formats such as "FLAC" or Apple Lossless (ALAC), which conceptually are similar to zipping a WAV file. They decompress to the exact same PCM that you compressed.
Compressed audio formats fall into two broad categories. One is aimed at simply reducing the file-size whilst retaining as much audio fidelity as possible. This includes formats like MP3, WMA, Vorbis and AAC. They are most often used for music and can often achieve around 10 times size reduction without a particularly noticable degradation in sound quality. In addition there are formats like Dolby Digital which take into account the need for surround sound in movies.
The other category is codecs designed specifically for voice communications. These are often much more drastic, as they may need to be transmitted in real-time. The quality is greatly reduced, but it allows for very fast transmission. Another consideration that some voice codecs take into account is the processor work required to encode and decode. Mobile processors are powerful enough these days that this is no longer a major consideration, but it explains why some telephony codecs are so rudimentary. One example of this is G.711, or mu and a-law, which simply converts each 16 bit sample to an 8 bit sample, so in one sense it is still a form of PCM (although not linear). Other commonly encountered telephony or radio codecs include ADPCM, GSM 610,G.722, G.723.1, G.729a, IMBE/AMBE, ACELP. There are also a number targetted more for internet teleophony scenarios such as Speex, Windows Media Voice, and Skype's codec SILK.
As you can see, there is an overwhelming variety of audio codecs available, and more are being created all the time (opus is a particuarly interesting new one). You are not going to be able to write a program that supports them all, but it is possible to cover a good proportion of them.
Compressed Audio Containers
Containers for compressed audio is where things start to get very tricky. The WAV file format can actually contain most of the codecs I have already mentioned. The format chunk of the WAV file is flexible enough (especially with the introduction of WAVEFORMATEXTENSIBLE)
to define pretty much anything. But the WAV file format has limitations of its own (e.g. needing to report the file length in the header, doesn't support very large files, doesn't have good support for adding metadata such as album art). So many compressed
audio types come with their own container format. For example MP3 files consist simply of a series of compressed chunks of MP3 data with optional metadata sections added to the beginning or end. WMA files use the Microsoft ASF format.
AAC files can use the MP4 container format. This means that, like with WAV, audio files typically
contain more than just encoded audio data. Either you or the decoder you use will need to understand how to get the compressed audio out of the container it is stored in.
Bitrates and Block Alignment
Most codecs offer a variety of bitrates. The bitrate is the average number of bits required to store a second's worth of audio. You select your desired bitrate when you initialise the encoder. Codecs can be either constant bitrate (CBR) or variable bitrate (VBR). In a constant bitrate codec, the same number of input bytes always turns into the same number of output bytes. It makes it easy to navigate through the encoded file as every compressed block is the same number of bytes. The size of this block is sometimes called the "block align" value. If you are decoding a CBR file, you should try to only give the decoder exact multiples of "block align" to decode each time. With a VBR file, the encoder can change the bit rate as it sees fit, which allows it to achieve a greater compression rate. The downside is that it is harder to reposition within the file, as half-way through the file may not mean half-way through the audio. Also, the decoder will probably need to be able to cope with being given incomplete blocks to decode.
A Conversion Pipeline
Now we've covered the basics of compressed and uncompressed audio formats, we need to think about what conversion we are trying to do. You are usually doing one of three things. First is decoding, where you take a compressed audio type and convert it to PCM. The second is encoding where you take PCM and convert it to a compressed format. You can't go directly from one compressed format to another though. That is calledtranscoding, and involves first decoding to PCM, and then encoding to another format. There may even be an additional step in the middle, as you sometimes need to transcode from one PCM format to another.
Decoding
Every decoder has a single preferred PCM output format for a given input type. For example, your MP3 file may natively decode to 44.1kHz stereo 16 bit, and a G.711 file will decode to 8kHz mono 16 bit. If you want floating point output, or 32kHz your decoder might be willing to oblige, but often you have to do that as a separate stage yourself.
Encoding
Likewise, your encoder is not likely to accept any type of PCM as its input. It will have specific constraints. Usually both mono and stereo are supported, and most codecs are flexible about sample rate. But bit depth will almost always need to be 16 bit. You should also never attempt to change the input format to an encoder midway through encoding a file. Whilst some file formats (e.g. MP3) technically allow sample-rate and channel count to change in the middle of a file, this makes life very difficult for anyone who is trying to play that file.
Transcoding PCM
You should realise by now that some conversions cannot be done in one step. Having gone from compressed to PCM, you may need to change to a different variant of PCM. Or maybe you already have PCM but it is not in the right format for your encoder. There are three ways in which PCM can be changed, and these are often done as three separate stages, although you could make a transcoder that combined them. These are changing the sample rate (known as resampling), changing the bit depth, and changing the channel count.
Changing PCM Channel Count
Probably the easiest change to PCM is modifying the number of channels. To go from mono to stero, you just need to repeat every sample. So for example, if we have a byte array called input,
containing 16 bit mono samples, and we want to convert it to stereo, all we need to do is:
private byte[] MonoToStereo(byte[] input)
{
byte[] output = new byte[input.Length * 2];
int outputIndex = 0;
for (int n = 0; n < input.Length; n+=2)
{
// copy in the first 16 bit sample
output[outputIndex++] = input[n];
output[outputIndex++] = input[n+1];
// now copy it in again
output[outputIndex++] = input[n];
output[outputIndex++] = input[n+1];
}
return output;
}
How about stereo to mono? Here we have a choice. The easiest is just to throw one channel away. In this example we keep the left channel and throw away the right:
Hide Copy Codeprivate byte[] StereoToMono(byte[] input)
{
byte[] output = new byte[input.Length / 2];
int outputIndex = 0;
for (int n = 0; n < input.Length; n+=4)
{
// copy in the first 16 bit sample
output[outputIndex++] = input[n];
output[outputIndex++] = input[n+1];
}
return output;
}
Alternatively we might want to mix left and right channels together. This means we actually need to access the sample values. If it is 16 bit, that means every two bytes must be turned into an Int16.
You can use bit manipulation for that, but here I'll show the use of the BitConverter helper class. I mix the samples
by adding them together and dividing by two. Notice that I've used 32 bit integers to do this, to prevent overflow problems. But when I'm ready to write out my sample, I convert back down to a 16 bit number and use BitConverter to
turn this into bytes.
private byte[] MixStereoToMono(byte[] input)
{
byte[] output = new byte[input.Length / 2];
int outputIndex = 0;
for (int n = 0; n < input.Length; n+=4)
{
int leftChannel = BitConverter.ToInt16(input,n);
int rightChannel = BitConverter.ToInt16(input,n+2);
int mixed = (leftChannel + rightChannel) / 2;
byte[] outSample = BitConverter.GetBytes((short)mixed);
// copy in the first 16 bit sample
output[outputIndex++] = outSample[0];
output[outputIndex++] = outSample[1];
}
return output;
}
There are of course other strategies you could use for changing channel count, but those are the most common.
Changing PCM Bit Depth
Changing PCM bit depth is also relatively straightforward, although working with 24 bit can be tricky. Let's start with a more common transition, going from 16 bit to 32 bit floating point. I'll imagine we've got our 16 bit PCM in a byte array again, but
this time we'll return it as a float array, making it easier to do analysis or DSP. Obviously you could use BitConverter to
put the bits back into a byte array again if you want.
public float[] Convert16BitToFloat(byte[] input)
{
int inputSamples = input.Length / 2; // 16 bit input, so 2 bytes per sample
float[] output = new float[inputSamples];
int outputIndex = 0;
for(int n = 0; n < inputSamples; n++)
{
short sample = BitConverter.ToInt16(input,n*2);
output[outputIndex++] = sample / 32768f;
}
return output;
}
Why did I divide by 32768 when Int16.MaxValue is 32767? The answer is that Int16.MinValue is -32768, so I know that my audio is entirely in the range ±1.0. If it goes outside ±1.0, some audio programs will interpret that as clipping, which might seem strange if you knew you hadn't amplified the audio in any way. It doesn't really matter to be honest, so long as that you are careful not to clip when you go back to 16 bit, which we'll come back to shortly.
What about 24 bit audio? It depends on how the audio is laid out. In this example, we'll assume it is packed right up together. To benefit from BitConverter we'll
copy every 3 bytes into a temporary buffer of 4 bytes and then convert into an int. Then we'll divide by the maximum 24 bit value to get into the ±1.0 range again. Please note that using BitConverter is
not the fastest way to do this. I usually make an implementation withBitConverter as a reference and then check my
bit manipulation code against it.
public float[] Convert24BitToFloat(byte[] input)
{
int inputSamples = input.Length / 3; // 24 bit input
float[] output = new float[inputSamples];
int outputIndex = 0;
var temp = new byte[4];
for(int n = 0; n < inputSamples; n++)
{
// copy 3 bytes in
Array.Copy(input,n*3,temp,0,3);
int sample = BitConverter.ToInt32(temp,0);
output[outputIndex++] = sample / 16777216f;
}
return output;
}
How about going the other way, say from floating point back down to 16 bit? This is fairly easy, but at this stage we need to decide what to do with samples that "clip". You could simply throw an exception, but more often you will simply use "hard limiting",
where any samples out of range will just be set to their maximum value. Here's a code sample showing us reading some floating point samples, adjusting their volume, and then clipping before writing 16 bit samples into an array of Int16.
for (int sample = 0; sample < sourceSamples; sample++)
{
// adjust volume
float sample32 = sourceBuffer[sample] * volume;
// clip
if (sample32 > 1.0f)
sample32 = 1.0f;
if (sample32 < -1.0f)
sample32 = -1.0f;
destBuffer[destOffset++] = (short)(sample32 * 32767);
}
Resampling
Resampling is the hardest transformation to perform on PCM correctly. The first issue is that the number of output samples for a given number of input samples is not necessarily a whole number. The second issue is that resampling can introduce unwanted artefacts such as "aliasing". This means that ideally you want to use an algorithm that has been written by someone who knows what they are doing.
You might be tempted to think that for some sample rate conversions this is an easy task. For example if you have 16kHz audio and want 8kHz audio, you could throw away every other sample. And to go from 8kHz to 16kHz you could add in an extra sample between each original one. But what value should that extra sample have? Should it be 0? Or should we just repeat each sample? Or maybe we could calculate an in-between value - the average of the previous and next samples. This is called "linear interpolation", and if you are interested in finding out more about interpolation strategies you could start by looking here.
One way to deal with the problem of aliasing is to put your audio through a low pass filter (LPF). If an audio file is sampled at 48kHz, the highest frequency it can contain is half that value (read up on the Nyquist Theorem if you want to understand why). So if you resampled to 16kHz, any frequencies above 8kHz in the original file could appear "aliased" as lower frequency noises in the resampled file. So it would be best to filter out any sounds above 8kHz before downsampling. If you are going the other way, say resampling a 16kHz file to 44.1kHz, then you would hope that the resulting file would not contain any information above 8kHz, since the original did not. But you could run a low pass filter after conversion, just to remove any artefacts from the resampling.
We'll talk later about how to use someone else's resampling algorithm, but let's say for the moment that we throw caution (and common sense) to the wind and want to implement our own "naive" resampling algorithm. We could do it something like this:
Hide Copy Code// Just about worst resampling algorithm possible: private float[] ResampleNaive(float[] inBuffer, int inputSampleRate, int outputSampleRate) { var outBuffer = new List<float>(); double ratio = (double) inputSampleRate / outputSampleRate; int outSample = 0; while (true) { int inBufferIndex = (int)(outSample++ * ratio); if (inBufferIndex < read) writer.WriteSample(inBuffer[inBufferIndex]); else break; } return outBuffer.ToArray(); }
Testing your Resampler
Now if you try this algorithm out on say a spoken word recording, then you be pleasantly surprised to find that it sounds reasonably good. Maybe resampling isn't so complicated after all. And with speech it might just about be possible to get away with such a naive approach. After all, the most important test for audio is the "use your ears" test, and if you like what you hear, who cares if your algorithm is sub-optimal?
However, the limitations of this approach to resampling are made very obvious when we give it a different sort of input. One of the best test signals you can use to check the quality of your resampler is a sine wave sweep. This is a sine wave signal that starts off at a low frequency and gradually increases in frequency over time. The open source Audacity audio editor can generate these (select "Generate | Chirp ..."). You should start at a low frequency (e.g. 20Hz, about as low as the human ear can hear), and go up to half the sample rate of your input file. One word of caution - be very careful about playing one of these files, especially with ear-buds in. You could find it a very unpleasant and painful experience. Turn the volume right down first.
We can get a visual representation of this file, by using any audio program that plots a spectrogram. My favourite is a VST plugin by Schwa called Spectro, but there are plenty of programs that can draw these graphs from a WAV file. Basically, the X axis represents time, and the Y axis represents frequency, so our sweep will look something like this:
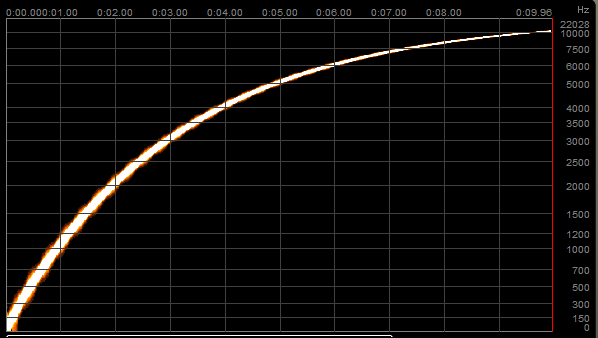
If we downsample this file to 16kHz, the resulting file will not be able to contain any frequencies above 8kHz, but we should expect the first part of the graph to remain unscathed. Let's have a look at how well the Media Foundation Resampler does at its maximum quality setting.
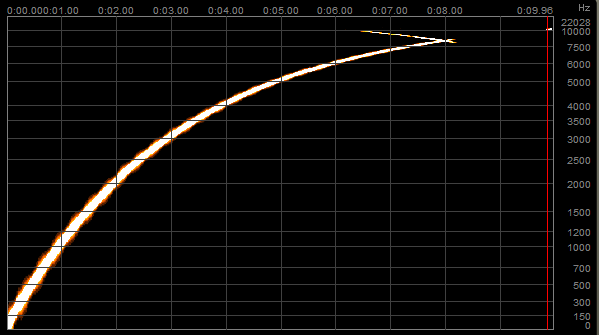
Not bad. You can see that there is a very small amount of aliasing just before the cut-off frequency. This is because Media Foundation uses a low pass filter to try to cut out all frequencies above 8kHz, but real-world filters are not perfect, and so a small compromise has to be made.
Now lets see how our naive algorithm got on. Remember that we didn't bother to do any filtering at all.

Wow! As you can see, all kinds of additional noise has made it into our file. If you listen to it, you'll still hear the main sweep as the dominant sound originally, but it carries on past the point at which it was supposed to cut off and we end up with something that sounds like some weird psychadelic sci-fi soundtrack. The takeaway is that if you need to resample, you should probably not try to write your own algorithm.
What Codecs Can I Use?
For .NET developers, when thinking about what audio codecs you want to use, you have two options. The first is to make use of the various Windows APIs that let you access encoders and decoders already installed on your PC. The second is to either write your own codec, or more likely, write a P/Invoke wrapper for a third party DLL. We'll focus mainly on the first approach, with a few brief examples later of how the second can be done.
There are three main API's for encoding and decoding audio in Windows. These are ACM, DMO and MFT.
Audio Compression Manager (ACM)
The Audio Compression Manager is the longest serving and most universally supported Windows API for audio codecs. ACM codecs are DLLs with a .acm extension and are installed as "drivers" on your system. Windows XP and above come with a small selection of these, covering a few telephony codecs like G.711, GSM, ADPCM, and also has an MP3 decoder. Strangely enough Microsoft did not choose to include a Windows Media Format decoder as an ACM. One thing to note with ACM is that most of them are 32 bit. So if you are running in a 64 bit process, you will typically only be able to access the ones that come with Windows as they are x64 capable.
Enumerating ACM Codecs
To find out what ACM codecs are installed on your system, you need to call the acmDriverEnum function, and pass in a callback function. Then, each time the callback is called, you use the driver handle you are passed to callacmDriverDetails, which fills in an instance of the ACMDRIVERDETAILS structure. On its own, this doesn't give you too much useful information other than the codec name, but you can then ask the driver for a list of the "format tags" it supports. You do this by calling acmFormatTagEnum, which takes a callback which will return a filled inACMFORMATTAGDETAILS structure for each format tag.
There are typically two format tags for each ACM codec. One is the format it decodes or encodes to, and the other is PCM. However, this is just a high-level description of the format. To get the actual details of possible input and output formats, there
is another enumeration we must do, which is to call acmFormatEnum,
passing in the format tag. Once again, this requires the use of a callback
function which will be called with each of the valid formats that can be used as inputs or outputs to this codec. Each callback provides an instance of ACMFORMATDETAILS which
contains details of the format. Most importantly, it contains a pointer to aWAVEFORMATEX structure.
This is very important, as it is typically the WAVEFORMATEX structure that is used to get hold of the right codec
and to tell it what you want to convert from and to.
Unfortunately, WAVEFORMATEX is quite tricky to marshal in a .NET environment, as it is a variable length structure
with an arbitrary number of "extra bytes" at the end. My approach is to have a special version of the structure for marshaling which has enough spare bytes at the end. I also use a Custom
Marshaler to to enable me to deal more easily with known Wave formats.
When you are dealing with third party ACM codecs, you often need to examine these WAVEFORMATEX structures in a hex
editor, in order to make sure that you can pass in one that is exactly right. You'll also need this if you want to make a WAV file that Windows Media Player can play as it will use this WAVEFORMATEX structure
to search for an ACM decoder.
If all this sounds like a ridiculous amount of work just to find out what codecs you can use, the good news is that I have already written the interop for all this. Here's some code to enumerate the ACM codecs and print out details about all the format tags and formats it supports:
Hide Shrinkforeach (var driver in AcmDriver.EnumerateAcmDrivers())
{
StringBuilder builder = new StringBuilder();
builder.AppendFormat("Long Name: {0}\r\n", driver.LongName);
builder.AppendFormat("Short Name: {0}\r\n", driver.ShortName);
builder.AppendFormat("Driver ID: {0}\r\n", driver.DriverId);
driver.Open();
builder.AppendFormat("FormatTags:\r\n");
foreach (AcmFormatTag formatTag in driver.FormatTags)
{
builder.AppendFormat("===========================================\r\n");
builder.AppendFormat("Format Tag {0}: {1}\r\n", formatTag.FormatTagIndex, formatTag.FormatDescription);
builder.AppendFormat(" Standard Format Count: {0}\r\n", formatTag.StandardFormatsCount);
builder.AppendFormat(" Support Flags: {0}\r\n", formatTag.SupportFlags);
builder.AppendFormat(" Format Tag: {0}, Format Size: {1}\r\n", formatTag.FormatTag, formatTag.FormatSize);
builder.AppendFormat(" Formats:\r\n");
foreach (AcmFormat format in driver.GetFormats(formatTag))
{
builder.AppendFormat(" ===========================================\r\n");
builder.AppendFormat(" Format {0}: {1}\r\n", format.FormatIndex, format.FormatDescription);
builder.AppendFormat(" FormatTag: {0}, Support Flags: {1}\r\n", format.FormatTag, format.SupportFlags);
builder.AppendFormat(" WaveFormat: {0} {1}Hz Channels: {2} Bits: {3} Block Align: {4},
AverageBytesPerSecond: {5} ({6:0.0} kbps), Extra Size: {7}\r\n",
format.WaveFormat.Encoding, format.WaveFormat.SampleRate, format.WaveFormat.Chan