
Redis的典型應用場景
介紹
redis是鍵值對的資料庫,常用的五種資料型別為
字串型別(string),雜湊型別(hash),列表型別(list),集合型別(set),有序集合型別(zset)
Redis用作快取,主要兩個用途:高效能,高併發,因為記憶體天然支援高併發
redis應用場景
分散式鎖(string)
setnx key value,當key不存在時,將 key 的值設為 value ,返回1
若給定的 key 已經存在,則setnx不做任何動作,返回0。
當setnx返回1時,表示獲取鎖,做完操作以後del key,表示釋放鎖,如果setnx返回0表示獲取鎖失敗,整體思路大概就是這樣,細節還是比較多的,有時間單開一篇來講解
計數器(string)
如知乎每個問題的被瀏覽器次數

set key 0
incr key // incr readcount::{帖子id} 每閱讀一次
get key // get readcount::{帖子id} 獲取閱讀量
分散式全域性唯一id(string)
分散式全域性唯一id的實現方式有很多,這裡只介紹用redis實現
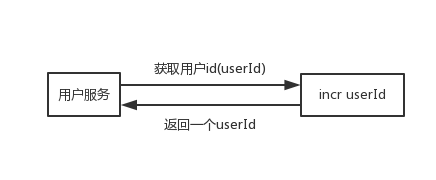
每次獲取userId的時候,對userId加1再獲取,可以改進為如下形式
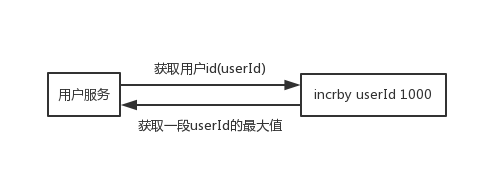
直接獲取一段userId的最大值,快取到本地慢慢累加,快到了userId的最大值時,再去獲取一段,一個使用者服務宕機了,也頂多一小段userId沒有用到
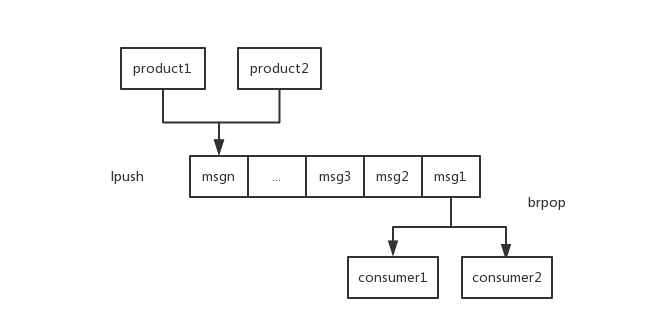
set 訊息佇列(list)
在list裡面一邊進,一邊出即可
## 實現方式一
lpush key value //一直往list左邊放
brpop key value 10
//key這個list有元素時,直接彈出,沒有元素被阻塞,直到等待超時或發現可彈出元素為止,上面例子超時時間為10s
## 實現方式二
rpush key value
blpop key value 10
新浪/Twitter使用者訊息列表(list)
加入說小編li關注了2個微博a和b,a發了一條微博(編號為100)就執行如下命令
lpush msg::li 100
b發了一條微博(編號為200)就執行如下命令:
lpush msg::li 200
假如想拿最近的10條訊息就可以執行如下命令(最新的訊息一定在list的最左邊):
lrange msg::li 0 9 //下標從0開始,[start,stop]是閉區間,都包含
抽獎活動(set)
sadd key {userId} // 參加抽獎活動
smembers key //獲取所有抽獎使用者,大輪盤轉起來
spop key count //抽取count名中獎者,並從抽獎活動中移除
srandmember key count //抽取count名中獎者,不從抽獎活動中移除
實現點贊,簽到,like等功能
// 1001使用者給8001帖子點贊
sadd like::8001 1001
srem like::8001 1001 //取消點贊
sismember like::8001 1001 //檢查使用者是否點過贊
smembers like::8001 //獲取點讚的使用者列表
scard like::8001 //獲取點贊使用者數
實現關注模型,可能認識的人(set)
seven關注的人
sevenSub -> {qing, mic, james}
青山關注的人
qingSub->{seven,jack,mic,james}
Mic關注的人
MicSub->{seven,james,qing,jack,tom}
//返回sevenSub和qingSub的交集,即seven和青山的共同關注
sinter sevenSub qingSub -> {mic,james}
// 我關注的人也關注他,下面例子中我是seven
// qing在micSub中返回1,否則返回0
sismember micSub qing
sismember jamesSub qing
// 我可能認識的人,下面例子中我是seven
// 求qingSub和sevenSub的差集,並存在sevenMayKnow集合中
sdiffstore sevenMayKnow qingSub sevenSub -> {seven,jack}
電商商品篩選(set)

每個商品入庫的時候即會建立他的靜態標籤列表如,品牌,尺寸,處理器,記憶體
// 將拯救者y700P-001和ThinkPad-T480這兩個元素放到集合brand::lenovo
sadd brand::lenovo 拯救者y700P-001 ThinkPad-T480
sadd screenSize::15.6 拯救者y700P-001 機械革命Z2AIR
sadd processor::i7 拯救者y700P-001 機械革命X8TIPlus
// 獲取品牌為聯想,螢幕尺寸為15.6,並且處理器為i7的電腦品牌(sinter為獲取集合的交集)
sinter brand::lenovo screenSize::15.6 processor::i7 -> 拯救者y700P-001
排行版(zset)
redis的zset天生是用來做排行榜的、好友列表, 去重, 歷史記錄等業務需求
// user1的使用者分數為 10
zadd ranking 10 user1
zadd ranking 20 user2
// 取分數最高的3個使用者
zrevrange ranking 0 2 withscores
redis的過期策略
定期刪除
redis 會將每個設定了過期時間的 key 放入到一個獨立的字典中,以後會定期遍歷這個字典來刪除到期的 key。
定期刪除策略
Redis 預設會每秒進行十次過期掃描(100ms一次),過期掃描不會遍歷過期字典中所有的 key,而是採用了一種簡單的貪心策略。
- 從過期字典中隨機 20 個 key;
- 刪除這 20 個 key 中已經過期的 key;
- 如果過期的 key 比率超過 1/4,那就重複步驟 1;
惰性刪除
除了定期遍歷之外,它還會使用惰性策略來刪除過期的 key,所謂惰性策略就是在客戶端訪問這個 key 的時候,redis 對 key 的過期時間進行檢查,如果過期了就立即刪除,不會給你返回任何東西。
定期刪除是集中處理,惰性刪除是零散處理。
為什麼要採用定期刪除+惰性刪除2種策略呢?
如果過期就刪除。假設redis裡放了10萬個key,都設定了過期時間,你每隔幾百毫秒,就檢查10萬個key,那redis基本上就死了,cpu負載會很高的,消耗在你的檢查過期key上了
但是問題是,定期刪除可能會導致很多過期key到了時間並沒有被刪除掉,那咋整呢?所以就是惰性刪除了。這就是說,在你獲取某個key的時候,redis會檢查一下 ,這個key如果設定了過期時間那麼是否過期了?如果過期了此時就會刪除,不會給你返回任何東西。
並不是key到時間就被刪除掉,而是你查詢這個key的時候,redis再懶惰的檢查一下
通過上述兩種手段結合起來,保證過期的key一定會被幹掉。
所以說用了上述2種策略後,下面這種現象就不難解釋了:資料明明都過期了,但是還佔有著記憶體
記憶體淘汰策略
這個問題可能有小夥伴們遇到過,放到Redis中的資料怎麼沒了?
因為Redis將資料放到記憶體中,記憶體是有限的,比如redis就只能用10個G,你要是往裡面寫了20個G的資料,會咋辦?當然會幹掉10個G的資料,然後就保留10個G的資料了。那幹掉哪些資料?保留哪些資料?當然是幹掉不常用的資料,保留常用的資料了
Redis提供的記憶體淘汰策略有如下幾種:
- noeviction 不會繼續服務寫請求 (DEL 請求可以繼續服務),讀請求可以繼續進行。這樣可以保證不會丟失資料,但是會讓線上的業務不能持續進行。這是預設的淘汰策略。
- volatile-lru 嘗試淘汰設定了過期時間的 key,最少使用的 key 優先被淘汰。沒有設定過期時間的 key 不會被淘汰,這樣可以保證需要持久化的資料不會突然丟失。(這個是使用最多的)
- volatile-ttl 跟上面一樣,除了淘汰的策略不是 LRU,而是 key 的剩餘壽命 ttl 的值,ttl 越小越優先被淘汰。
- volatile-random 跟上面一樣,不過淘汰的 key 是過期 key 集合中隨機的 key。
- allkeys-lru 區別於 volatile-lru,這個策略要淘汰的 key 物件是全體的 key 集合,而不只是過期的 key 集合。這意味著沒有設定過期時間的 key 也會被淘汰。
- allkeys-random 跟上面一樣,不過淘汰的策略是隨機的 key。allkeys-random 跟上面一樣,不過淘汰的策略是隨機的 key。
Redis持久化策略
Redis的資料是存在記憶體中的,如果Redis發生宕機,那麼資料會全部丟失,因此必須提供持久化機制。
Redis 的持久化機制有兩種,第一種是快照(RDB),第二種是 AOF 日誌。快照是一次全量備份,AOF 日誌是連續的增量備份。快照是記憶體資料的二進位制序列化形式,在儲存上非常緊湊,而 AOF 日誌記錄的是記憶體資料修改的指令記錄文字。AOF 日誌在長期的執行過程中會變的無比龐大,資料庫重啟時需要載入 AOF 日誌進行指令重放,這個時間就會無比漫長。所以需要定期進行 AOF 重寫,給 AOF 日誌進行瘦身。
RDB是通過Redis主程序fork子程序,讓子程序執行磁碟 IO 操作來進行 RDB 持久化,AOF 日誌儲存的是 Redis 伺服器的順序指令序列,AOF 日誌只記錄對記憶體進行修改的指令記錄。即RDB記錄的是資料,AOF記錄的是指令
RDB和AOF到底該如何選擇
- 不要僅僅使用 RDB,因為那樣會導致你丟失很多資料,因為RDB是隔一段時間來備份資料
- 也不要僅僅使用 AOF,因為那樣有兩個問題,第一,通過 AOF 做冷備沒有RDB恢復速度快; 第二,RDB 每次簡單粗暴生成資料快照,更加健壯,可以避免 AOF 這種複雜的備份和恢復機制的 bug
- 用RDB恢復記憶體狀態會丟失很多資料,重放AOP日誌又很慢。Redis4.0退出了混合持久化來解決這個問題。將 rdb 檔案的內容和增量的 AOF 日誌檔案存在一起。這裡的 AOF 日誌不再是全量的日誌,而是自持久化開始到持久化結束的這段時間發生的增量 AOF 日誌,通常這部分 AOF 日誌很小。於是在 Redis 重啟的時候,可以先載入 rdb 的內容,然後再重放增量 AOF 日誌就可以完全替代之前的 AOF 全量檔案重放,重啟效率因此大幅得到提升。
快取雪崩和快取穿透
快取雪崩是什麼?
假設有如下一個系統,高峰期請求為5000次/秒,4000次走了快取,只有1000次落到了資料庫上,資料庫每秒1000的併發是一個正常的指標,完全可以正常工作,但如果快取宕機了,每秒5000次的請求會全部落到資料庫上,資料庫立馬就死掉了,因為資料庫一秒最多抗2000個請求,如果DBA重啟資料庫,立馬又會被新的請求打死了,這就是快取雪崩。

如何解決快取雪崩
- 事前:redis高可用,主從+哨兵,redis cluster,避免全盤崩潰
- 事中:本地ehcache快取 + hystrix限流&降級,避免MySQL被打死
- 事後:redis持久化,快速恢復快取資料
快取穿透是什麼?
假如客戶端每秒傳送5000個請求,其中4000個為黑客的惡意攻擊,即在資料庫中也查不到。舉個例子,使用者id為正數,黑客構造的使用者id為負數,
如果黑客每秒一直髮送這4000個請求,快取就不起作用,資料庫也很快被打死。
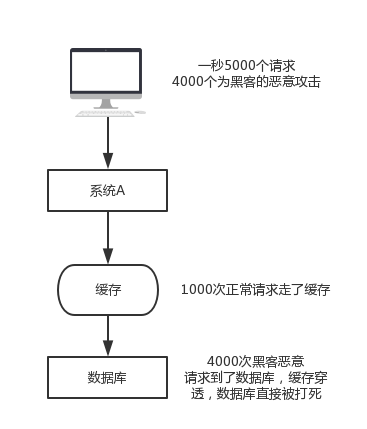
如何解決快取穿透
查詢不到的資料也放到快取,value為空,如set -999 “”
總而言之,快取雪崩就是快取失效,請求全部全部打到資料庫,資料庫瞬間被打死。快取穿透就是查詢了一個一定不存在的資料,並且從儲存層查不到的資料沒有寫入快取,這將導致這個不存在的資料每次請求都要到儲存層去查詢,失去了快取的意義
參考資料
咕泡學院公開課
《Redis 深度歷險:核心原理與應用實踐》
https://github.com/doocs/advanced-java
參考部落格
[1]https://www.toutiao.com/i6636576359931970062/
[2]https://www.cnblogs.com/jiahaoJAVA/p/6244278.html#4053693
[3]https://github.com/doocs/advanced-java
[4]https://blog.csdn.net/zeb_perfect/article/details/54135506
Redis實現分散式鎖
[5]https://mp.weixin.qq.com/s/8fdBKAyHZrfHmSajXT_dnA