
Java8 Stream API介紹
http://blog.csdn.net/chaoer89/article/details/52389458
Stream API是Java8中處理集合的關鍵元件,提供了各種豐富的函式式操作。
Stream的建立
任何集合都可以轉換為Stream:
//陣列
String[] strArr = new String[]{"aa","bb" - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Stream的簡單使用
Stream的使用分為兩種型別:
-
Intermediate,一個Stream可以呼叫0到多個Intermediate型別操作,每次呼叫會對Stream做一定的處理,返回一個新的Stream,這類操作都是惰性化的(lazy),就是說,並沒有真正開始流的遍歷。
常用操作:map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel -
Terminal,一個Stream只能執行一次terminal 操作,而且只能是最後一個操作,執行terminal操作之後,Stream就被消費掉了,並且產生一個結果。
常用操作:forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny
使用示例:
/********** Intermediate **********/
//filter 過濾操作
streamArr.filter(str -> str.startsWith("a"));
//map 遍歷和轉換操作
streamArr.map(String::toLowerCase);
//flatMap 將流展開
List<String> list1 = new ArrayList<>();
list1.add("aa");list1.add("bb");
List<String> list2 = new ArrayList<>();
list2.add("cc");list2.add("dd");
Stream.of(list1,list2).flatMap(str -> str.stream()).collect(Collectors.toList());
//limit 提取子流
streamArr.limit(1);
//skip 跳過
streamArr.skip(1);
//peek 產生相同的流,支援每個元素呼叫一個函式
streamArr.peek(str - > System.out.println("item:"+str));
//distinct 去重
Stream.of("aa","bb","aa").distinct();
//sorted 排序
Stream.of("aaa","bb","c").sorted(Comparator.comparing(String::length).reversed());
//parallel 轉為並行流,謹慎使用
streamArr.parallel();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
/********** Terminal **********/
//forEach
streamArr.forEach(System.out::println);
//forEachOrdered 如果希望順序執行並行流,請使用該方法
streamArr.parallel().forEachOrdered(System.out::println);
//toArray 收集到陣列中
streamArr.filter(str -> str.startsWith("a")).toArray(String[]::new);
//reduce 聚合操作
streamArr.reduce((str1,str2) -> str1+str2);
//collect 收集到List中
streamArr.collect(Collectors.toList());
//collect 收集到Set中
streamArr.collect(Collectors.toSet());
//min 取最小值?
IntStream.of(1,2,3,4).min();
Stream.of(arr).min(String::compareTo);
//max 取最大值?
IntStream.of(1,2,3,4).max();
Stream.of(arr).max(String::compareTo);
//count 計算總量?
streamArr.count();
//anyMatch 判斷流中是否含有匹配元素
boolean hasMatch = streamArr.anyMatch(str -> str.startsWith("a"));
//allMatch 判斷流中是否全部匹配
boolean hasMatch = streamArr.allMatch(str -> str.startsWith("a"));
//noneMatch 判斷流中是否全部不匹配
boolean hasMatch = streamArr.noneMatch(str -> str.startsWith("a"));
//findFirst 找到第一個就返回
streamArr.filter(str -> str.startsWith("a")).findFirst();
//findAny 找到任意一個就返回
streamArr.filter(str -> str.startsWith("a")).findAny();- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
收集結果
collect操作主要用於將stream中的元素收集到一個集合容器中,collect函式的定義如下:
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);- 1
- 2
- 3
第一個引數Supplier用於生成一個目標集合容器型別的例項;
函式BiConsumer
Set<String> result = Stream.of("aa", "bb", "cc", "aa").collect(
() -> new HashSet<String>(),
(set, item) -> set.add(item),
(set, subSet) -> set.addAll(subSet));- 1
- 2
- 3
- 4
以上寫法可以使用操作符“::”簡化,語法如下:
- 物件::例項方法
- 類::靜態方法
- 類::例項方法
Set<String> result = Stream.of("aa", "bb", "cc", "aa").collect(
HashSet::new,
HashSet::add,
HashSet::addAll);- 1
- 2
- 3
- 4
java.util.stream.Collectors類中已經預定義好了toList,toSet,toMap,toCollection等方便使用的方法,所以以上程式碼還可以簡化如下:
Set<String> result2 = Stream.of("aa", "bb", "cc", "aa").collect(Collectors.toSet());- 1
將結果收集到Map中,Collectors.toMap方法的兩個過載定義如下:
- keyMapper函式用於從例項T中得到一個K型別的Map key;
- valueMapper函式用於從例項T中得到一個U型別的Map value;
- mergeFunction函式用於處理key衝突的情況,預設為throwingMerger(),丟擲IllegalStateException異常;
- mapSupplier函式用於生成一個Map例項;
public static <T, K, U>
Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper) {
return toMap(keyMapper, valueMapper, throwingMerger(), HashMap::new);
}
public static <T, K, U, M extends Map<K, U>>
Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction,
Supplier<M> mapSupplier) {
BiConsumer<M, T> accumulator
= (map, element) -> map.merge(keyMapper.apply(element),
valueMapper.apply(element), mergeFunction);
return new CollectorImpl<>(mapSupplier, accumulator, mapMerger(mergeFunction), CH_ID);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
假設有一個User實體類,有方法getId(),getName(),getAge()等方法,現在想要將User型別的流收集到一個Map中,示例如下:
Stream<User> userStream = Stream.of(new User(0, "張三", 18), new User(1, "張四", 19), new User(2, "張五", 19), new User(3, "老張", 50));
Map<Integer, User> userMap = userSteam.collect(Collectors.toMap(User::getId, item -> item));- 1
- 2
- 3
假設要得到按年齡分組的Map<Integer,List<User>>,可以按這樣寫:
Map<Integer, List<User>> ageMap = userStream.collect(Collectors.toMap(User::getAge, Collections::singletonList, (a, b) -> {
List<User> resultList = new ArrayList<>(a);
resultList.addAll(b);
return resultList;
}));- 1
- 2
- 3
- 4
- 5
這種寫法雖然可以實現分組功能,但是太過繁瑣,好在Collectors中提供了groupingBy方法,可以用來實現該功能,簡化後寫法如下:
Map<Integer, List<User>> ageMap2 = userStream.collect(Collectors.groupingBy(User::getAge));- 1
類似的,Collectors中還提供了partitioningBy方法,接受一個Predicate函式,該函式返回boolean值,用於將內容分為兩組。假設User實體中包含性別資訊getSex(),可以按如下寫法將userStream按性別分組:
Map<Boolean, List<User>> sexMap = userStream.collect(Collectors.partitioningBy(item -> item.getSex() > 0));- 1
Collectors中還提供了一些對分組後的元素進行downStream處理的方法:
- counting方法返回所收集元素的總數;
- summing方法會對元素求和;
- maxBy和minBy會接受一個比較器,求最大值,最小值;
- mapping函式會應用到downstream結果上,並需要和其他函式配合使用;
Map<Integer, Long> sexCount = userStream.collect(Collectors.groupingBy(User::getSex,Collectors.counting()));
Map<Integer, Integer> ageCount = userStream.collect(Collectors.groupingBy(User::getSex,Collectors.summingInt(User::getAge)));
Map<Integer, Optional<User>> ageMax = userStream.collect(Collectors.groupingBy(User::getSex,Collectors.maxBy(Comparator.comparing(User::getAge))));
Map<Integer, List<String>> nameMap = userStream.collect(Collectors.groupingBy(User::getSex,Collectors.mapping(User::getName,Collectors.toList())));- 1
- 2
- 3
- 4
- 5
- 6
- 7
以上為各種collectors操作的使用案例。
Optional型別
Optional<T> 是對T型別物件的封裝,它不會返回null,因而使用起來更加安全。
ifPresent方法接受一個函式作為形參,如果存在當前Optinal存在值則使用當前值呼叫函式,否則不做任何操作,示例如下:
Optional<T> optional = ...
optional.ifPresent(v -> results.add(v));- 1
- 2
orElse方法,orElseGet方法,當值不存在時產生一個替代值,示例如下:
String result = optional.orElse("defaultValue");
String result = optional.orElseGet(() -> getDefalutValue());- 1
- 2
可以使用Optional.of()方法和Optional.empty()方法來建立一個Optional型別物件,示例如下:
a - b > 0 ? Optional.of(a - b) : Optional.empty();- 1
函式式介面
Steam.filter方法接受一個Predicate函式作為入參,該函式返回一個boolean型別,下圖為Stream和COllectors方法引數的函式式介面:
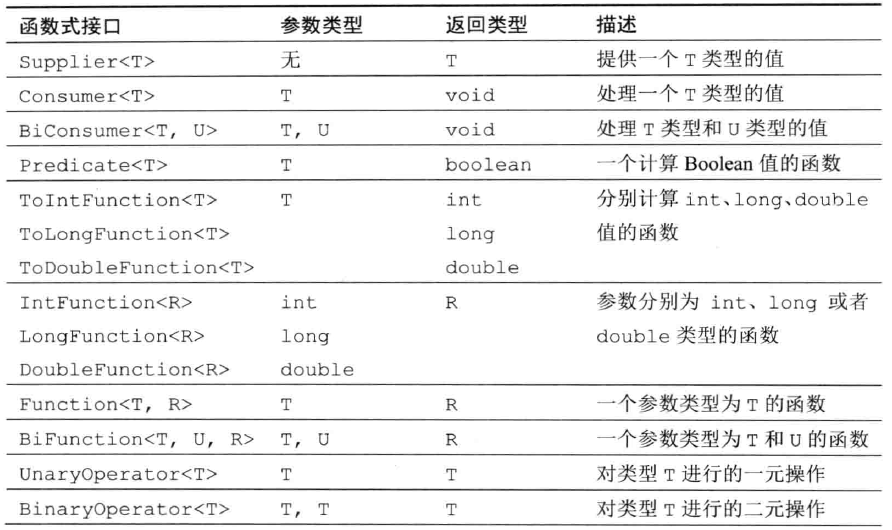
總結
- Stream的處理總會在最後的Terminal操作才會真正執行;
- 沒有內部儲存,也不能改變使用到的資料來源,每次操作都會生成一個新的流;
- 並行流使用fork/join 池來實現,對於非CPU密集型任務,需要謹慎使用;
- 相對於迴圈遍歷操作程式碼可讀性更高;
Stream API是Java8中處理集合的關鍵元件,提供了各種豐富的函式式操作。
Stream的建立
任何集合都可以轉換為Stream:
//陣列
String[] strArr = new String[]{"aa","bb","cc"};
Stream<String> streamArr = Stream.of(strArr);
Stream<String> streamArr2 = Arrays.stream(strArr);
//集合
List<String> list = new ArrayList<>();
Stream<String> streamList = list.stream();
Stream<String> streamList2 = list.parallelStream();//並行執行
...
//generator 生成無限長度的stream
Stream.generate(Math::random);
// iterate 也是生成無限長度的Stream,其元素的生成是重複對給定的種子值呼叫函式來生成的
Stream.iterate(1, item -> item + 1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Stream的簡單使用
Stream的使用分為兩種型別:
-
Intermediate,一個Stream可以呼叫0到多個Intermediate型別操作,每次呼叫會對Stream做一定的處理,返回一個新的Stream,這類操作都是惰性化的(lazy),就是說,並沒有真正開始流的遍歷。
常用操作:map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel -
Terminal,一個Stream只能執行一次terminal 操作,而且只能是最後一個操作,執行terminal操作之後,Stream就被消費掉了,並且產生一個結果。
常用操作:forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny
使用示例:
/********** Intermediate **********/
//filter 過濾操作
streamArr.filter(str -> str.startsWith("a"));
//map 遍歷和轉換操作
streamArr.map(String::toLowerCase);
//flatMap 將流展開
List<String> list1 = new ArrayList<>();
list1.add("aa");list1.add("bb");
List<String> list2 = new ArrayList<>();
list2.add("cc");list2.add("dd");
Stream.of(list1,list2).flatMap(str -> str.stream()).collect(Collectors.toList());
//limit 提取子流
streamArr.limit(1);
//skip 跳過
streamArr.skip(1);
//peek 產生相同的流,支援每個元素呼叫一個函式
streamArr.peek(str - > System.out.println("item:"+str));
//distinct 去重
Stream.of("aa","bb","aa").distinct();
//sorted 排序
Stream.of("aaa","bb","c").sorted(Comparator.comparing(String::length).reversed());
//parallel 轉為並行流,謹慎使用
streamArr.parallel();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
/********** Terminal **********/
//forEach
streamArr.forEach(System.out::println);
//forEachOrdered 如果希望順序執行並行流,請使用該方法
streamArr.parallel().forEachOrdered(System.out::println);
//toArray 收集到陣列中
streamArr.filter(str -> str.startsWith("a")).toArray(String[]::new);
//reduce 聚合操作
streamArr.reduce((str1,str2) -> str1+str2);
//collect 收集到List中
streamArr.collect(Collectors.toList());
//collect 收集到Set中
streamArr.collect(Collectors.toSet());
//min 取最小值?
IntStream.of(1,2,3,4).min();
Stream.of(arr).min(String::compareTo);
//max 取最大值?
IntStream.of(1,2,3,4).max();
Stream.of(arr).max(String::compareTo);
//count 計算總量?
streamArr.count();
//anyMatch 判斷流中是否含有匹配元素
boolean hasMatch = streamArr.anyMatch(str -> str.startsWith("a"));
//allMatch 判斷流中是否全部匹配
boolean hasMatch = streamArr.allMatch(str -> str.startsWith("a"));
//noneMatch 判斷流中是否全部不匹配
boolean hasMatch = streamArr.noneMatch(str -> str.startsWith("a"));
//findFirst 找到第一個就返回
streamArr.filter(str -> str.startsWith("a")).findFirst();
//findAny 找到任意一個就返回
streamArr.filter(str -> str.startsWith("a")).findAny();- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
收集結果
collect操作主要用於將stream中的元素收集到一個集合容器中,collect函式的定義如下:
<R> R collect(Supplier