
[深度學習]深度學習框架總結
阿新 • • 發佈:2019-01-02
深度學習庫比較
| 庫名 | 主語言 | 從語言 | 速度 | 靈活性 | 文件 | 適合模型 | 平臺 | 上手難易 | 開發者 | 模式 |
|---|---|---|---|---|---|---|---|---|---|---|
| Tensorflo | C++ | cuda/python/Matlab/Ruby/R | 中等 | 好 | 中等 | CNN/RNN | Linux,OSX | 難 | 分散式/宣告式 | |
| Caffe | C++ | cuda/python/Matlab | 快 | 一般 | 全面 | CNN | 所有系統 | 中等 | 賈楊清 | 宣告式 |
| PyTorc | python | C/C++ | 中等 | 好 | 中等 | - | – | 中等 | ||
| MXNet | c++ | cuda/R/julia | 快 | 好 | 全面 | CNN | 所有系統 | 中等 | 李沐和陳天奇等 | 分散式/宣告式/命令式 |
| Torch | lua | C/cuda | 快 | 好 | 全面 | CNN/RNN | Linux,OSX | 中等 | 命令式 | |
| Theano | python | c++/cuda | 中等 | 好 | 中等 | CNN/RNN | Linux, OSX | 易 | 蒙特利爾理工學院 | 命令式 |
1.TensorFlow 的優點是:
它有一個直觀的結構 ,顧名思義它有 “張量流”,你可以輕鬆地可視每個圖中的每一個部分。 輕鬆地在 cpu / gpu 上進行分散式計算 平臺的靈活性 。可以隨時隨地執行模型,無論是在移動端、伺服器還是 PC 上。
1.1 TensorFlow 的限制
儘管 TensorFlow 是強大的,它仍然是一個低水平庫,例如,它可以被認為是機器級語言,但對於大多數功能,您需要自己去模組化和高階介面,如 keras
它仍然在繼續開發和維護,這是多麼��啊!
它取決於你的硬體規格,配置越高越好
不是所有變成語言能使用它的 API 。
TensorFlow 中仍然有很多庫需要手動匯入,比如 OpenCL 支援。
上面提到的大多數是在 TensorFlow 開發人員的願景,他們已經制定了一個路線圖,計劃庫未來應該如何開發1.2 ensorFlow工作流程
建立一個計算圖, 任何的數學運算可以使用 TensorFlow 支撐。 初始化變數, 編譯預先定義的變數 建立 session, 這是神奇的開始的地方 ! 在 session 中執行圖, 編譯圖形被傳遞到 session ,它開始執行它。 關閉 session, 結束這次使用。
1.3 入門教程
2.Caffe
Caffe57是純粹的C++/CUDA架構,支援命令列、Python和MATLAB介面;可以在CPU和GPU173直接無縫切換:
Caffe::set_mode(Caffe::GPU);2.1 Caffe的優勢
1.上手快:模型與相應優化都是以文字形式而非程式碼形式給出。
2.Caffe給出了模型的定義、最優化設定以及預訓練的權重,方便立即上手。
3.速度快:能夠執行最棒的模型與海量的資料。
4.Caffe與cuDNN結合使用,測試AlexNet模型,在K40上處理每張圖片只需要1.17ms.
5.模組化:方便擴充套件到新的任務和設定上。
6.可以使用Caffe提供的各層型別來定義自己的模型。
7.開放性:公開的程式碼和參考模型用於再現。
8.社群好:可以通過BSD-2參與開發與討論。2.2 Caffe 架構
2.2.1 預處理影象的leveldb構建
輸入:一批影象和label (2和3)
輸出:leveldb (4)
指令裡包含如下資訊:
conver_imageset (構建leveldb的可執行程式)
train/ (此目錄放處理的jpg或者其他格式的影象)
label.txt (影象檔名及其label資訊)
輸出的leveldb資料夾的名字
CPU/GPU (指定是在cpu上還是在gpu上執行code)2.2.2 CNN網路配置檔案
Imagenet_solver.prototxt (包含全域性引數的配置的檔案)
Imagenet.prototxt (包含訓練網路的配置的檔案)
Imagenet_val.prototxt (包含測試網路的配置檔案)2.3 教程
3.pytorch框架
pytorch,語法類似numpy,非常高效;基於pytorch開發深度學習演算法,方便快速,適合cpu和gpu計算。pytorch支援動態構建神經網路結構,從而可以提升挽留過結構的重用性。
這是一個基於Python的科學計算包,其旨在服務兩類場合:
1.替代numpy發揮GPU潛能
2.一個提供了高度靈活性和效率的深度學習實驗性平臺3.1 PyTorch優勢
1.執行在 GPU 或 CPU 之上、基礎的張量操作庫,
2.內建的神經網路庫
3.模型訓練功能
3.支援共享記憶體的多程序併發(multiprocessing )庫。PyTorch開發團隊表示:這對資料載入和 hogwild 訓練十分有幫助。
4.PyTorch 的首要優勢是,它處於機器學習第一大語言 Python 的生態圈之中,使得開發者能接入廣大的 Python 庫和軟體。因此,Python 開發者能夠用他們熟悉的風格寫程式碼,而不需要針對外部 C 語言或 C++ 庫的 wrapper,使用它的專門語言。雷鋒網(公眾號:雷鋒網)獲知,現有的工具包可以與 PyTorch 一起執行,比如 NumPy、SciPy 和 Cython(為了速度把 Python 編譯成 C 語言)。
4.PyTorch 還為改進現有的神經網路,提供了更快速的方法——不需要從頭重新構建整個網路3.2 PyTorch工具包
1.torch :類似 NumPy 的張量庫,強 GPU 支援
2.torch.autograd :基於 tape 的自動區別庫,支援 torch 之中的所有可區分張量執行。
3.torch.nn :為最大化靈活性未涉及、與 autograd 深度整合的神經網路庫
4.torch.optim:與 torch.nn 一起使用的優化包,包含 SGD, RMSProp, LBFGS, Adam 等標準優化方式
5.torch.multiprocessing: python 多程序併發,程序之間 torch Tensors 的記憶體共享。
6.torch.utils:資料載入器。具有訓練器和其他便利功能。 Trainer and other utility functions for convenience
7.torch.legacy(.nn/.optim) :處於向後相容性考慮,從 Torch 移植來的 legacy 程式碼。3.3 教程
4 MXNet框架
4.1 優缺點
4.1.1 優點
1.速度快省視訊記憶體。在復現一個caffe
2.支援多語言
3.分散式4.1.2 缺點
1. API文件差。這個問題很多人也提過了,很多時候要看原始碼才能確定一個函式具體是做什麼的,看API描述有時候並不靠譜,因為文件有點過時。
2. 缺乏完善的自定義教程。比如寫data iter的時候,train和validation的data shape必須一致,這是我當時找了半天的一個bug。
3.程式碼小bug有點多。mxnet的大神們開發速度確實是快,但是有的layer真的是有bug,暑假我們就修了不少。 4.2 MXNet架構
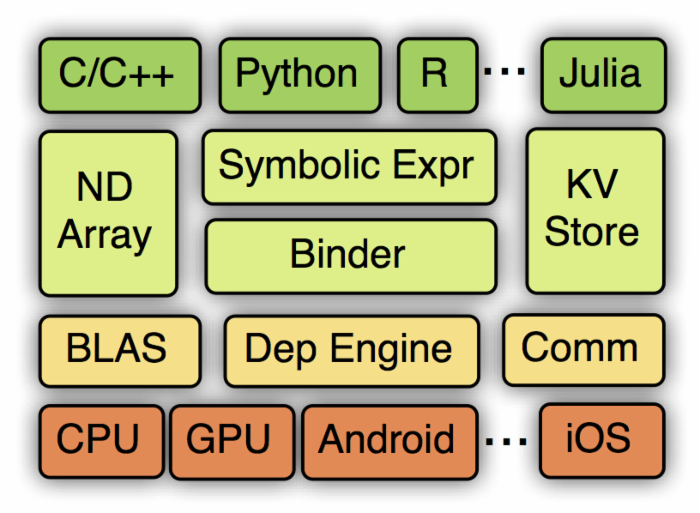
從上到下分別為各種主語言的嵌入,程式設計介面(矩陣運算,符號表達式,分散式通訊),兩種程式設計模式的統一系統實現,以及各硬體的支援。接下一章我們將介紹程式設計介面,然後下一章介紹系統實現。之後我們給出一些實驗對比結果,以及討論MXNet的未來。
##4.2 MXNet程式設計介面
1.Symbol : 宣告式的符號表達式
2.NDArray :命令式的張量計算
3.KVStore :多裝置間的資料互動
4.讀入資料模組
5.訓練模組
#5. Torch框架
##5.1 Torch誕生
Torch誕生已經有十年之久,但是真正起勢得益於去年Facebook開源了大量Torch的深度學習模組和擴充套件。Torch另外一個特殊之處是採用了不怎麼流行的程式語言Lua(該語言曾被用來開發視訊遊戲)。
5.2 Torch優缺點
5.2.1 優點
1)Facebook力推的深度學習框架,主要開發語言是C和Lua
2)有較好的靈活性和速度
3)它實現並且優化了基本的計算單元,使用者可以很簡單地在此基礎上實現自己的演算法,不用浪費精力在計算優化上面。核心的計算單元使用C或者cuda做了很好的優化。在此基礎之上,使用lua構建了常見的模型
4)速度最快,見convnet-benchmarks
5)支援全面的卷積操作:
時間卷積:輸入長度可變,而TF和Theano都不支援,對NLP非常有用;
3D卷積:Theano支援,TF不支援,對視訊識別很有用5.2.2 缺點
1)是介面為lua語言,需要一點時間來學習。
2)沒有Python介面
3)與Caffe一樣,基於層的網路結構,其擴充套件性不好,對於新增加的層,需要自己實現(forward, backward and gradient update)5.3 Torch教程
6. Theano框架
6.2 Theano優缺點
6.2.1 優點
1)2008年誕生於蒙特利爾理工學院,主要開發語言是Python
2)Theano派生出了大量深度學習Python軟體包,最著名的包括Blocks和Keras
3)Theano的最大特點是非常的靈活,適合做學術研究的實驗,且對遞迴網路和語言建模有較好的支援
4)是第一個使用符號張量圖描述模型的架構
5)支援更多的平臺
6)在其上有可用的高階工具:Blocks, Keras等6.2.2 缺點
1)編譯過程慢,但同樣採用符號張量圖的TF無此問題
2)import theano也很慢,它匯入時有很多事要做
3)作為開發者,很難進行改進,因為code base是Python,而C/CUDA程式碼被打包在Python字串中