
(2)Hadoop核心 -- java程式碼對MapReduce的例子1
案例一:wordcount字數統計功能
1.1 先準備兩個txt檔案,並上傳到hdfs上
test1.txt
hello zhangsan lisi nihao hai zhangsan nihao lisi x xiaoming
test2.txt
zhangsan a
lisi b
wangwu c
jiji 7
haha xiaoming
xiaoming is gril
1.2 編寫 Mapper 程式碼
import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; /** * 這部分的輸入是由mapreduce自動讀取進來的 * 簡單的統計單詞出現次數<br> * KEYIN 預設情況下,是mapreduce所讀取到的一行文字的起始偏移量,Long型別,在hadoop中有其自己的序列化類LongWriteable * VALUEIN 預設情況下,是mapreduce所讀取到的一行文字的內容,hadoop中的序列化型別為Text * KEYOUT 是使用者自定義邏輯處理完成後輸出的KEY,在此處是單詞,String * VALUEOUT 是使用者自定義邏輯輸出的value,這裡是單詞出現的次數,Long * @author Administrator * */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { //這是mapreduce讀取到的一行字串 String line = value.toString(); String[] words = line.split(" "); for (String word : words) { //將單詞輸出為key,次數輸出為value,這行資料會輸到reduce中 context.write(new Text(word), new LongWritable(1)); } } }
1.3 編寫Reduce的程式碼
import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; /** * 第一個Text: 是傳入的單詞名稱,是Mapper中傳入的 * 第二個:LongWritable 是該單詞出現了多少次,這個是mapreduce計算出來的,比如 hello出現了11次 * 第三個Text: 是輸出單詞的名稱 ,這裡是要輸出到文字中的內容 * 第四個LongWritable: 是輸出時顯示出現了多少次,這裡也是要輸出到文字中的內容 * @author Administrator * */ public class WordCountReduce extends Reducer<Text, LongWritable, Text, LongWritable> { @Override protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { long count = 0; for (LongWritable num : values) { count += num.get(); } context.write(key, new LongWritable(count)); } }
1.4 編寫main方法執行這個mapreduce
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 相當於執行在yarn中的客戶端 * @author Administrator * */ public class WordCountDriver { public static void main(String[] args) throws IOException { Configuration conf = new Configuration(); //如果是打包在linux上執行,則不需要寫這兩行程式碼 /* //指定執行在yarn中 conf.set("mapreduce.framework.name", "yarn"); //指定resourcemanager的主機名 conf.set("yarn.resourcemanager.hostname", "server1");*/ Job job = Job.getInstance(conf); //使得hadoop可以根據類包,找到jar包在哪裡 job.setJarByClass(WordCountDriver.class); //指定Mapper的類 job.setMapperClass(WordCountMapper.class); //指定reduce的類 job.setReducerClass(WordCountReduce.class); //設定Mapper輸出的型別 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); //設定最終輸出的型別 job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //指定輸入檔案的位置,這裡為了靈活,接收外部引數 FileInputFormat.setInputPaths(job, new Path(args[0])); //指定輸入檔案的位置,這裡接收啟動引數 FileOutputFormat.setOutputPath(job, new Path(args[1])); //將job中的引數,提交到yarn中執行 //job.submit(); try { job.waitForCompletion(true); //這裡的為true,會列印執行結果 } catch (ClassNotFoundException | InterruptedException e) { e.printStackTrace(); } } }
1.5:把程式碼放在hadoop中執行
程式碼寫完了,要怎麼執行呢?
(1)首先,肯定不是直接執行main方法執行,因為目前的程式碼,並不知道hadoop部署在哪裡,我們要做的是,把這個專案打包,如果是maven專案,則使用maven package命令打包,把相應的jar包,上傳到伺服器中。
(2)其次,需要把之前的兩個文字檔案,text1.txt和text2.txt上傳到hdfs中,因為既然是大資料,那麼在實際環境中,肯定不可能是這麼小的資料來進行計算,肯定是有著大量的資料,而這些資料,靠一臺伺服器肯定是放不下去的,也只有像hdfs這種大檔案儲存,或者一些其它的專門存放大資料的地方,才能存放了,我們使用如下的命令,把檔案上傳到hdfs中,如果這些命令看不懂,可以先看上一章節,hdfs的使用。
//建立一個目錄 hadoop fs -mkdir -p /wordcount/input //上傳檔案 hadoop fs -put text1.txt text2.txt /wordcount/input
(3)執行程式碼,帶有main方法的程式碼,是可以使用java命令執行的,但是因為hadoop依賴了很多別的jar包,這樣子執行程式碼,需要新增大量的依賴,寫的命令很複雜,hadoop提供了這樣的一個命令來執行程式碼
hadoop jar wordcount.jar com.zxj.hadoop.demo.mapreduce.wordcount.WordCountDriver /wordcount/input /wordcount/output
這裡來解釋一下這條命令的意思,jar說明使用hadoop中內建的jar命令,也就是執行一個jar包。wordcount.jar 這個是上傳的程式碼,也就是我們之前寫的程式碼,打包之後上傳到伺服器中的名字。com.zxj.hadoop.demo.mapreduce.wordcount.WordCountDriver是需要執行哪個類,因為一個jar包中有可能有多個main方法,這樣可以指定使用哪個類啟動。最後兩個引數 /wordcount/input 和 /wordcount/output,這是我們的程式碼中自定義的兩個引數,第一個是檔案的目錄(意味著可以讀取一整個目錄中的多個檔案),第二個是輸出結果的目錄。
執行完成之後,會有如下結果,如果沒有丟擲異常,或者寫明失敗,帶有success的就是成功了。

現在我們可以去看一下輸出結果
檢視輸出的檔案
hadoop fs -ls /wordcount/output

第一個檔案代表執行成功,第二個檔案是輸出結果檔案,執行如下命令檢視
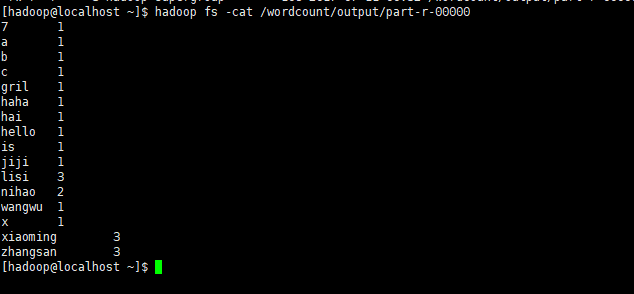
從上圖發現,zhangsan出現了3次,xiaoming出現了3次,nihao出現了2次,其它的是1次
三:自定義序列化的類
當輸出的結果比較複雜的時候,就沒辦法使用Text,LongWritable這種型別來輸出,這個時候我們可以自定義一個序列化的類,這個序列化不是jdk的序列化,而是hadoop自已的序列化,我們需要實現它
如下文件,儲存並命名為staff.txt:
張三 江西 打車 200 李四 廣東 住宿 600 王五 北京 伙食 320 張三 江西 話費 50 張三 湖南 打車 900 週六 上海 採購 3000 李四 西藏 旅遊 1000 王五 北京 借款 500 李四 上海 話費 50 週六 北京 打車 600 張三 廣東 租房 3050
3.1:自定義一個序列化的輸出bean
之前我們一直使用LongWriteable或者Text來作為輸入的內容,但是如果看這兩個物件的原始碼,它們都是實現了Writable介面的,這是一個hadoop自帶的序列化介面。
現在我們要輸出一些資訊,單單靠一個Text已經無法達到我們的效果的時候,我們就可以自定義一個物件,然後實現Writable介面如下的程式碼,就是自定義一個可序列化的bean
/**
* 封裝的bean
*/
public static class SpendBean implements Writable{
private Text userName;
private IntWritable money;
public SpendBean(Text userName, IntWritable money) {
this.userName = userName;
this.money = money;
}
/**
* 反序列化時必須有一個空參的構造方法
*/
public SpendBean(){}
/**
* 序列化的程式碼
* @param out
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
userName.write(out);
money.write(out);
}
/**
* 反序列化的程式碼
* @param in
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException {
userName = new Text();
userName.readFields(in);
money = new IntWritable();
money.readFields(in);
}
public Text getUserName() {
return userName;
}
public void setUserName(Text userName) {
this.userName = userName;
}
public IntWritable getMoney() {
return money;
}
public void setMoney(IntWritable money) {
this.money = money;
}
@Override
public String toString() {
return userName.toString() + "," + money.get();
}
}
3.2:編寫mapper
編寫mapper
/**
* Mapper
*/
public static class GroupUserMapper extends Mapper<LongWritable,Text,Text,SpendBean>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String val = value.toString();
String[] split = val.split("\t");
//這裡就不作字串異常的處理了,核心程式碼簡單點
String name = split[0];
String province = split[1];
String type = split[2];
int money = Integer.parseInt(split[3]);
SpendBean groupUser = new SpendBean();
groupUser.setUserName(new Text(name));
groupUser.setMoney(new IntWritable(money));
context.write(new Text(name),groupUser);
}
}
3.3:編寫reducer
編寫reducer
/**
* reducer
*/
public static class GroupUserReducer extends Reducer<Text,SpendBean,Text,SpendBean> {
/**
* 姓名
* @param key
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<SpendBean> values, Context context) throws IOException, InterruptedException {
int money = 0;//消費金額
//遍歷
for(SpendBean bean : values){
money += bean.getMoney().get();
}
//輸出彙總結果
context.write(key,new SpendBean(key,new IntWritable(money)));
}
}3.4:編寫main方法
編寫main方法
/**
* 編寫啟動類
* @param args
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(GroupUser.class); //設定jar中的啟動類,可以根據這個類找到相應的jar包
job.setMapperClass(GroupUserMapper.class); //設定mapper的類
job.setReducerClass(GroupUserRecuder.class); //設定reducer的類
job.setMapOutputKeyClass(Text.class); //mapper輸出的key
job.setMapOutputValueClass(SpendBean.class); //mapper輸出的value
job.setOutputKeyClass(Text.class); //最終輸出的資料型別
job.setOutputValueClass(SpendBean.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));//輸入的檔案位置
FileOutputFormat.setOutputPath(job,new Path(args[1]));//輸出的檔案位置
boolean b = job.waitForCompletion(true);//等待完成,true,列印進度條及內容
if(b){
//success
}
}完整的程式碼如下,這裡把幾個類都寫在一起了。
package com.zxj.hadoop.demo.mapreduce.staffspend.groupuser;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @Author 朱小杰
* 時間 2017-07-23 .16:33
* 說明 ...
*/
public class GroupUser {
/**
* Mapper
*/
public static class GroupUserMapper extends Mapper<LongWritable,Text,Text,SpendBean>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String val = value.toString();
String[] split = val.split("\t");
//這裡就不作字串異常的處理了,核心程式碼簡單點
String name = split[0];
String province = split[1];
String type = split[2];
int money = Integer.parseInt(split[3]);
SpendBean groupUser = new SpendBean();
groupUser.setUserName(new Text(name));
groupUser.setMoney(new IntWritable(money));
context.write(new Text(name),groupUser);
}
}
/**
* reducer
*/
public static class GroupUserReducer extends Reducer<Text,SpendBean,Text,SpendBean> {
/**
* 姓名
* @param key
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<SpendBean> values, Context context) throws IOException, InterruptedException {
int money = 0;//消費金額
//遍歷
for(SpendBean bean : values){
money += bean.getMoney().get();
}
//輸出彙總結果
context.write(key,new SpendBean(key,new IntWritable(money)));
}
}
/**
* 封裝的bean
*/
public static class SpendBean implements Writable{
private Text userName;
private IntWritable money;
public SpendBean(Text userName, IntWritable money) {
this.userName = userName;
this.money = money;
}
/**
* 反序列化時必須有一個空參的構造方法
*/
public SpendBean(){}
/**
* 序列化的程式碼
* @param out
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
userName.write(out);
money.write(out);
}
/**
* 反序列化的程式碼
* @param in
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException {
userName = new Text();
userName.readFields(in);
money = new IntWritable();
money.readFields(in);
}
public Text getUserName() {
return userName;
}
public void setUserName(Text userName) {
this.userName = userName;
}
public IntWritable getMoney() {
return money;
}
public void setMoney(IntWritable money) {
this.money = money;
}
@Override
public String toString() {
return userName.toString() + "," + money.get();
}
}
/**
* 編寫啟動類
* @param args
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(GroupUser.class); //設定jar中的啟動類,可以根據這個類找到相應的jar包
job.setMapperClass(GroupUserMapper.class); //設定mapper的類
job.setReducerClass(GroupUserReducer.class); //設定reducer的類
job.setMapOutputKeyClass(Text.class); //mapper輸出的key
job.setMapOutputValueClass(SpendBean.class); //mapper輸出的value
job.setOutputKeyClass(Text.class); //最終輸出的資料型別
job.setOutputValueClass(SpendBean.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));//輸入的檔案位置
FileOutputFormat.setOutputPath(job,new Path(args[1]));//輸出的檔案位置
boolean b = job.waitForCompletion(true);//等待完成,true,列印進度條及內容
if(b){
//success
}
}
}3.5:在hadoop中執行
然後執行maven clean package命令,重新打包,並且上傳到伺服器中。
我們也建立一個目錄,來存放之前的員工消費資訊
hadoop fs -mkdir -p /staffspend/input
把之前準備好的員工檔案上傳到這個目錄
hadoop fs -put staff.txt /staffspend/input
然後準備執行任務
hadoop jar hadoop-mapreduce-1.0.jar com.zxj.hadoop.demo.mapreduce.staffspend.groupuser.GroupUser /staffspend/input /staffspend/output
執行成功後,檢視輸出檔案
hadoop fs -cat /staffspend/output/part-r-00000

四:資料分割槽(按照不同型別輸出到不同的位置)
這樣的需求也經常會有,我可能並不是僅僅需要總的資料檢視,我還可能要檢視每一個型別,比如第三部分的檔案中,我可能想分別檢視每個省中,每個人分別用了多少錢。
這個時候我們對上第三部分的程式碼進行修改
我們要增加輸出bean中的省份欄位,紅色位置是修改過的部分
/**
* 封裝的bean
*/
public static class SpendBean implements Writable{
private Text userName;
private IntWritable money;
private Text province;
public SpendBean(Text userName, IntWritable money, Text province) {
this.userName = userName;
this.money = money;
this.province = province;
}
/**
* 反序列化時必須有一個空參的構造方法
*/
public SpendBean(){}
/**
* 序列化的程式碼
* @param out
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
userName.write(out);
money.write(out);
province.write(out);
}
/**
* 反序列化的程式碼
* @param in
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException {
userName = new Text();
userName.readFields(in);
money = new IntWritable();
money.readFields(in);
province = new Text();
province.readFields(in);
}
public Text getUserName() {
return userName;
}
public Text getProvince() {
return province;
}
public void setProvince(Text province) {
this.province = province;
}
public void setUserName(Text userName) {
this.userName = userName;
}
public IntWritable getMoney() {
return money;
}
public void setMoney(IntWritable money) {
this.money = money;
}
@Override
public String toString() {
return "SpendBean{" +
"userName=" + userName +
", money=" + money +
", province=" + province +
'}';
}
}可以看到,上面的bean並沒有改動什麼特別的東西,完全是加了一個省份欄位而已。
4.1:分割槽規則的程式碼
首先,如果要按照資料進行分割槽,我們肯定需要寫分割槽的程式碼來告訴hadoop,我們寫一個分割槽的類來繼承org.apache.hadoop.mapreduce.Partitioner
hadoop中的分割槽,是在mapper結束後的reducer中,所以下面的程式碼是在reducer時執行的,我們對不同的省份進行規則劃分,比如說江西就是對應的0分割槽
具體程式碼如下:
package com.zxj.hadoop.demo.mapreduce.staffspend.groupuser;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
import java.util.HashMap;
import java.util.Map;
/**
* @Author 朱小杰
* 時間 2017-07-29 .11:14
* 說明
* key ,value是mapper中輸出的型別,因為分割槽是在mapper完成之後進行的
*/
public class ProvincePartitioner extends Partitioner<Text, GroupUser.SpendBean> {
private static Map<String,Integer> provinces = new HashMap<>();
static {
//這裡給每一個省份編制一個分割槽
provinces.put("江西",0);
provinces.put("廣東",1);
provinces.put("北京",2);
provinces.put("湖南",3);
provinces.put("上海",4);
provinces.put("西藏",5);
}
/**
* 給指定的資料一個分割槽
* @param text
* @param spendBean
* @param numPartitions
* @return
*/
@Override
public int getPartition(Text text, GroupUser.SpendBean spendBean, int numPartitions) {
Integer province = provinces.get(spendBean.getProvince().toString());
province = province == null ? 6 : province; //如果在省份列表中找不到,則指定一個預設的分割槽
return province;
}
}
很簡單的程式碼,我們劃分了6個分割槽,如果有的省份在這6個分割槽中找不到,那餘下的就會進入第7個分割槽中。
4.2:設定分割槽程式碼
分割槽的程式碼既然寫完了,那麼就需要在執行的時候,指定這分割槽的規則是我們剛才寫的程式碼,位置在執行的main方法中,如下:
紅色部分是重點部分,也是改過的部分
/**
* 編寫啟動類
* @param args
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(GroupUser.class); //設定jar中的啟動類,可以根據這個類找到相應的jar包
job.setMapperClass(GroupUserMapper.class); //設定mapper的類
job.setReducerClass(GroupUserReducer.class); //設定reducer的類
job.setPartitionerClass(ProvincePartitioner.class);//指定資料分割槽規則,不是必須要的,根據業務需求分割槽
job.setNumReduceTasks(7); //設定相應的reducer數量,這個數量要與分割槽的大最數量一致
job.setMapOutputKeyClass(Text.class); //mapper輸出的key
job.setMapOutputValueClass(SpendBean.class); //mapper輸出的value
job.setOutputKeyClass(Text.class); //最終輸出的資料型別
job.setOutputValueClass(SpendBean.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));//輸入的檔案位置
FileOutputFormat.setOutputPath(job,new Path(args[1]));//輸出的檔案位置
boolean b = job.waitForCompletion(true);//等待完成,true,列印進度條及內容
if(b){
//success
}
}這裡再說明一下
job.setNumReduceTasks(7);
如果這個數值是1,那麼所有的資料全部會輸出到一個檔案中。
假如是2,那麼將會報錯。
假如超出分割槽大小,比如寫一個10,那麼多出來的檔案將會為空。所以一般是按最大需要分割槽數量寫。
4.3:分割槽的完整程式碼
下面貼出完整的程式碼
分割槽程式碼:
package com.zxj.hadoop.demo.mapreduce.staffspend.groupuser;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
import java.util.HashMap;
import java.util.Map;
/**
* @Author 朱小杰
* 時間 2017-07-29 .11:14
* 說明
* key ,value是mapper中輸出的型別,因為分割槽是在mapper完成之後進行的
*/
public class ProvincePartitioner extends Partitioner<Text, GroupUser.SpendBean> {
private static Map<String,Integer> provinces = new HashMap<>();
static {
//這裡給每一個省份編制一個分割槽
provinces.put("江西",0);
provinces.put("廣東",1);
provinces.put("北京",2);
provinces.put("湖南",3);
provinces.put("上海",4);
provinces.put("西藏",5);
}
/**
* 給指定的資料一個分割槽
* @param text
* @param spendBean
* @param numPartitions
* @return
*/
@Override
public int getPartition(Text text, GroupUser.SpendBean spendBean, int numPartitions) {
Integer province = provinces.get(spendBean.getProvince().toString());
province = province == null ? 6 : province; //如果在省份列表中找不到,則指定一個預設的分割槽
return province;
}
}其它程式碼,這些程式碼是寫在一個檔案中了
package com.zxj.hadoop.demo.mapreduce.staffspend.groupuser;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @Author 朱小杰
* 時間 2017-07-23 .16:33
* 說明 ...
*/
public class GroupUser {
/**
* Mapper
*/
public static class GroupUserMapper extends Mapper<LongWritable,Text,Text,SpendBean>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String val = value.toString();
String[] split = val.split("\t");
//這裡就不作字串異常的處理了,核心程式碼簡單點
String name = split[0];
String province = split[1];
String type = split[2];
int money = Integer.parseInt(split[3]);
SpendBean groupUser = new SpendBean();
groupUser.setUserName(new Text(name));
groupUser.setMoney(new IntWritable(money));
groupUser.setProvince(new Text(province));
context.write(new Text(name),groupUser);
}
}
/**
* reducer
*/
public static class GroupUserReducer extends Reducer<Text,SpendBean,Text,SpendBean> {
/**
* 姓名
* @param key
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<SpendBean> values, Context context) throws IOException, InterruptedException {
int money = 0;//消費金額
//遍歷
Text province = null;
for(SpendBean bean : values){
money += bean.getMoney().get();
province = bean.getProvince();
}
//輸出彙總結果
context.write(key,new SpendBean(key,new IntWritable(money),province));
}
}
/**
* 封裝的bean
*/
public static class SpendBean implements Writable{
private Text userName;
private IntWritable money;
private Text province;
public SpendBean(Text userName, IntWritable money, Text province) {
this.userName = userName;
this.money = money;
this.province = province;
}
/**
* 反序列化時必須有一個空參的構造方法
*/
public SpendBean(){}
/**
* 序列化的程式碼
* @param out
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
userName.write(out);
money.write(out);
province.write(out);
}
/**
* 反序列化的程式碼
* @param in
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException {
userName = new Text();
userName.readFields(in);
money = new IntWritable();
money.readFields(in);
province = new Text();
province.readFields(in);
}
public Text getUserName() {
return userName;
}
public Text getProvince() {
return province;
}
public void setProvince(Text province) {
this.province = province;
}
public void setUserName(Text userName) {
this.userName = userName;
}
public IntWritable getMoney() {
return money;
}
public void setMoney(IntWritable money) {
this.money = money;
}
@Override
public String toString() {
return "SpendBean{" +
"userName=" + userName +
", money=" + money +
", province=" + province +
'}';
}
}
/**
* 編寫啟動類
* @param args
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(GroupUser.class); //設定jar中的啟動類,可以根據這個類找到相應的jar包
job.setMapperClass(GroupUserMapper.class); //設定mapper的類
job.setReducerClass(GroupUserReducer.class); //設定reducer的類
job.setPartitionerClass(ProvincePartitioner.class);//指定資料分割槽規則,不是必須要的,根據業務需求分割槽
job.setNumReduceTasks(7); //設定相應的reducer數量,這個數量要與分割槽的大最數量一致
job.setMapOutputKeyClass(Text.class); //mapper輸出的key
job.setMapOutputValueClass(SpendBean.class); //mapper輸出的value
job.setOutputKeyClass(Text.class); //最終輸出的資料型別
job.setOutputValueClass(SpendBean.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));//輸入的檔案位置
FileOutputFormat.setOutputPath(job,new Path(args[1]));//輸出的檔案位置
boolean b = job.waitForCompletion(true);//等待完成,true,列印進度條及內容
if(b){
//success
}
}
}
4.4:在hadoop執行分割槽程式碼
我們重新打包專案後,重新上傳到伺服器中,直接執行命令執行
hadoop jar hadoop-mapreduce-1.0.jar com.zxj.hadoop.demo.mapreduce.staffspend.groupuser.GroupUser /staffspend/input /staffspend/output2
結果會發現reducer的過程,明顯慢了下來,因為是在reducer中分割槽,所以自然會慢了一些。
執行完成後,我們檢視輸出列表
hadoop fs -ls /staffspend/output2
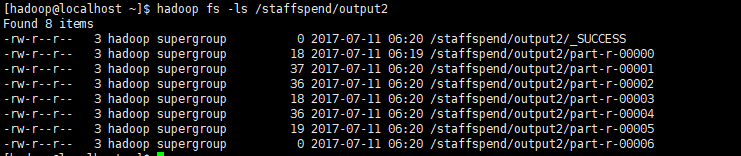
可以看到,這裡有7個檔案,對應著7個分割槽,執行命令檢視內容
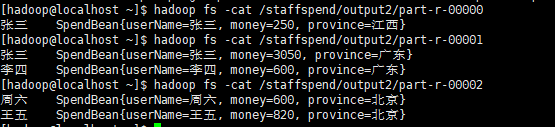
可以看到,這其中的資料,就是在一個省份中,每個人分別花了多少錢
五:資料排序及物件的重用
這一部分會講到資料的排序,這種需求也是會經常會有的,比如上面的例子中,我就想知道公司哪個員工的經費是最多的。
其次就是物件的重用,既然是大資料,那麼map的次數遠遠不止上億這麼簡單,我們每次都要重複建立一個bean嗎?
先準備一些資料,我們也可以用之前計算出來的資料,但是由於之前列印的格式不好,是toString()的預設格式,所以我這裡再準備一份資料
張三 2980
李四 8965
王五 1987
小黑 6530
小陳 2963
小梅 980
我們開始編碼
5.1:編寫排序程式碼
首先再準備一份bean,這個bean和以前不一樣,需要實現排序介面
/**
* 我們需要實現一個新的介面,這個介面包含了排序介面以及序列化介面
*/
public static class Spend implements WritableComparable<Spend>{
private Text name; //姓名
private IntWritable money; //花費
public Spend(){}
public Spend(Text name, IntWritable money) {
this.name = name;
this.money = money;
}
public void set(Text name, IntWritable money) {
this.name = name;
this.money = money;
}
@Override
public int compareTo(Spend o) {
return o.getMoney().get() - this.money.get();
}
@Override
public void write(DataOutput out) throws IOException {
name.write(out);
money.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
name = new Text();
name.readFields(in);
money = new IntWritable();
money.readFields(in);
}
public Text getName() {
return name;
}
public void setName(Text name) {
this.name = name;
}
public IntWritable getMoney() {
return money;
}
public void setMoney(IntWritable money) {
this.money = money;
}
@Override
public String toString() {
return name.toString() + "\t" + money.get();
}
}
其實這個排序介面就是jdk自帶的一個排序介面,使用方法與jdk的一致,所以就不講的太深入,主要就是靠這個介面來進行排序。
5.2:編寫mapper(物件的複用)
這部分的mapper很簡單,沒有什麼特殊要講的內容
public static class SortMapper extends Mapper<LongWritable,Text,Spend,Text>{
private Spend spend = new Spend();
private IntWritable moneyWritable = new IntWritable();
private Text text = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");//這裡就不做異常處理了,只寫核心邏輯
String name = split[0];
int money = Integer.parseInt(split[1]);
text.set(name);
moneyWritable.set(money);
spend.set(text, moneyWritable);
context.write(spend,text);
}
}
程式碼邏輯上並沒有什麼可說的,因為資料已經是彙總的資料了,只是進行一個排序而已,而排序的程式碼又寫在bean中實現的介面上了,這裡主要就是討論一下物件的複用。
因為大資料動則數十億上百億的資料,如果重複建立這麼多物件,那麼將增加GC的工作,我們可以複用它,就是把它定義在上方,在呼叫它的set方法,可以更新這個物件的值。
可能有人會覺得,在第二次操作這個物件的時候,那不是會改變這個物件的值嗎?沒錯的,是會改變。那麼第一次操作這方法時建立的物件,保留的引用不是也會更新值嗎?答案是不會的,生成的bean一經寫出,就會序列化出去,這個時候已經是一個序列化的資料了,序列化的資料在reducer中將會反序列化,這個時候,和這個物件已經沒有關係了。
5.3:編寫reducer
reducer平淡出奇,實在是沒有什麼可說的,直接輸出結果就行
public static class SortReducer extends Reducer<Spend,Text,Text,Spend>{
/**
* 因為在這之前已經是彙總的結果了,所以這裡直接輸出就行了
* @param key
* @param values 這裡面只有一個,就是姓名
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Spend key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
context.write(values.iterator().next(),key);
}
}
5.4:編寫啟動類
啟動類與也是一樣的,只不過不需要加上分割槽的程式碼
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration config = new Configuration();
Job job = Job.getInstance(config);
job.setJarByClass(SortGroupUser.class);
job.setMapperClass(SortMapper.class);
job.setReducerClass(SortReducer.class);
job.setMapOutputKeyClass(Spend.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Spend.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean b = job.waitForCompletion(true);
if(b){
//success
}
}這裡的程式碼就沒有註釋了,想看註釋的可以看上面部分的程式碼
5.5:完整的程式碼
為了防止強迫證的同學,貼出完整的程式碼
package com.zxj.hadoop.demo.mapreduce.staffspend.groupuser;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @Author 朱小杰
* 時間 2017-07-29 .15:48
* 說明 帶有排序功能的統計,
*/
public class SortGroupUser {
public static class SortMapper extends Mapper<LongWritable,Text,Spend,Text>{
private Spend spend = new Spend();
private IntWritable moneyWritable = new IntWritable();
private Text text = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");//這裡就不做異常處理了,只寫核心邏輯
String name = split[0];
int money = Integer.parseInt(split[1]);
text.set(name);
moneyWritable.set(money);
spend.set(text, moneyWritable);
context.write(spend,text);
}
}
public static class SortReducer extends Reducer<Spend,Text,Text,Spend>{
/**
* 因為在這之前已經是彙總的結果了,所以這裡直接輸出就行了
* @param key
* @param values 這裡面只有一個,就是姓名
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Spend key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
context.write(values.iterator().next(),key);
}
}
/**
* 我們需要實現一個新的介面,這個介面包含了排序介面以及序列化介面
*/
public static class Spend implements WritableComparable<Spend>{
private Text name; //姓名
private IntWritable money; //花費
public Spend(){}
public Spend(Text name, IntWritable money) {
this.name = name;
this.money = money;
}
public void set(Text name, IntWritable money) {
this.name = name;
this.money = money;
}
@Override
public int compareTo(Spend o) {
return o.getMoney().get() - this.money.get();
}
@Override
public void write(DataOutput out) throws IOException {
name.write(out);
money.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
name = new Text();
name.readFields(in);
money = new IntWritable();
money.readFields(in);
}
public Text getName() {
return name;
}
public void setName(Text name) {
this.name = name;
}
public IntWritable getMoney() {
return money;
}
public void setMoney(IntWritable money) {
this.money = money;
}
@Override
public String toString() {
return name.toString() + "\t" + money.get();
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration config = new Configuration();
Job job = Job.getInstance(config);
job.setJarByClass(SortGroupUser.class);
job.setMapperClass(SortMapper.class);
job.setReducerClass(SortReducer.class);
job.setMapOutputKeyClass(Spend.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Spend.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean b = job.waitForCompletion(true);
if(b){
//success
}
}
}mapper與reducer都寫在這裡面了。
5.6:在hadoop中執行排序
我們把新準備的資料命令為all.txt,然後上傳到伺服器,再上傳到hadoop的hdfs中
建立目錄
hadoop fs -mkdir -p /staffsort/input
上傳檔案 hadoop fs -put all.txt /staffsort/input
執行運算
hadoop jar hadoop-mapreduce-1.0.jar com.zxj.hadoop.demo.mapreduce.staffspend.groupuser.SortGroupUser /staffsort/input /staffsort/output
檢視輸出
hadoop fs -ls /staffsort/output hadoop fs -cat /staffsort/output/part-r-00000

OK完成
六:統計一本小說中出現的詞彙(包含Combiner)
本部分涵蓋了Combiner的知識點,以及在應用場景上是計算了鬥破蒼穹中哪些詞彙出現的次數最多,達到這樣一個效果,需要進行兩次mapreducer,第一次是彙總,第二次是排序
6.1:準備工作
1:鬥破蒼穹.txt(自行下載)
2:中文分詞器 ansj(也可以用別的)
<dependency> <groupId>org.ansj</groupId> <artifactId>ansj_seg</artifactId> <version>5.1.1</version> </dependency>
6.2:配置maven打包包含分詞的依賴
我們的程式碼是要打成jar包到hadoop中執行的,之前的程式碼中,我們並沒有依賴其它的東西,這次我們要依賴分詞器,因為hadoop中是不帶有這個東西的,所以我們打包的時候,也要把這個分詞器打包進來,所以我們使用maven-assembly-plugin外掛。這個外掛可能很多人都用過,可是你們覺得僅僅是配置打包其它的依賴這麼簡單嗎?no!no!no!我們要打出來的包,只包含分詞器呀,因為在pom檔案中,還包含了hadoop的jar包,我們不需要hadoop的jar包也打進來,因為在hadoop執行環境中,這些程式碼是在hadoop中存在的,而且加上hadooop的jar後,打出來的包會變的特別大。
我們現在要做的是打現來的包,只包含我們自己的程式碼加上分詞器的jar。
我們看一下怎麼做,如果朋友們有更好的方案,請在評論中指點,不勝感激
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4.1</version>
<executions>
<execution>
<id>make-jar</id>
<!-- 繫結到package生命週期階段上 -->
<phase>package</phase>
<goals>
<!-- 只執行一次 -->
<goal>single</goal>
</goals>
<configuration>
<descriptors> <!--描述檔案路徑-->
<descriptor>src/main/assemble/package.xml</descriptor>
</descriptors>
</configuration>
</execution>
</executions>
</plugin> 上面是pom檔案中的配置,但是上面依賴了一個其它的配置檔案,我們把它建在了相應的目錄,具體內容如下
<assembly xmlns="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.2"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.2 http://maven.apache.org/xsd/assembly-2.0.0.xsd">
<!-- 生成的檔案中,會帶有這一部分 -->
<id>a</id>
<!-- 根目錄中是否包含專案目錄,不需要 -->
<includeBaseDirectory>false</includeBaseDirectory>
<formats>
<format>jar</format>
</formats>
<fileSets>
<!-- 打包本工程的程式碼,如果沒有這部分,那麼打出來的包不包含本專案的程式碼 -->
<fileSet>
<!-- ${project.build.directory}是打包後的target目錄 -->
<directory>${project.build.directory}/classes</directory>
<outputDirectory></outputDirectory>
</fileSet>
</fileSets>
<dependencySets>
<dependencySet>
<useProjectArtifact>true</useProjectArtifact>
<useProjectAttachments>true</useProjectAttachments>
<!-- 輸出的位置,這是在根目錄中 -->
<outputDirectory></outputDirectory>
<!-- 把程式碼解壓出來,否則會是一個jar包的形式在裡面 -->
<unpack>true</unpack>
<includes>
<!-- 可以設定只加入這個maven的依賴 -->
<include>org.ansj:ansj_seg</include>
<include>org.nlpcn:nlp-lang</include>
<include>org.nutz:nutz</include>
</includes>
</dependencySet>
</dependencySets>
</assembly>如上就配置完了
6.3:資料彙總(Combiner)
第一步,我們要對資料進行彙總,不然怎麼排序呢?彙總的程式碼與之前wordcount差不多,但是資料量就多了,畢竟那不是我隨意編寫的測試資料,而是一本小說,所以這裡我們用到Combiner。
簡要的說一個Combiner的作用,Combiner就是在map的階段,先進行一步彙總,減少reducer的彙總的資料量。這個馬上會講到。
現在先來準備一個Mapper,因為輸出的就是詞彙和數量,所以也不需要自定義bean
package com.zxj.hadoop.demo.mapreduce.story;
import org.ansj.domain.Result;
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.Iterator;
import java.util.List;
/**
* @Author 朱小杰
* 時間 2017-07-29 .19:00
* 說明 統計一本小說哪些詞出現的次數最多
*/
public class StoryMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private Text text = new Text();
private LongWritable longWritable = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString().trim();
//剔除空的一行
if(!StringUtils.isBlank(line)){
//分詞的程式碼
Result parse = ToAnalysis.parse(line);
List<Term> terms = parse.getTerms();
Iterator<Term> iterator = terms.iterator();
while (iterator.hasNext()){
Term term = iterator.next();
longWritable.set(1);
text.set(term.getName());
context.write(text,longWritable);
}
}
}
}程式碼和以前不同的是,這裡面加入了分詞的程式碼,將每一個詞,當作一個key輸出。
reducer的程式碼
package com.zxj.hadoop.demo.mapreduce.story;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
/**
* @Author 朱小杰
* 時間 2017-07-29 .19:10
* 說明 統計小說
*/
public class StoryReducer extends Reducer<Text, LongWritable, LongWritable, Text> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
Iterator<LongWritable> iterator = values.iterator();
long num = 0;
while (iterator.hasNext()){
LongWritable longWritable = iterator.next();
num += longWritable.get();
}
context.write(new LongWritable(num),key);
}
}reducer的程式碼就是簡單的彙總,然後將資料輸出到文字中。
此時有必要說一個Combiner,我們先看一個怎麼設定一個Combiner
Job job = .. job.setCombinerClass(SortCombiner.class);//設定Combiner
再看一下Combiner中的需要傳一個什麼東西
/**
* Set the combiner class for the job.
* @param cls the combiner to use
* @throws IllegalStateException if the job is submitted
*/
public void setCombinerClass(Class<? extends Reducer> cls
) throws IllegalStateException {
ensureState(JobState.DEFINE);
conf.setClass(COMBINE_CLASS_ATTR, cls, Reducer.class);
}是不是很奇怪,這裡竟然是接收一個reducer。那我們能不能直接設定為reducer的類呢?答案是不行的,因為階段不一樣,Combiner是在執行完map後,自行彙總了一次,而Combiner彙總完之後,會再傳到reducer進行大彙總。從流程上面來說,是這樣子的,我草草畫了一個圖,可以看一下
這個是原來沒有Combiner的圖
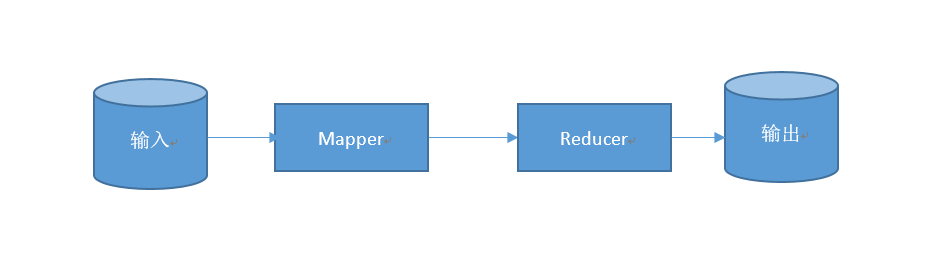
這是加有Combiner的圖

從流程上面看到Mapper後,如果有Combiner,會進行Combiner,再進行Reducer,也就意味著,Mapper的輸出,成為了Combiner的輸出,且Combiner的輸出,成為了Reducer的輸入。
但是Combiner需要遵循一個規則。Combiner需要作為一個可插拔的外掛,可有可無,就算移除Combiner,也不會對結果造成任何影響。
為什麼要使用Combiner呢?就是在各個map中預先進行一次,然後減少在reducer階段的資料量,這樣能提升很高的效率。
貼出Combiner的程式碼
package com.zxj.hadoop.demo.mapreduce.story;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
/**
* @Author 朱小杰
* 時間 2017-07-29 .20:03
* 說明 ...
*/
public class SortCombiner extends Reducer<Text, LongWritable, Text, LongWritable> {
private LongWritable longWritable = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
Iterator<LongWritable> iterator = values.iterator();
long num = 0;
while (iterator.hasNext()){
LongWritable longWritable = iterator.next();
num += longWritable.get();
}
longWritable.set(num);
context.write(key,longWritable);
}
}
可以看到,這裡的邏輯與reducer中差不多,其實就是在map階段進行了一步彙總而已,值得關注的是,輸出與輸入是一樣的,因為Combiner彙總後還是要交給reducer進行大彙總的。
最後看main方法,main方法也差不多,就是加上了設定Combiner的程式碼而已
package com.zxj.hadoop.demo.mapreduce.story;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @Author 朱小杰
* 時間 2017-07-29 .19:14
* 說明 ...
*/
public class StoryDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(StoryDriver.class);
job.setMapperClass(StoryMapper.class);
job.setReducerClass(StoryReducer.class);
job.setCombinerClass(SortCombiner.class);//設定Combiner
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean b = job.waitForCompletion(true);
if(b){
}
}
}把小說命名為dpcq.txt,上傳到hadoop中,記得檔案編碼哦,最好是utf-8編碼
hadoop fs -mkdir -p /story/input hadoop fs -put dpcq.txt /story/input
然後打包後,把包含分詞器的jar上傳到伺服器並且在hadoop中執行
hadoop jar hadoop-mapreduce-1.0-a.jar com.zxj.hadoop.demo.mapreduce.story.StoryDriver /story/input /story/output
執行結果如下

但是這並不是我們想要的結果,我們需要它對詞彙出現的數量進行排序,所以我們還要進行一個排序的mapreducer
6.4:排序階段
通過上面的彙總,我們已經得到了每個詞分別出現了多少次,這一部分我們要對其進行排序,這一部分極其簡單,我們之前也看過排序是怎麼做的,實現一個Comparable介面而已,但是實際上我們這裡並不需要實現,因為我們是根據詞彙出現的次數來排序,我們來看一個LongWritable的原始碼

可以想象,LongWritable已經實現了排序介面,不需要我們去處理,不過LongWritable實現的是一個正序的排序,我們要拉到最底下才能看到哪個詞彙出現了最多,如果我們要看倒序排的話,我們就要自己實現咯,如下就讓long型別的資料是倒序排的
package com.zxj.hadoop.demo.mapreduce.story.sort;
import org.apache.hadoop.io.LongWritable;
/**
* @Author 朱小杰
* 時間 2017-07-29 .21:00
* 說明 一個倒序的Long
*/
public class MyLongWritable extends LongWritable {
@Override
public int compareTo(LongWritable o) {
if(o.get() > this.get()){
return 1;
}else if (o.get() == this.get()){
return 0;
}else{
return -1;
}
}
}這裡直接繼承了LongWritable,重寫了它的排序程式碼,不過留一個懸念,為什麼實現的程式碼不直接使用
return (int)(o.get() - this.get())這不是會簡單好多嗎?為什麼不使用呢?大家可以在評論裡面回答哈!
好,我們已經定義了一個倒序的MyLongWribable,排序的時候,我們就用它好了
其它的程式碼就特別簡單了,看mapper如下
package com.zxj.hadoop.demo.mapreduce.story.sort;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @Author 朱小杰
* 時間 2017-07-29 .20:43
* 說明 ...
*/
public class SortMapper extends Mapper<LongWritable, Text, MyLongWritable, Text> {
private Text text = new Text();
private MyLongWritable longWritable = new MyLongWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String content = value.toString().trim();
if(!StringUtils.isBlank(content)){
String[] split = content.split("\t");
if(split.length == 2){
long number = Long.parseLong(split[0]);//出現的次數
String word = split[1]; //詞彙
longWritable.set(number);
text.set(word);
context.write(longWritable,text);
}
}
}
}如果你看明白了上面的一些說明,那麼對於這裡的