
Spark中sortByKey和sortBy對(key,value)資料分別 根據key和value排序
阿新 • • 發佈:2019-01-02
最近在用Spark分析Nginx日誌,日誌解析和處理完後需要根據URL的訪問次數等進行排序,取得Top(10)等。
根據對Spark的學習,知道Spark中有一個sortByKey()的函式能夠完成對(key,value)格式的資料進行排序,但是,很明顯,它是根據key進行排序,而日誌分析完了之後,一般都是(URL,Count)的格式,而我需要根據Count次數進行排序,然後取得前10個。
SortByKey()函式
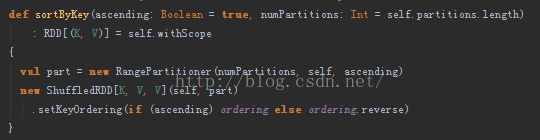
上面是SortByKey函式的原始碼實現。顯然,該函式會對原始RDD中的資料進行Shuffle操作,從而實現排序。
下面通過Spark-shell進行相關的測試:
val d1 = sc.parallelize(Array(("cc",12),("bb",32),("cc",22),("aa",18),("bb",16),("dd",16),("ee",54),("cc",1),("ff",13),("gg",68),("bb",4)))
d1.reduceByKey(_+_).sortBy(_._2,false).collect
測到的測試結果如上圖所示,顯然是根據Key進行了排序。但是,我的需求是對Value進行排序,折騰了很久都不能達到要求。最後在QQ群裡得到了大神的幫助——使用sortBy()函式。
sortBy()函式
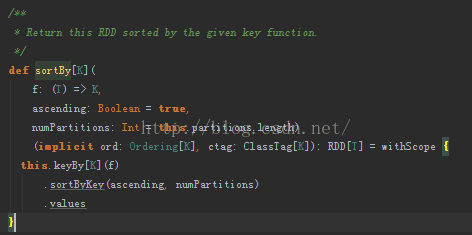
上圖是sortBy()函式的原始碼,其本質也是用到了sortByKey()函式,然後通過spark-shell進行測試:
val d2 = sc.parallelize(Array(("cc",32),("bb",32),("cc",22),("aa",18),("bb",6),("dd",16),("ee",104),("cc",1),("ff",13),("gg",68),("bb",44)))
d2.sortByKey(false).collect
顯然,上圖顯示的結果是根據Value中的資料進行的排序。
至此,對(Key,Value)資料型別的資料可以根據需求分別對Key和Value進行排序了。
大神還是挺多的,多跟別人交流(尤其是比自己牛逼的人),能受益匪淺,也能節省很多時間!