
非線性激勵函式sigmoid,tanh,softplus,Relu
阿新 • • 發佈:2019-01-02
目前有四種常見的非線性激勵函式:
sigmoid函式:
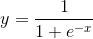
tanh函式:

softplus函式:
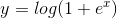
Relu函式:
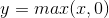
其對應得函式影象如下:
| 函式種類 | 優點 | 缺點 |
| sigmoid函式 | 在整個定義域內可導 | gradient在飽和區域非常平緩,接近於0,很容易造成vanishing gradient的問題,減緩收斂速度。 算啟用函式時(指數運算),計算量大,反向傳播求誤差梯度時,求導涉及除法,計算量相對大 |
| tanh函式 | 在整個定義域內可導 | gradient在飽和區域非常平緩,接近於0,很容易造成vanishing gradient的問題,減緩收斂速度。 算啟用函式時(指數運算),計算量大,反向傳播求誤差梯度時,求導涉及除法,計算量相對大 |
| softplus函式 | 在整個定義域內可導 | 算啟用函式時(指數運算),計算量大,反向傳播求誤差梯度時,求導涉及除法,計算量相對大 |
| ReLu函式 | Relu的gradient大多數情況下是常數,有助於解決深層網路的收斂問題。 ReLU更容易學習優化。因為其分段線性性質,導致其前傳,後傳,求導都是分段線性 Relu會使一部分神經元的輸出為0,這樣就造成了網路的稀疏性,並且減少了引數的相互依存關係,緩解了過擬合問題的發生,也更接近真實的神經元啟用模型。 | 如果後層的某一個梯度特別大,導致W更新以後變得特別大,導致該層的輸入<0,輸出為0,這時該層就會‘die’,沒有更新。當學習率比較大時可能會有40%的神經元都會在訓練開始就‘die’,因此需要對學習率進行一個好的設定。 |
還有一個東西要注意,sigmoid 和 tanh作為啟用函式的話,一定要注意一定要對 input 進行歸一話,否則啟用後的值都會進入平坦區,使隱層的輸出全部趨同,但是 ReLU 並不需要輸入歸一化來防止它們達到飽和。
還有兩種改進的激勵函式:
Leaky ReLu函式:
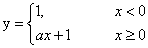
Maxout函式:
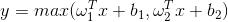
但是這兩種並不常用