
人工神經網路中的activation function的作用以及ReLu,tanh,sigmoid激勵函式的區別
Leaky ReLU函式

人們為了解決Dead ReLU Problem,提出了將ReLU的前半段設為而非0。另外一種直觀的想法是基於引數的方法,即Parametric ReLU:,其中可由back propagation學出來。理論上來講,Leaky ReLU有ReLU的所有優點,外加不會有Dead ReLU問題,但是在實際操作當中,並沒有完全證明Leaky ReLU總是好於ReLU。
ELU (Exponential Linear Units) 函式
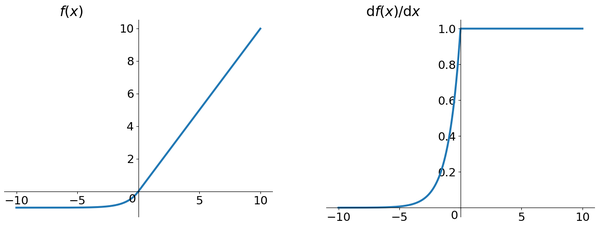
ELU也是為解決ReLU存在的問題而提出,顯然,ELU有ReLU的基本所有優點,以及:
- 不會有Deal ReLU問題
- 輸出的均值接近0,zero-centered
它的一個小問題在於計算量稍大。類似於Leaky ReLU,理論上雖然好於ReLU,但在實際使用中目前並沒有好的證據ELU總是優於ReLU。
相關推薦
人工神經網路中的activation function的作用以及ReLu,tanh,sigmoid激勵函式的區別
Leaky ReLU函式 人們為了解決Dead ReLU Problem,提出了將ReLU的前半段設為而非0。另外一種直觀的想法是基於引數的方法,即Parametric ReLU:,其中可由back propagation學出來。理論上來講,Leaky ReLU有ReLU的所有優點,外加不會有Dead Re
神經網路中反向傳播演算法(backpropagation)的pytorch實現,pytorch教程中的程式碼解讀以及其他一些疑問與解答
pytorch的官網上有一段教程,是使用python的numpy工具實現一個簡單的神經網路的bp演算法。下面先貼上自己的程式碼: import numpy as np N,D_in,H,D_out = 4,10,8,5 x = np.random.randn(N,D_i
神經網路中embedding層作用——本質就是word2vec,資料降維,同時可以很方便計算同義詞(各個word之間的距離),底層實現是2-gram(詞頻)+神經網路
Embedding tflearn.layers.embedding_ops.embedding (incoming, input_dim, output_dim, validate_indices=False, weights_init='truncated_norm
矩陣標準差在神經網路中的反向傳播以及數值微分梯度驗證
最近開腦洞想訓練一個關於球面擬合的模型於是用到了標準差作為輸出層的損失函式,所以就對於標準差方程進行反向傳播推導了一下。 現在分享一下推導過程和結果和用數值微分方法對於結果正確性的驗證,順便記錄一下以免忘記了。 這是標準差方程 標準差主要是用來描述資料離散程度,其實就是方差的開平方
人工神經網路——反向傳播演算法(BP)以及Python實現
人工神經網路是模擬生物神經系統的。神經元之間是通過軸突、樹突互相連線的,神經元收到刺激時,神經脈衝在神經元之間傳播,同時反覆的脈衝刺激,使得神經元之間的聯絡加強。受此啟發,人工神經網路中神經元之間的聯絡(權值)也是通過反覆的資料資訊"刺激"而得到調整的。而反向傳
[深度學習] 神經網路中的啟用函式(Activation function)
20180930 在研究調整FCN模型的時候,對啟用函式做更深入地選擇,記錄學習內容 啟用函式(Activation Function),就是在人工神經網路的神經元上執行的函式,負責將神經元的輸入對映到輸出端。 線性啟用函式:最簡單的linear fun
為什麼神經網路中需要啟用函式(activation function)?
在看tensorflow的時候,發現書中程式碼提到,使用ReLU啟用函式完成去線性化為什麼需要啟用函式去線性化?查了一下quaro,覺得這個回答能看明白(順便問一句,截圖算不算引用??)---------------------------------------------
神經網路中的啟用函式(activation function)-Sigmoid, ReLu, TanHyperbolic(tanh), softmax, softplus
不管是傳統的神經網路模型還是時下熱門的深度學習,我們都可以在其中看到啟用函式的影子。所謂啟用函式,就是在神經網路的神經元上執行的函式,負責將神經元的輸入對映到輸出端。常見的啟用函式包括Sigmoid、TanHyperbolic(tanh)、ReLu、 sof
神經網路中的activation function到底扮演什麼樣的角色
參考Quora 為python作者Sebastian Raschka的回答 要回答這個問題,首先從線性迴歸(Linear Regression)說起,然後過度到邏輯迴歸(Logistic Regression),最後,過度到神經網路(Neural Netwo
R語言——實驗4-人工神經網路(更新中)
帶包實現: rm(list=ls()) setwd("C:/Users/Administrator/Desktop/R語言與資料探勘作業/實驗4-人工神經網路") Data=read.csv("sales_data.csv")[,2:5] library(nnet) colnames(
嵌入式中的人工神經網路
人工神經網路在AI中具有舉足輕重的地位,除了找到最好的神經網路模型和訓練資料集之外,人工神經網路的另一個挑戰是如何在嵌入式裝置上實現它,同時優化效能和功率效率。 使用雲端計算並不總是一個選項,尤其是當裝置沒有連線的時候。 在這種情況下,需要一個能夠實時進行訊號預處理和執行神經網路的平臺,需要最低
卷積神經網路中1x1卷積的作用
1. 來源 [1312.4400] Network In Network (如果1×1卷積核接在普通的卷積層後面,配合啟用函式,即可實現network in network的結構) 2. 應用 GoogleNet中的Inception、ResNet中的殘差模組
理解交叉熵作為損失函式在神經網路中的作用
交叉熵的作用 通過神經網路解決多分類問題時,最常用的一種方式就是在最後一層設定n個輸出節點,無論在淺層神經網路還是在CNN中都是如此,比如,在AlexNet中最後的輸出層有1000個節點: 而即便是ResNet取消了全連線層,也會在最後有一個1000個節
關於神經網路中梯度消失以及梯度爆炸
一 梯度消失產生的根源 神經網路中訓練模型包括前向傳播和反向傳播兩個過程,反向傳播通過損失函式計算的誤差通過梯度反向傳播的形式對引數進行更新。深度神經網路包括很多隱藏層,每一層都是非線性對映。那麼整個神經網路就是個非線性多遠函式複合計算最終結果。那麼對求損失函式最小值,就可
CNN相關要點介紹(一)——卷積核操作、feature map的含義以及資料是如何被輸入到神經網路中
一、卷積核的定義 下圖顯示了CNN中最重要的部分,這部分稱之為卷積核(kernel)或過濾器(filter)或核心(kernel)。因為TensorFlow官方文件中將這個結構稱之為過濾器(filter),故在本文中將統稱這個結構為過濾器。如下圖1所示,
理解交叉熵(cross_entropy)作為損失函式在神經網路中的作用
交叉熵的作用通過神經網路解決多分類問題時,最常用的一種方式就是在最後一層設定n個輸出節點,無論在淺層神經網路還是在CNN中都是如此,比如,在AlexNet中最後的輸出層有1000個節點: 而即便是ResNet取消了全連線層,也會在最後有一個1000個節點的輸出層: 一般情況下
人工神經網路及其在醫學影像分析中的應用
摘要:人工神經網路(ANN)是在結構上模仿生物神經聯結型系統,能夠設計來進行模式分析,訊號處理等工作。為了使醫學生和醫務工作者能對神經網路,特別是人工神經網路及其在醫學影象和訊號檢測與分析中的應用有個全面瞭解,本文避免了繁瑣的數學分析與推導,以闡明物理概念為主,深入淺出地就
深度學習——神經網路中的activation
A:如果不用啟用函式(其實相當於啟用函式是f(x) = x),在這種情況下你每一層輸出都是上層輸入的線性函式,很容易驗證,無論你神經網路有多少層,輸出都是輸入的線性組合,與沒有隱藏層效果相當,這種情況就是最原始的感知機(Perceptron)了。引入非線性函式作為啟用函式,這樣深層神經網路就有意義了(不再是輸
人工神經網路演算法的學習率有什麼作用
神經網路的結構(例如2輸入3隱節點1輸出)建好後,一般就要求神經網路裡的權值和閾值。現在一般求解權值和閾值,都是採用梯度下降之類的搜尋演算法(梯度下降法、牛頓法、列文伯格-馬跨特法、狗腿法等等),這些演算法會先初始化一個解,在這個解的基礎上,確定一個搜尋方向和一個移動步長(
神經網路中引數權重w,偏置b的作用(為何需要偏置b的解釋)
可檢視講解神經元w,b引數的作用 在我們接觸神經網路過程中,很容易看到就是這樣一個式子,g(wx+b),其中w,x均為向量.比如下圖所示: 加入啟用函式為g(x),我們就可以用公式g(w1x1+w2x2+b)(注:1,2均為下標,公眾號很難打,下面所有的公式均是)來表示神經元的輸出。