
【faster-rcnn】訓練自己的資料集時的坑
既然faster-rcnn原版發表時候是matlab版程式碼,那就用matlab版程式碼吧!不過遇到的坑挺多的,不知道python版會不會好一點。
======= update =========
總體上包括這些步驟,請注意檢查:
1 獲取資料;(標準資料集/比賽資料/自行收集資料)
2 整理圖片名和標註資訊格式、指定訓練集和測試集;(轉voc格式,同時記得修改vocinit.m中類別資訊;或者自己修改程式碼中讀取資料的地方)
3 正確使用均值影象:手動算一個或用預設的減去128,別用錯
4 選擇網路與設定網路引數(solver和net);(根據業務需求和視訊記憶體大小設定;修改網路中目標類別數量)
5 檢查batch_size;
6 檢查anchor;
7 清空cache目錄;
8 開始訓練;
9 確保電腦供電且不會休眠睡眠;
10 執行測試;整理測試結果
======= update =========
anyway,這裡記錄一下我遇到的幾個坑
這裡假設你已經配置好了faster-rcnn。我是在win10下配置的,顯示卡GTX 970,使用ZF網路。
0. 準備資料集
官方訓練時用的是voc2007系列資料,那就轉換成這個系列的好了,主要包括:0.下載資料集 1.整理圖片 2.xml格式的annotation檔案 3.txt格式指定訓練集、測試集、驗證集、訓練驗證集,以及每個類別各自的這四種檔案
0.0 下載資料集
看具體情況,比如做某個比賽,那就下載;如果是自己收集的資料集,那就統一放到一起
0.1 整理圖片
主要是圖片格式統一,比如都是png
以及,命名規範,比如統一是6位長度的數字:000001.png,並且序號是連續的
訓練圖片和測試圖片都放在一個JPEGImages
0.2 xml格式的annotation檔案
其實voc2007這種方式:為每張圖片編寫一個xml檔案,記錄圖片各種元資訊(作者、檔名、寬度高度深度、來源),以及bounding box座標資訊(左上、右下定點)等,很蛋疼啊,圖片多的話每次處理xml檔案讀寫I/O就增大了。anyway,遵守標準的好處是省的自己造各種工具。
這裡貼一個例子好了,000001.xml:
<annotation>
<folder>VOC2007</folder>
<filename>000001.png</filename>
<source>
<database 記得所有xml檔案的檔名要和圖片序號一一對應:000001.xml對應000001.png
並且,所有xml檔案放到Annotations目錄中
0.3 txt檔案指定訓練集、測試集等
在ImageSets/Main目錄下儲存這些檔案。比如我的任務是檢測交通標識,只有一個類別需要檢測,或者說是二分類問題,只需要判斷一個bbox區域是否為交通標識(sign),那麼我建立sign對應的4個檔案;以及4個表示總體的訓練、驗證、訓練驗證、測試的txt檔案: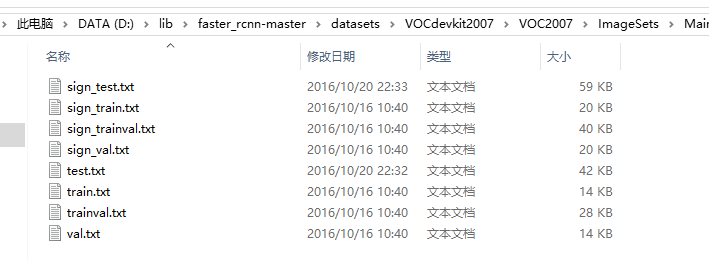
其中,sign_train、sign_test、sign_trainval、sign_val每行格式相同
圖片id(不帶字尾,不用全路徑) +1或-1(表示這張圖片中是否包含sign類別的區域)對於我的情況,類別標籤都是+1
然後是train、val、trainval、test檔案,其中trainval是train和val的拼接。
這裡我是需要
1 修改faster-rcnn的幾個程式碼細節
1.0 experiments\script_faster_rcnn_VOC2007_ZF.m第30、31行
這裡預設居然是用select search生成region proposal,我也是醉了。
改成:
dataset = Dataset.voc2007_trainval(dataset, 'train', use_flipped);
dataset = Dataset.voc2007_test(dataset, 'test', false);1.1 experiments\+Dataset\voc2007_test.m第11行、第14行,test改成val
這個真的是太坑了,在這裡我卡了大半天。為什麼會卡在這個地方,然後程式一直執行出錯呢?以及,程式出錯大概如下:
錯誤使用 proposal_prepare_image_roidb>scale_rois (line 110) 兩個輸入陣列的單一維度必須相互匹配,...
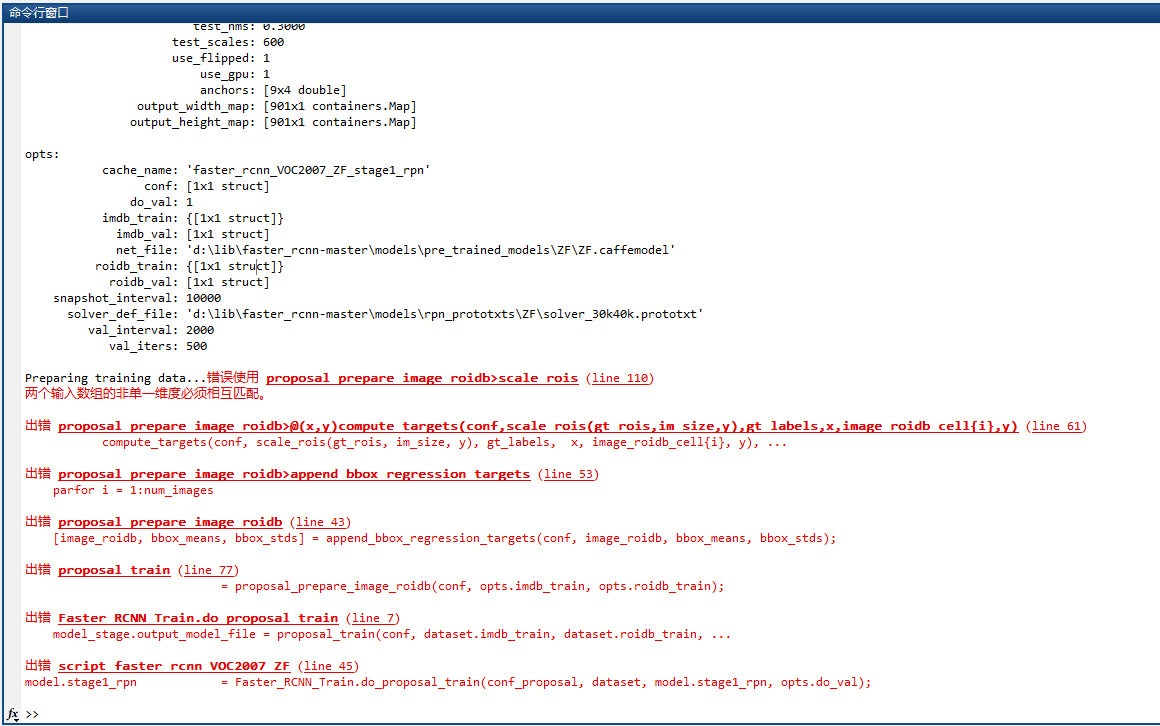
設斷點debug後發現,roidb_train裡各種欄位都有值(比如gt、座標、閾值、類別等);而roidb_val裡面是空的。
實際上是在experiments\+Faster_RCNN_Train\do_proposal_train.m裡面,把dataset.roidb_test賦值給roidb_val了:
function model_stage = do_proposal_train(conf, dataset, model_stage, do_val)
if ~do_val
dataset.imdb_test = struct();
dataset.roidb_test = struct();
end
model_stage.output_model_file = proposal_train(conf, dataset.imdb_train, dataset.roidb_train, ...
'do_val', do_val, ...
'imdb_val', dataset.imdb_test, ...
'roidb_val', dataset.roidb_test, ... # 尼瑪,在這裡賦值了
'solver_def_file', model_stage.solver_def_file, ...
'net_file', model_stage.init_net_file, ...
'cache_name', model_stage.cache_name);
end
問題就是在這裡了,不多說。那麼接下來就是把experiments\+Dataset\voc2007_test.m第11行、第14行,test改成val,保證以後在imdb\cache目錄下有val的mat資料存在,roidb_val也不會說裡面內容都為空的了。
2 修改網路引數
看到下面這張圖應該知道要改那幾個檔案了: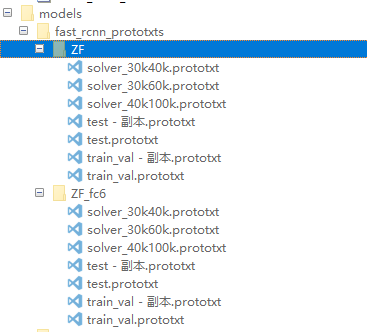
具體可以參考小鹹魚的faster-rcnn matlab版的配置