
【Faster RCNN】《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》

NIPS-2015
NIPS,全稱神經資訊處理系統大會(Conference and Workshop on Neural Information Processing Systems),是一個關於機器學習和計算神經科學的國際會議。該會議固定在每年的12月舉行,由NIPS基金會主辦。NIPS是機器學習領域的頂級會議 。在中國計算機學會的國際學術會議排名中,NIPS為人工智慧領域的A類會議。
目錄
1 Motivation
State-of-the-art object detection networks depend on region proposal algorithms to hypothesize object locations. Advances like SPPnet and Fast R-CNN have reduced the running time of these detection networks, exposing region proposal computation as a bottleneck
作者提出 Region Proposal Network (RPN) that shares full-image convolutional features with the detection network, thus enabling nearly cost-free region proposals(10ms per image).
2 Innovation
RPN,end to end
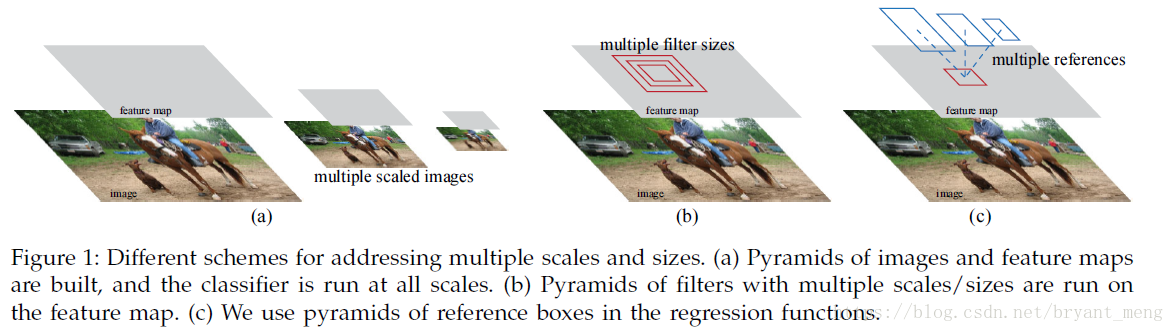
不是用 image pyramid 圖1(a),也不是用 filter pyramid,圖1(b),而是用 anchor,圖一(c),可以叫做,pyramid of regression references
3 Advantages
- 5fps (including all steps) on a GPU——VGG
- state-of-the-art object detection accuracy on PASCAL VOC 2007, 2012, and MS COCO datasets with only 300 proposals per image
- ILSVRC and COCO 2015 competitions,the foundations of the 1st-place winning entries(eg:ResNet)
4 Methods
SS慢,EdgeBoxes 雖然能達到 0.2 second per image(和檢測的時間差不多了),一個很直接的想法就是在 GPU上實現這些演算法,但是 re-implementation ignores the down-stream detection network and therefore misses important opportunities for sharing computation.
相關工作先介紹了 object proposal的情況,然後是 Deep Net works for object detection(主要是 RCNN, fast RCNN 和 OverFeat),個人感覺對RCNN 和 OverFeat 的總結很精闢
R-CNN mainly plays as a classifier, and it does not predict object bounds (except for refining by bounding box regression).
In the OverFeat method, a fully-connected layer is trained to predict the box coordinates for the localization task that assumes a single object.
4.1 RPN
Note: RPN is class-agnostic 【R-FCN】《R-FCN: Object Detection via Region-based Fully Convolutional Networks》
4.1.1 Anchors
共享卷積的最後一層,ZF有 5 layers(256 dimension),VGG 有13 layers(512 dimension),
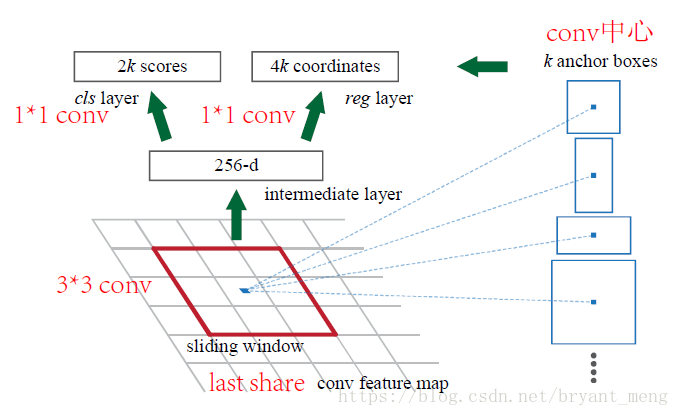
2k中 2 是 object or not object,k是每個3*3的 sliding window 中 anchor數量, 4k 中的 4 是 bbox
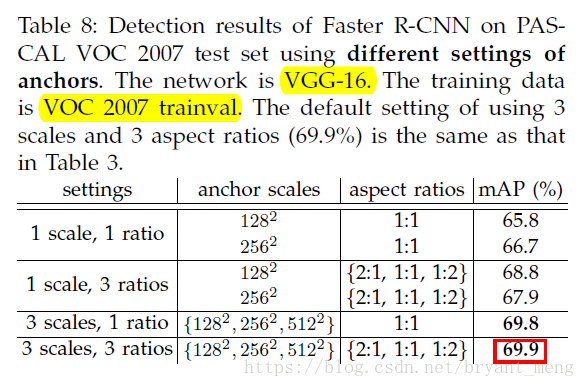
ratios 和 scales 的威力如下:
- Translation-Invariant anchors
相比與 MultiBox的方法,Faster RCNN的 anchor 基於卷積,有 translation-invariant 的性質,而且 引數量更少,(4+2)* k * dimension(eg,k=9,VGG dimension為512) parameters 為 ,更少的引數量的好處是,less risk of overfitting on small datasets,like PASCAL VOC
- Multi-Scale Anchors as Regression References
區別於 image pyramid 和 filter pyramid,作者用 anchor pyramid(不同的 scales 和 ratios),more cost-efficient,因為 only relies on images and feature maps of a single scales and uses filters(sliding windows on feature map)of a single size.
4.1.2 Loss Function
每個anchor進行2分類,object or not,positive 為 IoU>0.5或者max IoU,negative 為 IoU<0.3,其它的anchor對訓練來說沒有用
損失函式如下
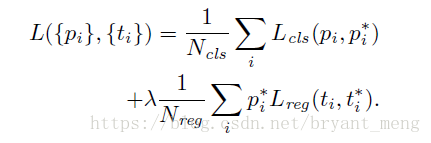
- :minibatch 中 anchor
- :predicted probability of anchor being an object.
- :is 1 if the anchor is positive, 0 if the anchor is negative
- :4 parameterized coordinates of the predicted bounding box
- :ground-truth box associated with a positive anchor
- :log loss
- :Smooth L1 loss,前面乘以了 表示 regression loss is activated only for positive anchors
Normalized by 和 (normalization is not required and could be simplified), 用來 balance parameters
- 設定為 mini-batch的大小,eg:256
- 設定為 numbers of anchor locations(~2400)
- 設定為 10,正好兩種損失55開
的影響如下,Insensitive

具體的
和
如下:
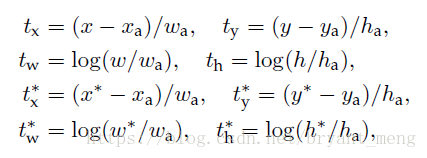
x,y 是 predict box 的中心,w 和 h 分別是 寬和高
分別表示 predict-box,anchor box 和 ground-truth box,y,h,w 的表示方法也一樣
This can be thought of as bounding-box regression from an anchor box to a nearby ground-truth box.說白了,就是計算 (predict box 與 anchor 的 偏差) 和 (ground-truth 與 anchor的偏差)的損失
Note:這裡的 bbox regression 不同於 Fast RCNN 和 SPPnet的,
Fast RCNN 和 SPPnet 的bbox regression: is performed on features pooled from arbitrarily sized RoIs, and the regression weights are shared by all region sizes.
Faster RCNN 此處的 bbox regression 是爭對 per scales 和 per ratios的,To account for varying sizes, a set of k bounding-box regressors are learned. Each regressor is responsible for one scale and one aspect ratio, and the k regressors do not share weights.
4.1.3 Training RPNs
randomly sampls 256 anchors,這樣會出現以下問題:but this will bias towards negative samples as they are dominate,所以我們按照1:1 的抽正負anchors,如果positive anchors不夠128,pad negative anchors
We randomly initialize all new layers by drawing weights from a zero-mean Gaussian distribution with standard deviation 0.01.
4.2 Sharing Features for RPN and Fast R-CNN
Both RPN and Fast R-CNN, trained independently, will modify their convolutional layers in different ways. We therefore need to develop a technique that allows for sharing convolutional layers between the two networks, rather than learning two separate networks.
三種訓練方法
- Alternating training(論文中採用的方法)
- Approximate joint training(效果會比交替訓練好一些)
- Non-approximate joint training
作者用的是 交替訓練,4-step Alternating Training
- RPN(ImageNet 初始化,RPN and Fast RCNN not share prameters)
- Fast RCNN(ImageNet 初始化,用RPN產生的proposal——替換掉SS產生的,訓練Fast RNN,not share)
- 用上一步的訓練好的引數,fine tuning RPN(share)
- 用重新訓練的RPN提出的proposal, fine tuning the unique layers of Fast RCNN 也就是 head 部分(share)
為什麼不一二三四,二二三四,換個姿勢,再來一次?
A similar alternating training can be run for more iterations, but we have observed negligible improvements.
4.3 Implementation Detais
- Train and test 都是 single scales,reshape shorter side s = 600 pixels
- Image pyramid : trade off accuracy and speed(沒采用)
- Anchors:scales, 、 、 ,ratios: , , ,見表一,表中紅色的字型是預設的 anchors(2:1),表中列出來的是 bbox regression 之後的結果

- 訓練的時候,剔除 cross image boundaries (跨圖邊界)的anchors,測試的時候,clip(裁剪) to the image
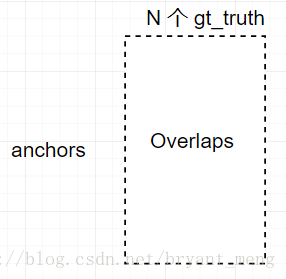
- RPN proposal 有很多overlap,我們用了非極大值抑制(NMS),iou設定為0.7,NMS does not harm the ultimate detection accuracy,但是減少了 proposal 的數量。論文中 用 top-2000的proposal 進行 train。為什麼NMS overlap thresold 設定為0.7呢?
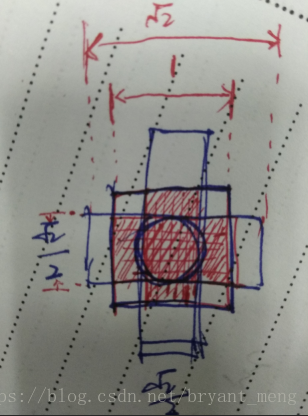
看上面這個圖,就是 , , 三種情況,假如 ground truth 和 1:1一樣大,那麼與 , 的 IOU都為 ,這樣的話會導致同一目標產生兩種特徵圖,不利於網路的學習,所以把 IOU設定為0.7,儘量緩解這種情況(只是一種解釋喲)
5 Experiments
5.1 Ablation Experiments
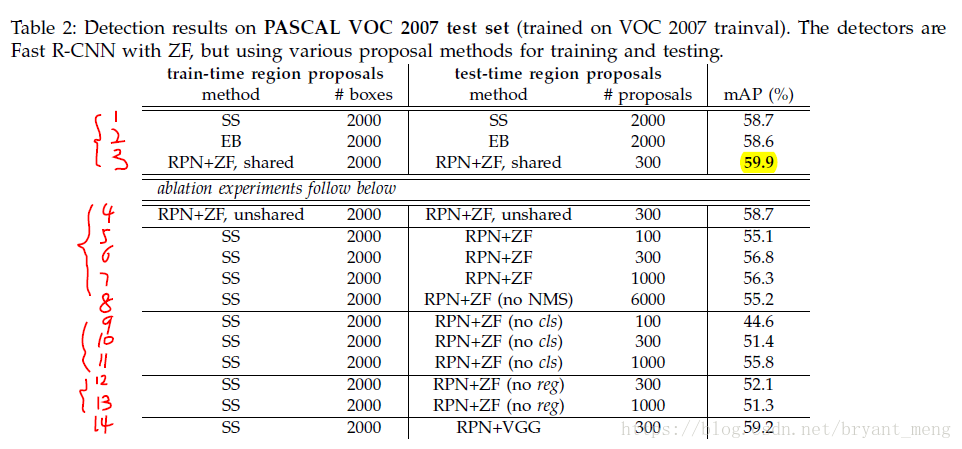
- 1,2,3對比,3 更好,the fewer proposals also reduce the region-wise fully-connected layers’ cost(table 5可以看到)
- 3,4 對比,share 好
- 3,6 對比,RPN+fast RCNN 比 SS+ Fast RCNN 好,train test 的 proposal 不一樣
- 4,8 對比, NMS 影響不大
- 7,11差距不算大,9,11差距明顯,cls 排序很重要
- 6,12對比,reg 很重要
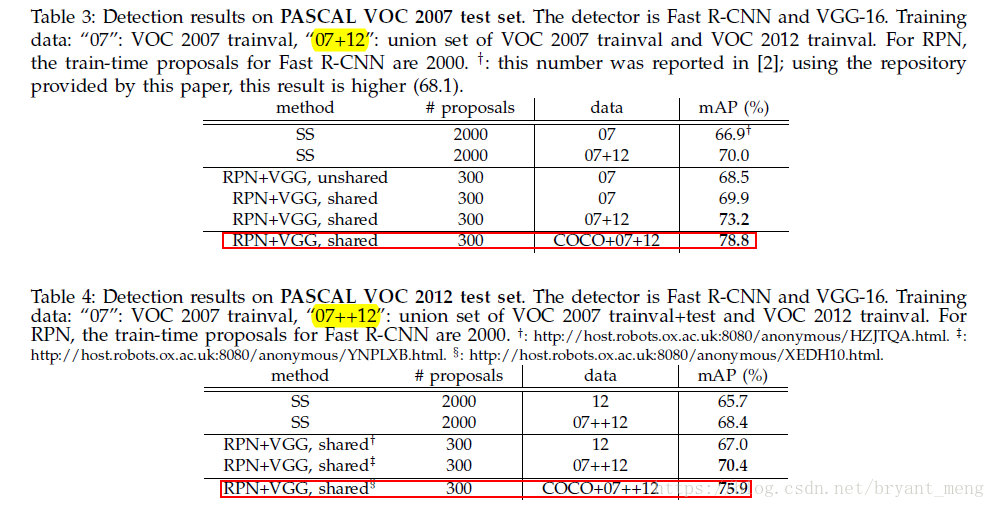
5.2 VOC 07/12 實驗結果
5.3 速度(ms)

5.4 recall-to-IoU
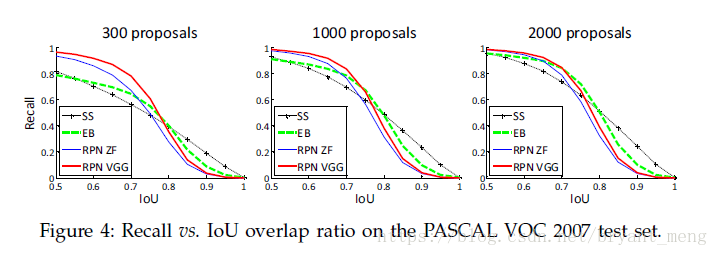
RPN 的 proposal 從 2000 drops 到 300 效果差不多
5.5 PK (one-stage overfeat)

5.6 COCO 上的結果

VGG 換成 ResNet, ensemble一下, COCO 2015 object detection 冠軍
結構圖

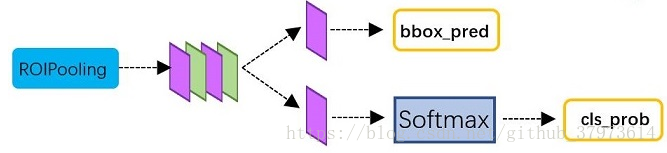
Note: reshape 是為了softmax操作,softmax操作中,第一維必須是類別數,類別如果是2,object or not,則是 class-agnostic ,如果類別是,比如 VOC 資料集,20+1類, 則是 class-specific

相關推薦
【Faster RCNN】《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》
NIPS-2015 NIPS,全稱神經資訊處理系統大會(Conference and Workshop on Neural Information Processing Systems),是一個關於機器學習和計算神經科學的國際會議。該會議固定在每年的12月舉行
【論文筆記】Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
寫在前面: 我看的paper大多為Computer Vision、Deep Learning相關的paper,現在基本也處於入門階段,一些理解可能不太正確。說到底,小女子才疏學淺,如果有錯
【筆記】Faster-R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
論文程式碼:重要:訓練檔案.prototxt說明:http://blog.csdn.net/Seven_year_Promise/article/details/60954553從RCNN到fast R
【翻譯】Faster-R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
摘要 目前最先進的目標檢測網路需要先用區域建議演算法推測目標位置,像SPPnet[7]和Fast R-CNN[5]這些網路已經減少了檢測網路的執行時間,這時計算區域建議就成了瓶頸問題。本文中,我們介紹一種區域建議網路(Region Proposal Network, R
論文閱讀筆記(六)Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
采樣 分享 最終 產生 pre 運算 減少 att 我們 作者:Shaoqing Ren, Kaiming He, Ross Girshick, and Jian SunSPPnet、Fast R-CNN等目標檢測算法已經大幅降低了目標檢測網絡的運行時間。可是盡管如此,仍然
論文閱讀筆記二十六:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(CVPR 2016)
論文源址:https://arxiv.org/abs/1506.01497 tensorflow程式碼:https://github.com/endernewton/tf-faster-rcnn 摘要 目標檢測依賴於區域proposals演算法對目標的位置進
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Abstract SPPnet和Fast R-CNN雖然減少了演算法執行時間,但region proposal仍然是限制演算法速度的瓶頸。而Faster R-CNN提出了Region Proposal Network (RPN),該網路基於卷積特徵預測每個位置是否為物體以及
[論文學習]《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 》
faster R-CNN的主要貢獻 提出了 region proposal network(RPN),通過該網路我們可以將提取region proposal的過程也納入到深度學習的過程之中。這樣做既增加了Accuracy,由降低了耗時。之所以說增加Accura
深度學習論文翻譯解析(十三):Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
論文標題:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 標題翻譯:基於區域提議(Region Proposal)網路的實時目標檢測 論文作者:Shaoqing Ren, K
Faster RCNN: Towards RealTime Object Detection with Region Proposal Networks+Visualizing and Underst
Faster RCNN是對之前的 RCNN、SPPNet、Fast RCNN 等目標檢測框架的進一步優化,將 Region Proposal 過程融合進入 CNN 模型,稱之為 RPN(Region Proposal Network),大幅降低了 test-time 計算量,
【目標檢測】Cascade R-CNN 論文解析
都是 org 檢測 rpn 很多 .org 實驗 bubuko pro 目錄 0. 論文鏈接 1. 概述 @ 0. 論文鏈接 Cascade R-CNN 1. 概述 ??這是CVPR 2018的一篇文章,這篇文章也為我之前讀R-CNN系列困擾的一個問題提供了一個解決方案
【論文解析】Cascade R-CNN: Delving into High Quality Object Detection
論文連結 CVPR2018的文章。和BPN一樣,本文主要關注的是目標檢測中IoU的閾值選取問題,但是BPN主要針對的是SSD等single-stage的detector,感興趣的童鞋可以看我的另一篇博文BPN 目標檢測中,detector經常是用低IoU閾值來train的,如果提高IoU閾值
【論文翻譯】Fast R-CNN
Fast R-CNN Ross Girshick Microsoft Research [email protected] 摘要 本文提出了一種快速的基於區域的卷積網路方法(fast R-CNN)用於目標檢測。Fast R-CNN建立在以
【論文翻譯】Mask R-CNN
Mask R-CNN Kaiming He Georgia Gkioxari Piotr Dolla ́r Facebook AI Research (FAIR) Ross Girshick 摘要 我們提出了一個概念上簡單,靈活和通用的目標分割框架。我們
【神經網路與深度學習】【計算機視覺】Fast R-CNN
先回歸一下: R-CNN ,SPP-net R-CNN和SPP-net在訓練時pipeline是隔離的:提取proposal,CNN提取特徵,SVM分類,bbox regression。 Fast R-CNN 兩大主要貢獻點 : 1 實現大部分end-to-end訓練(提proposal階段除外):
【目標檢測】【語義分割】—Mask-R-CNN詳解
一、mask rcnn簡介 論文連結:論文連結 論文程式碼:Facebook程式碼連結;Tensorflow版本程式碼連結; Keras and TensorFlow版本程式碼連結;MxNet版本程式碼連結 mask rcnn是基於faster rcnn架構提出的卷積網
【論文閱讀】Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
簡述 看這篇論文,並實現一下這個。(如果有能力實現的話) 實時任意風格轉換(用自適應Instance Normalization) instanceNorm = batchsize=1 的 batchNorm 1 Abstract Gatys et al
【學習筆記】pyQt5學習筆記(6)——Google object detection API訓練&識別用軟體更新
對訓練軟體和識別軟體均再一次進行更新。 針對訓練用軟體,V1.0版本是通過下拉框選擇標註物體的標籤,而下拉框中是我預定義的a~f 6個標籤。因此存在的問題就是標籤不能客製化,且若標記超過6類物體標籤數量不夠。 針對這個問題進行了更新,現在允許使用者自己輸入標籤名稱,標籤會儲存在下拉選單中,媽媽再
【學習筆記】pyQt5學習筆記(5)——Google object detection API訓練用軟體
之前的學習筆記是呼叫訓練好的結果來做識別,分為載入本地圖片識別和呼叫usb攝像頭實時識別(IP攝像頭暫時不可用);但是首先有了訓練才能有訓練好的模型檔案供我們使用。加之訓練過程比較複雜,呼叫多個指令碼,上手不便;製作訓練用的軟體一方面是方便自己使用,另一方面也對自己是個鍛鍊。軟體最終的介面如下圖所示
【目標檢測】[論文閱讀][yolo] You Only Look Once: Unified, Real-Time Object Detection
論文名稱《You Only Look Once: Unified, Real-Time Object Detection》 摘要 1、之前的目標檢測方法採用目標分類思想解決檢測問題,本文提出一個基於迴歸的框架,用於目標的定位及識別。 2、一個網路,一次預