
資訊索引導論學習筆記(1)——布林檢索
阿新 • • 發佈:2019-01-03
資訊檢索
資訊檢索(Information Retrieval,簡稱IR):從大規模非結構化資料(通常是文字)的集合(通常儲存在計算機上)中找出滿足使用者資訊需求的資料(通常是文件)的過程 資訊檢索按照規模分類:- 以web搜尋為代表的大規模級別
- 小規模級別,典型示例為個人資訊檢索
- 中等規模級別,面向企業、機構和特定領域的搜尋
倒排索引
順序掃描:這種線性掃描就是一種最簡單的計算機文件檢索方式。這個過程通常稱為grepping,它來自於Unix下的一個文字掃描命令grep。 順序掃描無法滿足的幾種情況:- 大規模文件集條件下的快速查詢。
- 更靈活的匹配方式。比如grep命令下不能支援諸如Romans NEAR countrymen之類的查詢
- 需要對結果進行排序

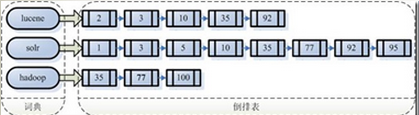
詞項-文件的關聯矩陣,其中每一行代表一個詞,每列表示一個劇本。當詞t在劇本d中存在時,矩陣元素(t, d)的值為1,否則為0 為想要查詢 Brutus AND Caesar AND NOT Calpurnia,我們分別取出 Brutus,Caesar及Calpurnia對應的行向量,並對Calpurnia對應的向量求反,然後進行基於位的與操作,得到: 110100 AND 110111 AND 101111 = 100100 詞項-文件(term-doc)的關聯矩陣具有高度稀疏性,僅僅儲存非零的位置明顯更好 倒排索引的構建
- 對每個詞項t,記錄所有包含t的文件,建立詞條序列<詞條,docID>二元組
- 對詞項、文件排序。按詞項排序,然後每個詞項按docID排序
- 合併詞項,並記錄詞項的文件頻率df(對每個詞項t,記錄所有包含t的文件數目)
布林查詢處理
and查詢處理 比如說,我們要尋找既包含字串“Brutus”又包含字串“Calpurnia”的文件,我們可以採用歸併的方法(類似於歸併排序中的merge操作),進行如下幾步:- 取出包含字串“Brutus”的倒排記錄表
- 取出包含字串“Calpurnia”的倒排記錄表
- 通過合併兩個倒排記錄表,找出既包含“Brutus”又包含“Calpurnia”的文件
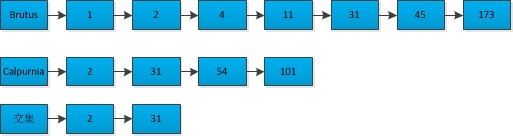
利用歸併的演算法,可以在O(n)的時間複雜度求出交集,書上用連結串列,我為了方便,直接用陣列了
#include <stdio.h> int main(void) { int arr1[7] = {1, 2, 4, 11, 31, 45, 173}; /*Brutus文件集合*/ int arr2[4] = {2, 31, 54, 101}; /*Calpurnia文件集合*/ int result[7] = {0}; /*交集集合*/ int i, j, k, len1, len2; /*變數初始化*/ len1 = sizeof(arr1) / sizeof(int); len2 = sizeof(arr2) / sizeof(int); /*歸併演算法*/ for (i = j = k = 0; i < len1 && j < len2;) { if (arr1[i] == arr2[j]) { result[k] = arr1[i]; i ++; j ++; k ++; } else if (arr1[i] < arr2[j]) { i ++; } else if(arr1[i] > arr2[j]) { j ++; } } /*列印輸出*/ for (i = 0; i < k; i ++) { printf("%d ", result[i]); } printf("\n"); return 0; }
通用的查詢優化策略(詞典中儲存文件頻率df的一個充分理由) (madding OR crowd) AND (ignoble OR strife) AND (killed OR slain)
- 每個布林表示式都能轉換成上述形式(合取正規化)
- 獲得每個詞項的df
- 通過將詞項的df相加,估計每個OR表示式對應的倒排記錄表的大小
- 按照上述估計從小到大依次處理每個OR表示式
- 雙重否定律
- 德×摩根定律:非(P 且 Q) = (非P) | (非Q) 非(P 或 Q) = (非 P) 且 (非 Q)
- 分配律