
[聊聊架構] 日請求量過億,談陌陌的 Feed 服務優化之路
阿新 • • 發佈:2019-01-03
場景和架構介紹
先從產品層⾯面介紹一下Feed業務。Feed本⾝身就是一段簡短文字加一張圖片,帶有位置資訊,釋出之後可以被好友和附近的人看到,通過點贊評論的方式互動。類似微博和朋友圈。
陌陌上季度的MAU為6980萬,Feed作為主要的社交業務,從2013年上線到現在,日請求量超過億,總資料量超過百億。下面是Feed系統的整體架構圖:
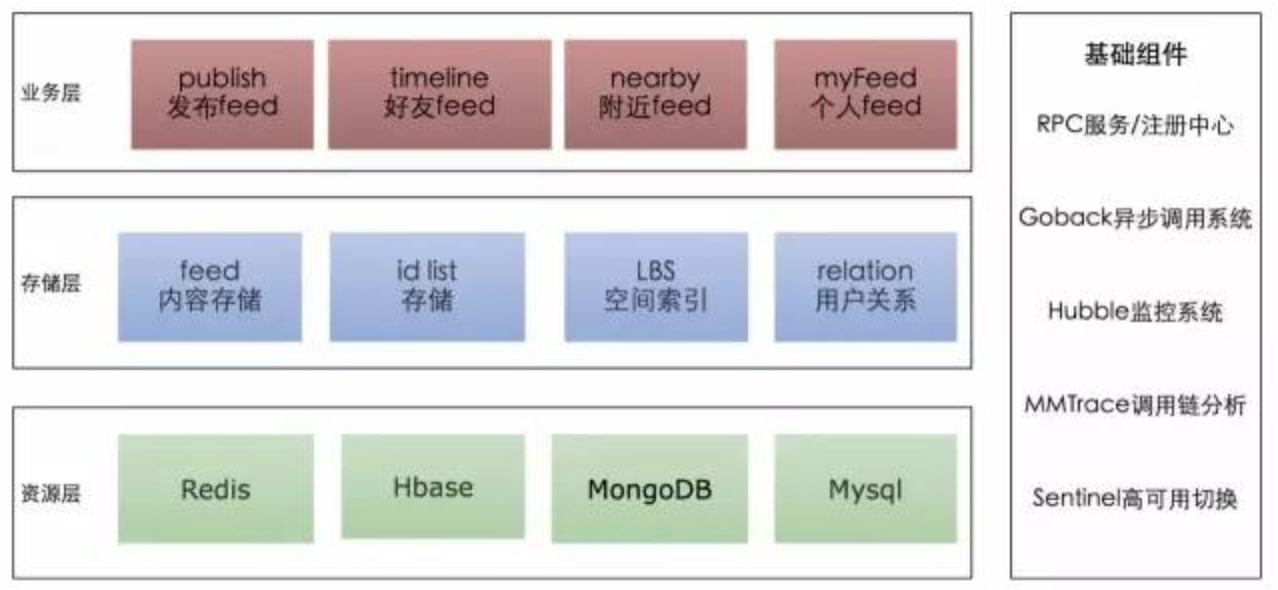
* 資源層主要使用Redis、MongoDB、HBase等NoSQL型別資料庫。 * 儲存層是內部RPC服務,根據業務場景和儲存特性,組合各種資料庫資源。 * 業務層呼叫儲存層讀寫資料,實現產品邏輯,直接面向用戶使用。 內容儲存(Feed Content) 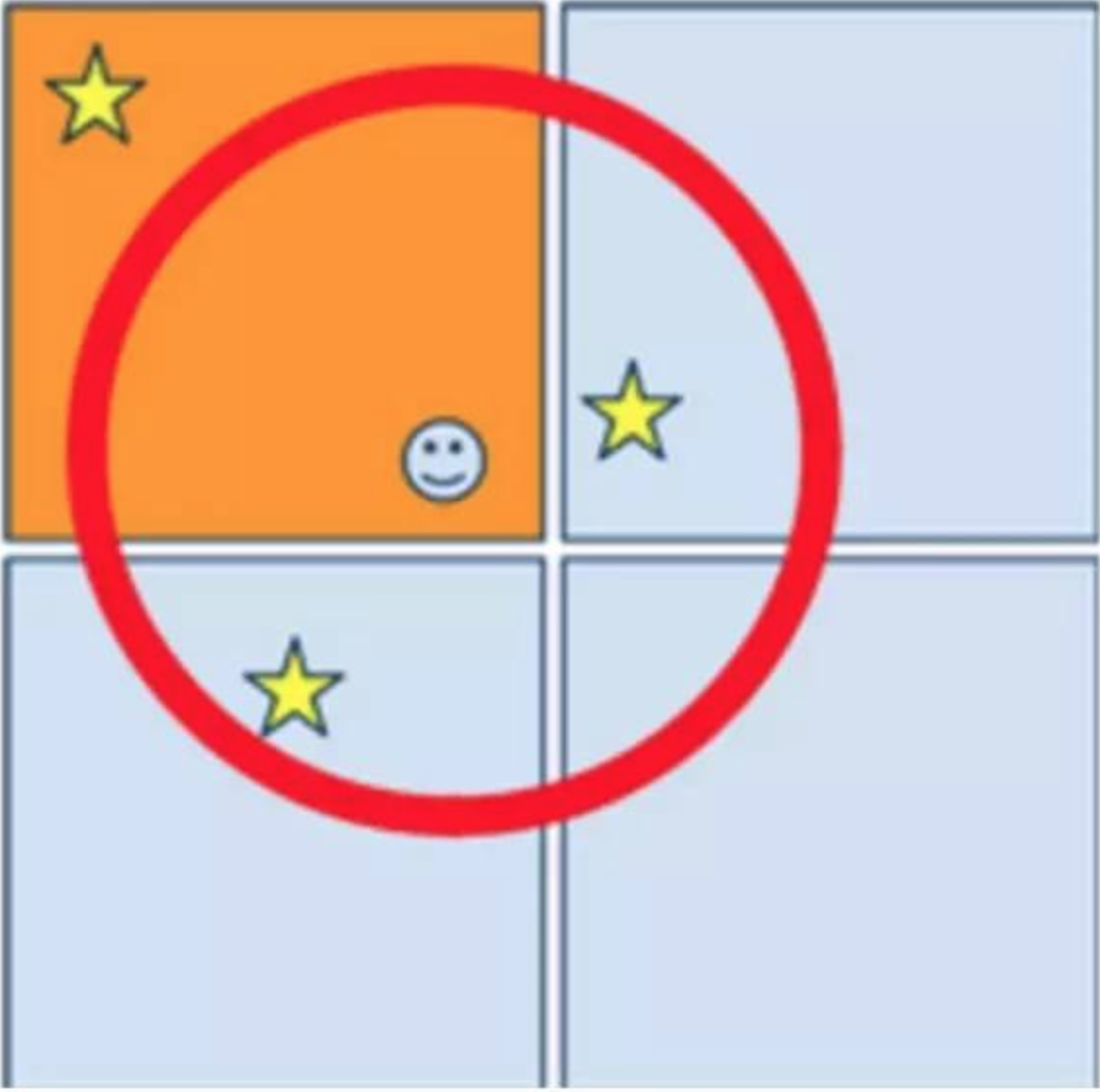
解決這個問題可以在查詢時擴大範圍,除了查詢使用者所在的矩形外,還擴散搜尋相鄰的8個矩形,將9個矩形合併(如下圖),按時間排序,過濾掉超出距離範圍的Feed,最後做分頁查詢。 歸納為四個步驟:ExtendSearch -> MergeAndSort -> DistanceFilter -> Skip。 但是這種方式查詢效率比較低,作為讀遠遠大於寫的場景,換了一種思路,在更新Feed空間索引時,將Feed寫入相鄰的8個矩形,這樣每個矩形還包含了相鄰矩形的Feed,查詢省去了ExtendSearch和MergeAndSort兩個步驟。通過資料冗餘的方式,換取了更高的查詢效率。 (通過GEOHash)將複雜的geo查詢,簡化為redis的zrange操作,效能提高了一個數量級,平均耗時降到3ms。空間索引通過geohash分片到redis節點,具有資料分佈均勻、方便擴容的優勢。 總結 陌陌的Feed服務大規模使用Redis作為快取和儲存,Redis的效能非常高,瞭解它的特性,並且正確使用可以解決很多大規模請求的效能問題。通常記憶體的故障率遠低於硬碟的故障率,生產環境Redis的穩定性是非常高的。通過合理的持久化策略和一主多從的部署結構,可以確保資料丟失的風險降到最低。 另外,陌陌的Feed服務構建在許多內部技術框架和基礎元件之上,本文偏重於業務方面,沒有深入展開,後續有機會可以再做介紹。 互動問答 問題:MongoDB採用什麼叢集方式部署的,如果資料量太大,採用什麼方式來提高查詢效能? 我們通過在mongo客戶端按id做hash的方式分片。當時MongoDB版本比較低,複製集(repl-set)還不太成熟,沒有在生產環境使用。除了建索引以外,還可以通過把mongo資料檔案掛載在記憶體盤(tmpfs)上提高查詢效能,不過有重啟丟資料的風險。 問題:使用者的關係是怎麼儲存的呢 還有就是獲取好友動態時每條feed的使用者資訊是動態從Redis或者其他地方讀取呢? 陌陌的使用者關係使用Redis儲存的。獲取好友動態是的使用者資訊是通過feed的ownerId,再去另外一個使用者資料服務(profile服務)讀取的,使用者資料服務是陌陌請求量最大的服務,QPS超過50W。 問題:具體實現用到Redis解決效能問題,那Redis的可用性是如何保證的?萬一某臺旦旦機資料怎麼保證不丟失的? Redis通過一主一從或者多從的方式部署,一臺機器宕機會切換到備用的例項。另外Redis的資料會定時持久化到rdb檔案,如果一主多從都掛了,可以恢復到上一次rdb的資料,會有少量資料丟失。 問題:Redis這麼高效能是否有在應用伺服器上做本地儲存,如果有是如何做Redis叢集與本地資料同步的? 沒有在本地部署Redis,應用伺服器部署的都是無狀態的RPC服務。 問題:Redis一個叢集大概有多少個點? 主從之間同步用的什麼機制? 直接mod問題多嗎? 一個Redis叢集幾個節點到上百個節點都有。大的叢集通過分號段再mod的方式hash。Redis 3.0的cluster模式還沒在生產環節使用。使用的Redis自帶的主從同步機制。 問題:文中提到Redis使用mod方式分片,新增機器時進行資料複製,複製的過程需要停機麼,如果不停資料在動態變化,如何處理? 主從同步的方式複製資料不需要停機,擴容的過程中一直保持資料同步,從庫和主庫資料一致,擴容完成之後從庫提升為主庫,關閉主從同步。 問題:Redis宕機後的主從切換是通過的哨兵機制嗎?在主從切換的時候,是有切換延時的,這段時間的寫入主的資料是否會丟失,如果沒丟,怎麼保證的? 通過內部開發的Sentinel系統,檢測Reids是否可用。為了防止誤切,切換會有一定延遲,多次檢測失敗才會切換。如果主庫不可用會有資料丟失,重要資料的寫入,在業務上有重試機制。 陌陌Feed讀後總結 Redis 採用Mod取餘Hash的方式. 通過節點資料複製,快速的翻倍擴容,省去了快取預熱的過程。 原文這部分沒有細說.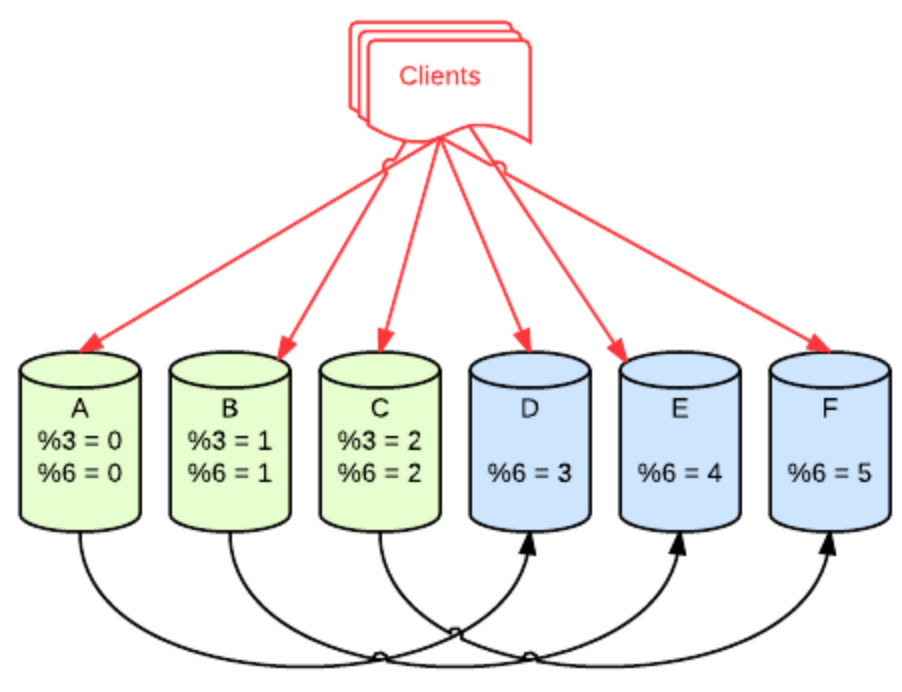
假如原來有三個redis例項, 並且各自帶了Slave. 通過 id mod 3 取餘,判斷存放位置. 擴容的時候,僅僅需要把Slave Readonly去掉, 前端通過 id mod 6 取餘, 判斷存放位置即可,同時斷掉Redis 主從複製. 這時候備機就成了寫入機。 同時,將這三個原來三個主機標號成為 4,5,6。 因為 id mod 6 == 0 的情況 必定 id mod 3 == 0。比如 10 mod 3 = 1 ,現在改為 10 mod 6 = 4 正好落在原來的備機上. 待完成之後,需要清理每個例項上一半冗餘的資料.不過一般設定了過期時間,可以等待他自然過期. 這樣的擴容方式,每次需要擴一倍。
* 資源層主要使用Redis、MongoDB、HBase等NoSQL型別資料庫。 * 儲存層是內部RPC服務,根據業務場景和儲存特性,組合各種資料庫資源。 * 業務層呼叫儲存層讀寫資料,實現產品邏輯,直接面向用戶使用。 內容儲存(Feed Content)
解決這個問題可以在查詢時擴大範圍,除了查詢使用者所在的矩形外,還擴散搜尋相鄰的8個矩形,將9個矩形合併(如下圖),按時間排序,過濾掉超出距離範圍的Feed,最後做分頁查詢。 歸納為四個步驟:ExtendSearch -> MergeAndSort -> DistanceFilter -> Skip。 但是這種方式查詢效率比較低,作為讀遠遠大於寫的場景,換了一種思路,在更新Feed空間索引時,將Feed寫入相鄰的8個矩形,這樣每個矩形還包含了相鄰矩形的Feed,查詢省去了ExtendSearch和MergeAndSort兩個步驟。通過資料冗餘的方式,換取了更高的查詢效率。 (通過GEOHash)將複雜的geo查詢,簡化為redis的zrange操作,效能提高了一個數量級,平均耗時降到3ms。空間索引通過geohash分片到redis節點,具有資料分佈均勻、方便擴容的優勢。 總結 陌陌的Feed服務大規模使用Redis作為快取和儲存,Redis的效能非常高,瞭解它的特性,並且正確使用可以解決很多大規模請求的效能問題。通常記憶體的故障率遠低於硬碟的故障率,生產環境Redis的穩定性是非常高的。通過合理的持久化策略和一主多從的部署結構,可以確保資料丟失的風險降到最低。 另外,陌陌的Feed服務構建在許多內部技術框架和基礎元件之上,本文偏重於業務方面,沒有深入展開,後續有機會可以再做介紹。 互動問答 問題:MongoDB採用什麼叢集方式部署的,如果資料量太大,採用什麼方式來提高查詢效能? 我們通過在mongo客戶端按id做hash的方式分片。當時MongoDB版本比較低,複製集(repl-set)還不太成熟,沒有在生產環境使用。除了建索引以外,還可以通過把mongo資料檔案掛載在記憶體盤(tmpfs)上提高查詢效能,不過有重啟丟資料的風險。 問題:使用者的關係是怎麼儲存的呢 還有就是獲取好友動態時每條feed的使用者資訊是動態從Redis或者其他地方讀取呢? 陌陌的使用者關係使用Redis儲存的。獲取好友動態是的使用者資訊是通過feed的ownerId,再去另外一個使用者資料服務(profile服務)讀取的,使用者資料服務是陌陌請求量最大的服務,QPS超過50W。 問題:具體實現用到Redis解決效能問題,那Redis的可用性是如何保證的?萬一某臺旦旦機資料怎麼保證不丟失的? Redis通過一主一從或者多從的方式部署,一臺機器宕機會切換到備用的例項。另外Redis的資料會定時持久化到rdb檔案,如果一主多從都掛了,可以恢復到上一次rdb的資料,會有少量資料丟失。 問題:Redis這麼高效能是否有在應用伺服器上做本地儲存,如果有是如何做Redis叢集與本地資料同步的? 沒有在本地部署Redis,應用伺服器部署的都是無狀態的RPC服務。 問題:Redis一個叢集大概有多少個點? 主從之間同步用的什麼機制? 直接mod問題多嗎? 一個Redis叢集幾個節點到上百個節點都有。大的叢集通過分號段再mod的方式hash。Redis 3.0的cluster模式還沒在生產環節使用。使用的Redis自帶的主從同步機制。 問題:文中提到Redis使用mod方式分片,新增機器時進行資料複製,複製的過程需要停機麼,如果不停資料在動態變化,如何處理? 主從同步的方式複製資料不需要停機,擴容的過程中一直保持資料同步,從庫和主庫資料一致,擴容完成之後從庫提升為主庫,關閉主從同步。 問題:Redis宕機後的主從切換是通過的哨兵機制嗎?在主從切換的時候,是有切換延時的,這段時間的寫入主的資料是否會丟失,如果沒丟,怎麼保證的? 通過內部開發的Sentinel系統,檢測Reids是否可用。為了防止誤切,切換會有一定延遲,多次檢測失敗才會切換。如果主庫不可用會有資料丟失,重要資料的寫入,在業務上有重試機制。 陌陌Feed讀後總結 Redis 採用Mod取餘Hash的方式. 通過節點資料複製,快速的翻倍擴容,省去了快取預熱的過程。 原文這部分沒有細說.
假如原來有三個redis例項, 並且各自帶了Slave. 通過 id mod 3 取餘,判斷存放位置. 擴容的時候,僅僅需要把Slave Readonly去掉, 前端通過 id mod 6 取餘, 判斷存放位置即可,同時斷掉Redis 主從複製. 這時候備機就成了寫入機。 同時,將這三個原來三個主機標號成為 4,5,6。 因為 id mod 6 == 0 的情況 必定 id mod 3 == 0。比如 10 mod 3 = 1 ,現在改為 10 mod 6 = 4 正好落在原來的備機上. 待完成之後,需要清理每個例項上一半冗餘的資料.不過一般設定了過期時間,可以等待他自然過期. 這樣的擴容方式,每次需要擴一倍。