
Kafka史上最詳細原理總結 ----看完絕對不後悔
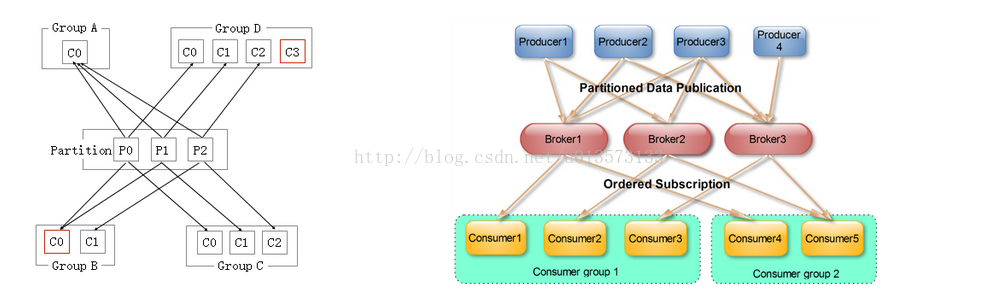 - Delivery Mode : Kafka producer 傳送message不用維護message的offsite資訊,因為這個時候,offsite就相當於一個自增id,producer就儘管傳送message就好了。而且Kafka與AMQ不同,AMQ大都用在處理業務邏輯上,而Kafka大都是日誌,所以Kafka的producer一般都是大批量的batch傳送message,向這個topic一次性發送一大批message,load balance到一個partition上,一起插進去,offsite作為自增id自己增加就好。但是Consumer端是需要維護這個partition當前消費到哪個message的offsite資訊的,這個offsite資訊,high level api是維護在Zookeeper上,low level api是自己的程式維護。(Kafka管理介面上只能顯示high level api的consumer部分,因為low level api的partition offsite資訊是程式自己維護,kafka是不知道的,無法在管理介面上展示 )當使用high level api的時候,先拿message處理,再定時自動commit offsite+1(也可以改成手動), 並且kakfa處理message是沒有鎖操作的。因此如果處理message失敗,此時還沒有commit offsite+1,當consumer thread重啟後會重複消費這個message。但是作為高吞吐量高併發的實時處理系統,at least once的情況下,至少一次會被處理到,是可以容忍的。如果無法容忍,就得使用low level api來自己程式維護這個offsite資訊,那麼想什麼時候commit offsite+1就自己搞定了。- Topic & Partition:Topic相當於傳統訊息系統MQ中的一個佇列queue,producer端傳送的message必須指定是傳送到哪個topic,但是不需要指定topic下的哪個partition,因為kafka會把收到的message進行load balance,均勻的分佈在這個topic下的不同的partition上( hash(message) % [broker數量] )。物理上儲存上,這個topic會分成一個或多個partition,每個partiton相當於是一個子queue。在物理結構上,每個partition對應一個物理的目錄(資料夾),資料夾命名是[topicname]_[partition]_[序號],一個topic可以有無數多的partition,根據業務需求和資料量來設定。在kafka配置檔案中可隨時更高num.partitions引數來配置更改topic的partition數量,在建立Topic時通過引數指定parittion數量。Topic建立之後通過Kafka提供的工具也可以修改partiton數量。 一般來說,(1)一個Topic的Partition數量大於等於Broker的數量,可以提高吞吐率。(2)同一個Partition的Replica儘量分散到不同的機器,高可用。 當add a new partition的時候,partition裡面的message不會重新進行分配,原來的partition裡面的message資料不會變,新加的這個partition剛開始是空的,隨後進入這個topic的message就會重新參與所有partition的load balance- Partition Replica:每個partition可以在其他的kafka broker節點上存副本,以便某個kafka broker節點宕機不會影響這個kafka叢集。存replica副本的方式是按照kafka broker的順序存。例如有5個kafka broker節點,某個topic有3個partition,每個partition存2個副本,那麼partition1存broker1,broker2,partition2存broker2,broker3。。。以此類推(replica副本數目不能大於kafka broker節點的數目,否則報錯。這裡的replica數其實就是partition的副本總數,其中包括一個leader,其他的就是copy副本)。這樣如果某個broker宕機,其實整個kafka內資料依然是完整的。但是,replica副本數越高,系統雖然越穩定,但是回來帶資源和效能上的下降;replica副本少的話,也會造成系統丟資料的風險。 (1)怎樣傳送訊息:producer先把message傳送到partition leader,再由leader傳送給其他partition follower。(如果讓producer傳送給每個replica那就太慢了) (2)在向Producer傳送ACK前需要保證有多少個Replica已經收到該訊息:根據ack配的個數而定 (3)怎樣處理某個Replica不工作的情況:如果這個部工作的partition replica不在ack列表中,就是producer在傳送訊息到partition leader上,partition leader向partition follower傳送message沒有響應而已,這個不會影響整個系統,也不會有什麼問題。如果這個不工作的partition replica在ack列表中的話,producer傳送的message的時候會等待這個不工作的partition replca寫message成功,但是會等到time out,然後返回失敗因為某個ack列表中的partition replica沒有響應,此時kafka會自動的把這個部工作的partition replica從ack列表中移除,以後的producer傳送message的時候就不會有這個ack列表下的這個部工作的partition replica了。 (4)怎樣處理Failed Replica恢復回來的情況:如果這個partition replica之前不在ack列表中,那麼啟動後重新受Zookeeper管理即可,之後producer傳送message的時候,partition leader會繼續傳送message到這個partition follower上。如果這個partition replica之前在ack列表中,此時重啟後,需要把這個partition replica再手動加到ack列表中。(ack列表是手動新增的,出現某個部工作的partition replica的時候自動從ack列表中移除的)- Partition leader與follower:partition也有leader和follower之分。leader是主partition,producer寫kafka的時候先寫partition leader,再由partition leader push給其他的partition follower。partition leader與follower的資訊受Zookeeper控制,一旦partition leader所在的broker節點宕機,zookeeper會衝其他的broker的partition follower上選擇follower變為parition leader。- Topic分配partition和partition replica的演算法:(1)將Broker(size=n)和待分配的Partition排序。(2)將第i個Partition分配到第(i%n)個Broker上。(3)將第i個Partition的第j個Replica分配到第((i + j) % n)個Broker上- 訊息投遞可靠性一個訊息如何算投遞成功,Kafka提供了三種模式:- 第一種是啥都不管,傳送出去就當作成功,這種情況當然不能保證訊息成功投遞到broker;- 第二種是Master-Slave模型,只有當Master和所有Slave都接收到訊息時,才算投遞成功,這種模型提供了最高的投遞可靠性,但是損傷了效能;- 第三種模型,即只要Master確認收到訊息就算投遞成功;實際使用時,根據應用特性選擇,絕大多數情況下都會中和可靠性和效能選擇第三種模型 訊息在broker上的可靠性,因為訊息會持久化到磁碟上,所以如果正常stop一個broker,其上的資料不會丟失;但是如果不正常stop,可能會使存在頁面快取來不及寫入磁碟的訊息丟失,這可以通過配置flush頁面快取的週期、閾值緩解,但是同樣會頻繁的寫磁碟會影響效能,又是一個選擇題,根據實際情況配置。 訊息消費的可靠性,Kafka提供的是“At least once”模型,因為訊息的讀取進度由offset提供,offset可以由消費者自己維護也可以維護在zookeeper裡,但是當訊息消費後consumer掛掉,offset沒有即時寫回,就有可能發生重複讀的情況,這種情況同樣可以通過調整commit offset週期、閾值緩解,甚至消費者自己把消費和commit offset做成一個事務解決,但是如果你的應用不在乎重複消費,那就乾脆不要解決,以換取最大的效能。- Partition ack:當ack=1,表示producer寫partition leader成功後,broker就返回成功,無論其他的partition follower是否寫成功。當ack=2,表示producer寫partition leader和其他一個follower成功的時候,broker就返回成功,無論其他的partition follower是否寫成功。當ack=-1[parition的數量]的時候,表示只有producer全部寫成功的時候,才算成功,kafka broker才返回成功資訊。這裡需要注意的是,如果ack=1的時候,一旦有個broker宕機導致partition的follower和leader切換,會導致丟資料。
- Delivery Mode : Kafka producer 傳送message不用維護message的offsite資訊,因為這個時候,offsite就相當於一個自增id,producer就儘管傳送message就好了。而且Kafka與AMQ不同,AMQ大都用在處理業務邏輯上,而Kafka大都是日誌,所以Kafka的producer一般都是大批量的batch傳送message,向這個topic一次性發送一大批message,load balance到一個partition上,一起插進去,offsite作為自增id自己增加就好。但是Consumer端是需要維護這個partition當前消費到哪個message的offsite資訊的,這個offsite資訊,high level api是維護在Zookeeper上,low level api是自己的程式維護。(Kafka管理介面上只能顯示high level api的consumer部分,因為low level api的partition offsite資訊是程式自己維護,kafka是不知道的,無法在管理介面上展示 )當使用high level api的時候,先拿message處理,再定時自動commit offsite+1(也可以改成手動), 並且kakfa處理message是沒有鎖操作的。因此如果處理message失敗,此時還沒有commit offsite+1,當consumer thread重啟後會重複消費這個message。但是作為高吞吐量高併發的實時處理系統,at least once的情況下,至少一次會被處理到,是可以容忍的。如果無法容忍,就得使用low level api來自己程式維護這個offsite資訊,那麼想什麼時候commit offsite+1就自己搞定了。- Topic & Partition:Topic相當於傳統訊息系統MQ中的一個佇列queue,producer端傳送的message必須指定是傳送到哪個topic,但是不需要指定topic下的哪個partition,因為kafka會把收到的message進行load balance,均勻的分佈在這個topic下的不同的partition上( hash(message) % [broker數量] )。物理上儲存上,這個topic會分成一個或多個partition,每個partiton相當於是一個子queue。在物理結構上,每個partition對應一個物理的目錄(資料夾),資料夾命名是[topicname]_[partition]_[序號],一個topic可以有無數多的partition,根據業務需求和資料量來設定。在kafka配置檔案中可隨時更高num.partitions引數來配置更改topic的partition數量,在建立Topic時通過引數指定parittion數量。Topic建立之後通過Kafka提供的工具也可以修改partiton數量。 一般來說,(1)一個Topic的Partition數量大於等於Broker的數量,可以提高吞吐率。(2)同一個Partition的Replica儘量分散到不同的機器,高可用。 當add a new partition的時候,partition裡面的message不會重新進行分配,原來的partition裡面的message資料不會變,新加的這個partition剛開始是空的,隨後進入這個topic的message就會重新參與所有partition的load balance- Partition Replica:每個partition可以在其他的kafka broker節點上存副本,以便某個kafka broker節點宕機不會影響這個kafka叢集。存replica副本的方式是按照kafka broker的順序存。例如有5個kafka broker節點,某個topic有3個partition,每個partition存2個副本,那麼partition1存broker1,broker2,partition2存broker2,broker3。。。以此類推(replica副本數目不能大於kafka broker節點的數目,否則報錯。這裡的replica數其實就是partition的副本總數,其中包括一個leader,其他的就是copy副本)。這樣如果某個broker宕機,其實整個kafka內資料依然是完整的。但是,replica副本數越高,系統雖然越穩定,但是回來帶資源和效能上的下降;replica副本少的話,也會造成系統丟資料的風險。 (1)怎樣傳送訊息:producer先把message傳送到partition leader,再由leader傳送給其他partition follower。(如果讓producer傳送給每個replica那就太慢了) (2)在向Producer傳送ACK前需要保證有多少個Replica已經收到該訊息:根據ack配的個數而定 (3)怎樣處理某個Replica不工作的情況:如果這個部工作的partition replica不在ack列表中,就是producer在傳送訊息到partition leader上,partition leader向partition follower傳送message沒有響應而已,這個不會影響整個系統,也不會有什麼問題。如果這個不工作的partition replica在ack列表中的話,producer傳送的message的時候會等待這個不工作的partition replca寫message成功,但是會等到time out,然後返回失敗因為某個ack列表中的partition replica沒有響應,此時kafka會自動的把這個部工作的partition replica從ack列表中移除,以後的producer傳送message的時候就不會有這個ack列表下的這個部工作的partition replica了。 (4)怎樣處理Failed Replica恢復回來的情況:如果這個partition replica之前不在ack列表中,那麼啟動後重新受Zookeeper管理即可,之後producer傳送message的時候,partition leader會繼續傳送message到這個partition follower上。如果這個partition replica之前在ack列表中,此時重啟後,需要把這個partition replica再手動加到ack列表中。(ack列表是手動新增的,出現某個部工作的partition replica的時候自動從ack列表中移除的)- Partition leader與follower:partition也有leader和follower之分。leader是主partition,producer寫kafka的時候先寫partition leader,再由partition leader push給其他的partition follower。partition leader與follower的資訊受Zookeeper控制,一旦partition leader所在的broker節點宕機,zookeeper會衝其他的broker的partition follower上選擇follower變為parition leader。- Topic分配partition和partition replica的演算法:(1)將Broker(size=n)和待分配的Partition排序。(2)將第i個Partition分配到第(i%n)個Broker上。(3)將第i個Partition的第j個Replica分配到第((i + j) % n)個Broker上- 訊息投遞可靠性一個訊息如何算投遞成功,Kafka提供了三種模式:- 第一種是啥都不管,傳送出去就當作成功,這種情況當然不能保證訊息成功投遞到broker;- 第二種是Master-Slave模型,只有當Master和所有Slave都接收到訊息時,才算投遞成功,這種模型提供了最高的投遞可靠性,但是損傷了效能;- 第三種模型,即只要Master確認收到訊息就算投遞成功;實際使用時,根據應用特性選擇,絕大多數情況下都會中和可靠性和效能選擇第三種模型 訊息在broker上的可靠性,因為訊息會持久化到磁碟上,所以如果正常stop一個broker,其上的資料不會丟失;但是如果不正常stop,可能會使存在頁面快取來不及寫入磁碟的訊息丟失,這可以通過配置flush頁面快取的週期、閾值緩解,但是同樣會頻繁的寫磁碟會影響效能,又是一個選擇題,根據實際情況配置。 訊息消費的可靠性,Kafka提供的是“At least once”模型,因為訊息的讀取進度由offset提供,offset可以由消費者自己維護也可以維護在zookeeper裡,但是當訊息消費後consumer掛掉,offset沒有即時寫回,就有可能發生重複讀的情況,這種情況同樣可以通過調整commit offset週期、閾值緩解,甚至消費者自己把消費和commit offset做成一個事務解決,但是如果你的應用不在乎重複消費,那就乾脆不要解決,以換取最大的效能。- Partition ack:當ack=1,表示producer寫partition leader成功後,broker就返回成功,無論其他的partition follower是否寫成功。當ack=2,表示producer寫partition leader和其他一個follower成功的時候,broker就返回成功,無論其他的partition follower是否寫成功。當ack=-1[parition的數量]的時候,表示只有producer全部寫成功的時候,才算成功,kafka broker才返回成功資訊。這裡需要注意的是,如果ack=1的時候,一旦有個broker宕機導致partition的follower和leader切換,會導致丟資料。 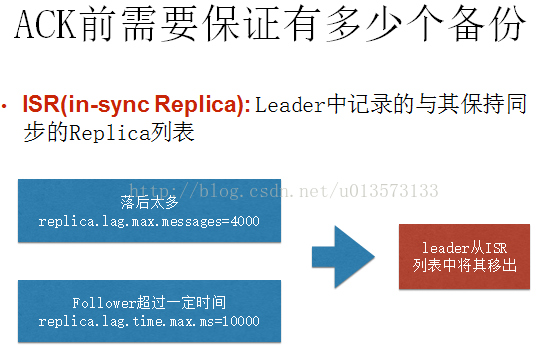

- message狀態:在Kafka中,訊息的狀態被儲存在consumer中,broker不會關心哪個訊息被消費了被誰消費了,只記錄一個offset值(指向partition中下一個要被消費的訊息位置),這就意味著如果consumer處理不好的話,broker上的一個訊息可能會被消費多次。- message持久化:Kafka中會把訊息持久化到本地檔案系統中,並且保持o(1)極高的效率。我們眾所周知IO讀取是非常耗資源的效能也是最慢的,這就是為了資料庫的瓶頸經常在IO上,需要換SSD硬碟的原因。但是Kafka作為吞吐量極高的MQ,卻可以非常高效的message持久化到檔案。這是因為Kafka是順序寫入o(1)的時間複雜度,速度非常快。也是高吞吐量的原因。由於message的寫入持久化是順序寫入的,因此message在被消費的時候也是按順序被消費的,保證partition的message是順序消費的。一般的機器,單機每秒100k條資料。- message有效期:Kafka會長久保留其中的訊息,以便consumer可以多次消費,當然其中很多細節是可配置的。- Produer : Producer向Topic傳送message,不需要指定partition,直接傳送就好了。kafka通過partition ack來控制是否傳送成功並把資訊返回給producer,producer可以有任意多的thread,這些kafka伺服器端是不care的。Producer端的delivery guarantee預設是At least once的。也可以設定Producer非同步傳送實現At most once。Producer可以用主鍵冪等性實現Exactly once- Kafka高吞吐量: Kafka的高吞吐量體現在讀寫上,分散式併發的讀和寫都非常快,寫的效能體現在以o(1)的時間複雜度進行順序寫入。讀的效能體現在以o(1)的時間複雜度進行順序讀取, 對topic進行partition分割槽,consume group中的consume執行緒可以以很高能效能進行順序讀。- Kafka delivery guarantee(message傳送保證):(1)At most once訊息可能會丟,絕對不會重複傳輸;(2)At least once 訊息絕對不會丟,但是可能會重複傳輸;(3)Exactly once每條資訊肯定會被傳輸一次且僅傳輸一次,這是使用者想要的。- 批量傳送:Kafka支援以訊息集合為單位進行批量傳送,以提高push效率。- push-and-pull : Kafka中的Producer和consumer採用的是push-and-pull模式,即Producer只管向broker push訊息,consumer只管從broker pull訊息,兩者對訊息的生產和消費是非同步的。- Kafka叢集中broker之間的關係:不是主從關係,各個broker在叢集中地位一樣,我們可以隨意的增加或刪除任何一個broker節點。- 負載均衡方面: Kafka提供了一個 metadata API來管理broker之間的負載(對Kafka0.8.x而言,對於0.7.x主要靠zookeeper來實現負載均衡)。- 同步非同步:Producer採用非同步push方式,極大提高Kafka系統的吞吐率(可以通過引數控制是採用同步還是非同步方式)。- 分割槽機制partition:Kafka的broker端支援訊息分割槽partition,Producer可以決定把訊息發到哪個partition,在一個partition 中message的順序就是Producer傳送訊息的順序,一個topic中可以有多個partition,具體partition的數量是可配置的。partition的概念使得kafka作為MQ可以橫向擴充套件,吞吐量巨大。partition可以設定replica副本,replica副本存在不同的kafka broker節點上,第一個partition是leader,其他的是follower,message先寫到partition leader上,再由partition leader push到parition follower上。所以說kafka可以水平擴充套件,也就是擴充套件partition。- 離線資料裝載:Kafka由於對可拓展的資料持久化的支援,它也非常適合向Hadoop或者資料倉庫中進行資料裝載。- 實時資料與離線資料:kafka既支援離線資料也支援實時資料,因為kafka的message持久化到檔案,並可以設定有效期,因此可以把kafka作為一個高效的儲存來使用,可以作為離線資料供後面的分析。當然作為分散式實時訊息系統,大多數情況下還是用於實時的資料處理的,但是當cosumer消費能力下降的時候可以通過message的持久化在淤積資料在kafka。- 外掛支援:現在不少活躍的社群已經開發出不少外掛來拓展Kafka的功能,如用來配合Storm、Hadoop、flume相關的外掛。- 解耦: 相當於一個MQ,使得Producer和Consumer之間非同步的操作,系統之間解耦- 冗餘: replica有多個副本,保證一個broker node宕機後不會影響整個服務- 擴充套件性: broker節點可以水平擴充套件,partition也可以水平增加,partition replica也可以水平增加- 峰值: 在訪問量劇增的情況下,kafka水平擴充套件, 應用仍然需要繼續發揮作用- 可恢復性: 系統的一部分元件失效時,由於有partition的replica副本,不會影響到整個系統。- 順序保證性:由於kafka的producer的寫message與consumer去讀message都是順序的讀寫,保證了高效的效能。- 緩衝:由於producer那面可能業務很簡單,而後端consumer業務會很複雜並有資料庫的操作,因此肯定是producer會比consumer處理速度快,如果沒有kafka,producer直接呼叫consumer,那麼就會造成整個系統的處理速度慢,加一層kafka作為MQ,可以起到緩衝的作用。- 非同步通訊:作為MQ,Producer與Consumer非同步通訊
2.Kafka檔案儲存機制
2.1 Kafka部分名詞解釋如下: Kafka中釋出訂閱的物件是topic。我們可以為每類資料建立一個topic,把向topic釋出訊息的客戶端稱作producer,從topic訂閱訊息的客戶端稱作consumer。Producers和consumers可以同時從多個topic讀寫資料。一個kafka叢集由一個或多個broker伺服器組成,它負責持久化和備份具體的kafka訊息。- Broker:Kafka節點,一個Kafka節點就是一個broker,多個broker可以組成一個Kafka叢集。
- Topic:一類訊息,訊息存放的目錄即主題,例如page view日誌、click日誌等都可以以topic的形式存在,Kafka叢集能夠同時負責多個topic的分發。
- Partition:topic物理上的分組,一個topic可以分為多個partition,每個partition是一個有序的佇列
- Segment:partition物理上由多個segment組成,每個Segment存著message資訊
- Producer : 生產message傳送到topic
- Consumer : 訂閱topic消費message, consumer作為一個執行緒來消費
- Consumer Group:一個Consumer Group包含多個consumer, 這個是預先在配置檔案中配置好的。各個consumer(consumer 執行緒)可以組成一個組(Consumer group ),partition中的每個message只能被組(Consumer group ) 中的一個consumer(consumer 執行緒 )消費,如果一個message可以被多個consumer(consumer 執行緒 ) 消費的話,那麼這些consumer必須在不同的組。Kafka不支援一個partition中的message由兩個或兩個以上的consumer thread來處理,即便是來自不同的consumer group的也不行。它不能像AMQ那樣可以多個BET作為consumer去處理message,這是因為多個BET去消費一個Queue中的資料的時候,由於要保證不能多個執行緒拿同一條message,所以就需要行級別悲觀所(for update),這就導致了consume的效能下降,吞吐量不夠。而kafka為了保證吞吐量,只允許一個consumer執行緒去訪問一個partition。如果覺得效率不高的時候,可以加partition的數量來橫向擴充套件,那麼再加新的consumer thread去消費。這樣沒有鎖競爭,充分發揮了橫向的擴充套件性,吞吐量極高。這也就形成了分散式消費的概念。
- 2.2 kafka一些原理概念

8.分散式kafka使用zookeeper來儲存一些meta資訊,並使用了zookeeper watch機制來發現meta資訊的變更並作出相應的動作(比如consumer失效,觸發負載均衡等)Broker node registry: 當一個kafka broker啟動後,首先會向zookeeper註冊自己的節點資訊(臨時znode),同時當broker和zookeeper斷開連線時,此znode也會被刪除.Broker Topic Registry: 當一個broker啟動時,會向zookeeper註冊自己持有的topic和partitions資訊,仍然是一個臨時znode.Consumer and Consumer group: 每個consumer客戶端被建立時,會向zookeeper註冊自己的資訊;此作用主要是為了"負載均衡".一個group中的多個consumer可以交錯的消費一個topic的所有partitions;簡而言之,保證此topic的所有partitions都能被此group所消費,且消費時為了效能考慮,讓partition相對均衡的分散到每個consumer上.Consumer id Registry: 每個consumer都有一個唯一的ID(host:uuid,可以通過配置檔案指定,也可以由系統生成),此id用來標記消費者資訊.Consumer offset Tracking: 用來跟蹤每個consumer目前所消費的partition中最大的offset.此znode為持久節點,可以看出offset跟group_id有關,以表明當group中一個消費者失效,其他consumer可以繼續消費.Partition Owner registry: 用來標記partition正在被哪個consumer消費.臨時znode。此節點表達了"一個partition"只能被group下一個consumer消費,同時當group下某個consumer失效,那麼將會觸發負載均衡(即:讓partitions在多個consumer間均衡消費,接管那些"遊離"的partitions)當consumer啟動時,所觸發的操作:A) 首先進行"Consumer id Registry";B) 然後在"Consumer id Registry"節點下注冊一個watch用來監聽當前group中其他consumer的"leave"和"join";只要此znode path下節點列表變更,都會觸發此group下consumer的負載均衡.(比如一個consumer失效,那麼其他consumer接管partitions).C) 在"Broker id registry"節點下,註冊一個watch用來監聽broker的存活情況;如果broker列表變更,將會觸發所有的groups下的consumer重新balance.總結:1) Producer端使用zookeeper用來"發現"broker列表,以及和Topic下每個partition leader建立socket連線併發送訊息.2) Broker端使用zookeeper用來註冊broker資訊,已經監測partition leader存活性.3) Consumer端使用zookeeper用來註冊consumer資訊,其中包括consumer消費的partition列表等,同時也用來發現broker列表,並和partition leader建立socket連線,並獲取訊息。9.Leader的選擇Kafka的核心是日誌檔案,日誌檔案在叢集中的同步是分散式資料系統最基礎的要素。如果leaders永遠不會down的話我們就不需要followers了!一旦leader down掉了,需要在followers中選擇一個新的leader.但是followers本身有可能延時太久或者crash,所以必須選擇高質量的follower作為leader.必須保證,一旦一個訊息被提交了,但是leader down掉了,新選出的leader必須可以提供這條訊息。大部分的分散式系統採用了多數投票法則選擇新的leader,對於多數投票法則,就是根據所有副本節點的狀況動態的選擇最適合的作為leader.Kafka並不是使用這種方法。Kafka動態維護了一個同步狀態的副本的集合(a set of in-sync replicas),簡稱ISR,在這個集合中的節點都是和leader保持高度一致的,任何一條訊息必須被這個集合中的每個節點讀取並追加到日誌中了,才回通知外部這個訊息已經被提交了。因此這個集合中的任何一個節點隨時都可以被選為leader.ISR在ZooKeeper中維護。ISR中有f+1個節點,就可以允許在f個節點down掉的情況下不會丟失訊息並正常提供服。ISR的成員是動態的,如果一個節點被淘汰了,當它重新達到“同步中”的狀態時,他可以重新加入ISR.這種leader的選擇方式是非常快速的,適合kafka的應用場景。一個邪惡的想法:如果所有節點都down掉了怎麼辦?Kafka對於資料不會丟失的保證,是基於至少一個節點是存活的,一旦所有節點都down了,這個就不能保證了。實際應用中,當所有的副本都down掉時,必須及時作出反應。可以有以下兩種選擇:1. 等待ISR中的任何一個節點恢復並擔任leader。2. 選擇所有節點中(不只是ISR)第一個恢復的節點作為leader.這是一個在可用性和連續性之間的權衡。如果等待ISR中的節點恢復,一旦ISR中的節點起不起來或者資料都是了,那叢集就永遠恢復不了了。如果等待ISR意外的節點恢復,這個節點的資料就會被作為線上資料,有可能和真實的資料有所出入,因為有些資料它可能還沒同步到。Kafka目前選擇了第二種策略,在未來的版本中將使這個策略的選擇可配置,可以根據場景靈活的選擇。這種窘境不只Kafka會遇到,幾乎所有的分散式資料系統都會遇到。10.副本管理以上僅僅以一個topic一個分割槽為例子進行了討論,但實際上一個Kafka將會管理成千上萬的topic分割槽.Kafka儘量的使所有分割槽均勻的分佈到叢集所有的節點上而不是集中在某些節點上,另外主從關係也儘量均衡這樣每個幾點都會擔任一定比例的分割槽的leader.優化leader的選擇過程也是很重要的,它決定了系統發生故障時的空窗期有多久。Kafka選擇一個節點作為“controller”,當發現有節點down掉的時候它負責在游泳分割槽的所有節點中選擇新的leader,這使得Kafka可以批量的高效的管理所有分割槽節點的主從關係。如果controller down掉了,活著的節點中的一個會備切換為新的controller.11.Leader與副本同步對於某個分割槽來說,儲存正分割槽的"broker"為該分割槽的"leader",儲存備份分割槽的"broker"為該分割槽的"follower"。備份分割槽會完全複製正分割槽的訊息,包括訊息的編號等附加屬性值。為了保持正分割槽和備份分割槽的內容一致,Kafka採取的方案是在儲存備份分割槽的"broker"上開啟一個消費者程序進行消費,從而使得正分割槽的內容與備份分割槽的內容保持一致。一般情況下,一個分割槽有一個“正分割槽”和零到多個“備份分割槽”。可以配置“正分割槽+備份分割槽”的總數量,關於這個配置,不同主題可以有不同的配置值。注意,生產者,消費者只與儲存正分割槽的"leader"進行通訊。Kafka允許topic的分割槽擁有若干副本,這個數量是可以配置的,你可以為每個topic配置副本的數量。Kafka會自動在每個副本上備份資料,所以當一個節點down掉時資料依然是可用的。Kafka的副本功能不是必須的,你可以配置只有一個副本,這樣其實就相當於只有一份資料。建立副本的單位是topic的分割槽,每個分割槽都有一個leader和零或多個followers.所有的讀寫操作都由leader處理,一般分割槽的數量都比broker的數量多的多,各分割槽的leader均勻的分佈在brokers中。所有的followers都複製leader的日誌,日誌中的訊息和順序都和leader中的一致。followers向普通的consumer那樣從leader那裡拉取訊息並儲存在自己的日誌檔案中。許多分散式的訊息系統自動的處理失敗的請求,它們對一個節點是否著(alive)”有著清晰的定義。Kafka判斷一個節點是否活著有兩個條件:1. 節點必須可以維護和ZooKeeper的連線,Zookeeper通過心跳機制檢查每個節點的連線。2. 如果節點是個follower,他必須能及時的同步leader的寫操作,延時不能太久。符合以上條件的節點準確的說應該是“同步中的(in sync)”,而不是模糊的說是“活著的”或是“失敗的”。Leader會追蹤所有“同步中”的節點,一旦一個down掉了,或是卡住了,或是延時太久,leader就會把它移除。至於延時多久算是“太久”,是由引數replica.lag.max.messages決定的,怎樣算是卡住了,怎是由引數replica.lag.time.max.ms決定的。只有當訊息被所有的副本加入到日誌中時,才算是“committed”,只有committed的訊息才會傳送給consumer,這樣就不用擔心一旦leader down掉了訊息會丟失。Producer也可以選擇是否等待訊息被提交的通知,這個是由引數acks決定的。Kafka保證只要有一個“同步中”的節點,“committed”的訊息就不會丟失。
- 2.3 kafka拓撲結構
相關推薦
Kafka史上最詳細原理總結 ----看完絕對不後悔
KafkaKafka是最初由Linkedin公司開發,是一個分散式、支援分割槽的(partition)、多副本的(replica),基於zookeeper協調的分散式訊息系統,它的最大的特性就是可以實時的處理大量資料以滿足各種需求場景:比如基於hadoop的批處理系統、低延遲
Kafka史上最詳細原理總結
send shu control 並保存 分布 batch 重傳 應該 還要 Kafka是最初由Linkedin公司開發,是一個分布式、支持分區的(partition)、多副本的(replica),基於zookeeper協調的分布式消息系統,它的最大的特性就是可以實時的處理
看過的都哭了!史上最詳細!手把手教會你完成一個目標識別(目標分割)專案
隨著工業自動化的推進,可能越來越多的同學會感受到老闆接的專案都是傳統工廠自動化程序中的一些環節,比如目標識別。一般有傳統影象方法和順應時代的神經網路方法。其中傳統方法對設計者的影象處理能力要求很高,並且針對每一個專案必須設計特定的識別檢測方法。現在(2018年3月)已經有很多
cocos2d-js ttf字型總結(史上最詳細教程)。
網上有關cocos2d引擎字型使用的教程可以說是滿天飛我就不說了,本文主要講解如何使用第三方.ttf字型。 cocos2d-js 分web和jsb版本,首先講解web版本如何使用第三方xxxx.ttf字型檔,需要在resource中載入字型,格式如下: var g_res
史上最詳細Windows版本搭建安裝React Native環境配置
gin windows系統 adl 搭建環境 tools 想要 變量 rep home 說在前面的話: 感謝同事金曉冰傾情奉獻本環境搭建教程 之前我們已經講解了React Native的OS X系統的環境搭建以及配置,鑒於各大群裏有很多人反應在Windows環境搭建出現各種
移植QT5.6到嵌入式開發板(史上最詳細的QT移植教程)
文件傳輸 嵌入式環境 ubun 導致 字庫 etc -a led fill 目前網上的大多數 QT 移植教程還都停留在 qt4.8 版本,或者還有更老的 Qtopia ,但是目前 Qt 已經發展到最新的 5.7 版本了,我個人也已經使用了很長一段時間的 qt5.6 for
史上最詳細nodejs版本管理器nvm的安裝與使用(附註意事項和優化方案)
技術 註意 nod core 遇到 target 快速 方式 get 使用場景 在Node版本快速更新叠代的今天,新老項目使用的node版本號可能已經不相同了,node版本更新越來越快,項目越做越多,node切換版本號的需求越來越迫切,傳統卸載一個版本在安裝另一個版本的方
Android Studio獲取開發版SHA1值和發布版SHA1值的史上最詳細方法
nal code tail JD rip 通過 提示 打開 tor 前言:使用百度地圖時需要秘鑰,申請秘鑰時需要SHA1值,所以今天就總結一下怎麽獲取這個值。 正常情況下: 一、獲取開發版SHA1: 在此我直接用AndroidStudio提供的命令控制臺了,畢竟做Andro
XX-NET史上最詳細完整教程
偽造 不用 app 分享圖片 AS 版本 firefox 配置過程 自動切換 前言 XX-NET,系GAE類代理,即通過可用Google ip連接Google App Engine項目,然後把所有tcp請求發送給Google App Engine,最終實現科學式網絡的
利用Python實現導彈自動追蹤!室友面前的裝逼利器!史上最詳細!
技術 取數 跟隨鼠標 構造 制作 思想 室友 相同 精確 不好意思 ,上傳錯了。接著看圖! 由於待會要用pygame演示,他的坐標系是y軸向下,所以這裏我們也用y向下的坐標系。 算法總的思想就是根據上圖,把時間t分割成足夠小的片段(比如1/1000,
史上最詳細Windows下安裝 binwalk
github src cti tro 下載 安裝步驟 clas 文件 命令行 1. https://github.com/ReFirmLabs/binwalk到這裏下載binwalk,下載後解壓。 2. 找到下載後的文件夾, 在這裏要進行安裝步驟,一邊按著shift,一邊
史上最詳細Oracle 12c搭建過程(內附源碼包)
請求 源碼包下載 可用 groupadd set port instr lease 添加 簡介 Oracle Database,又名Oracle RDBMS,或簡稱Oracle。是甲骨文公司的一款關系數據庫管理系統。它是在數據庫領域一直處於領先地位的產品。可以說Oracle
黃聰:史上最詳細的kali安裝教程沒有之一
ner 沒有 操作系統 你是 著作權 如圖所示 鏈接 class 區域 首先在vm裏面新建虛擬機,直接選擇典型,然後下一步。 1 2 然後到了這一步,選擇中間的安裝程序光盤鏡像文件,然後去文件裏面
【轉】Hadoop學習--第二篇:史上最詳細的Hadoop環境搭建
GitChat 作者:鳴宇淳 原文: 史上最詳細的Hadoop環境搭建 前言 Hadoop在大資料技術體系中的地位至關重要,Hadoop是大資料技術的基礎,對Hadoop基礎知識的掌握的紮實程度,會決定在大資料技術道路上走多遠。 這是一篇入門文章,Hadoop的學
史上最詳細的新浪廣告系統技術架構優化歷程
內容來源:2017 年 08 月 10 日,新浪廣告開發技術專家徐挺在“第二屆APMCon中國應用效能管理大會【大規模網路架構優化專場】”上進行的《新浪廣告系統的服務化優化歷程》演講分享。IT 大咖說作為獨家視訊合作方,經主辦方和講者審閱授權釋出。 閱讀字數:
史上最詳細的爬蟲教程,Python採集全網最受歡迎的 500 本書!
想看好書?想知道哪些書比較多人推薦,最好的方式就是看資料,接下來用 Python 爬取噹噹網五星圖書榜 TOP500 的書籍,或許能給我們參考參考! Python爬取目標 爬取噹噹網前500本受歡迎的書籍 解析書籍名稱
史上最全面試題總結JavaScript
1.eval是做什麼的? 它的功能是把對應的字串解析成JS程式碼並執行; 應該避免使用eval,不安全,非常耗效能(2次,一次解析成js語句,一次執行)。 null,undefined 的區別? 目前,null和undefined基本是同義的,只有一些細微的差別。null表示"沒有物件"
[程式碼審計]Emlog 6.0 Beta-史上最詳細程式碼審計分析
*2018-11-02 之前這篇文章發到 Freebuf 上面的由於某些原因刪除了,卻被某些爬蟲網站給抓取了,現在公開,希望大家做一個合理的學習,切勿用於非法用途!官網也更新了6.0正式版,現在作為最後公佈也不存在不妥之處,再次宣告:僅供學習參考,任何由個人行為產生的違法犯罪結果自行承擔!
史上最詳細、最完全的ipython使用教程,Python使用者必備!——ipython系列之二
宣告:本文承接前面一篇文章,ipython系列之一;另外,本文所指的ipython不是ipython notebook,ipython notebook已經被jupyter notebook所取代,不再叫ipython notebook了。 前面講解了ipython裡面的一些核心
史上最詳細、最完全的ipython使用教程,Python使用者必備!——ipython系列之一
一、ipython簡介 關於什麼是ipython,本文就不加以介紹了,他是一個非常流行的python直譯器,相比於原生的python直譯器,有太多優點和長處,因此幾乎是python開發人員的必知必會。 1、ipython相比於原生的python有什麼優勢 (1) pyth
