實習點滴(7)--《Investigating LSTM for Punctuation Prediction》論文筆記
原文地址:http://lxie.nwpu-aslp.org/papers/2016ISCSLP-XKT.pdf
本文是利用BiLstm(雙向Lstm)+CRF模型,對片語間的標點符號進行預測。
作者首先強調了,遞迴神經網路(RNN)及其變體在各種序列標籤的任務已經顯示出優越的效能,例如詞性(POS)標籤,分塊和命名實體識別,韻律邊界預測和語言理解。標點符號預測可以被看作是一個典型的序列標籤任務。與此同時,作者認為,如果兩個都是過去和未來的上下文考慮,標點符號標記更準確;使用一個條件隨機域(CRF)層的Lstm可以捕獲輸出上下文資訊,也會有一些效能上的提升
BiLstm最大的優點在於:它不僅可以利用上一個的資訊,還可以利用下一個的資訊。
所做的貢獻:
1)建議使用雙向LSTM(BLSTM)和深度網路架構考慮過去和未來的輸入以及模型輸入特性和輸出標籤之間的複雜關係。
2)調查的上下文建模是否輸出標點標籤,通過CRF層,可以實現對標點符號的預測效能,如預期的那樣在其他序列標籤的任務。
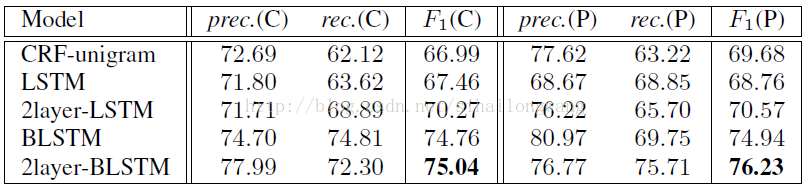
3)通過研究,得出一個結論:一個2層BLSTM模型可以在標點符號生產最先進的效能預測
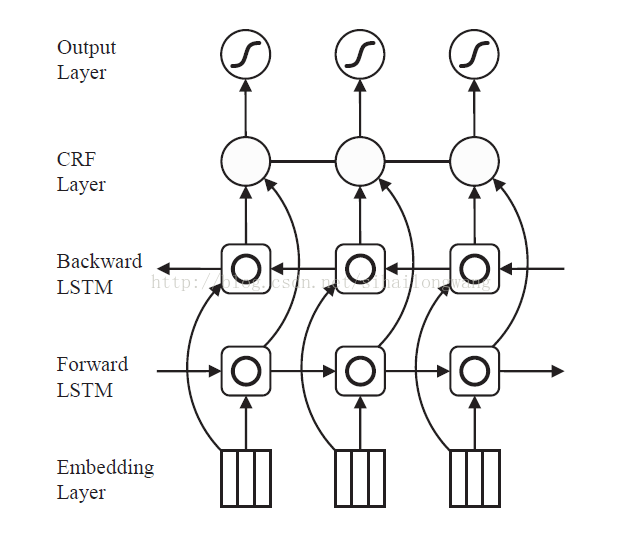
模型結構:
演算法流程:
對於每個epoch迴圈:
對於每個batch迴圈:
(1)BiLstm-CRF正向傳播
(2)CRF正向傳播
(3)BiLstm-CRF反向傳播
(4)更新引數
結束迴圈batch
結束迴圈epoch
實驗需注意的事項:
(1)在輸入前,進行了資料預處理:把問號、感嘆號換成句號;把冒號、分號換成逗號(相當於只預測不打標點、逗號和句號三種情況),其他的符號均刪除
(2)輸入是一句話(經過分詞之後的)和這句話中每個詞語前的標點符號的label
(3)他們採用的是Mecab-toolkit工具進行分詞的
實驗結果: