
大資料分析的下一代架構--IOTA架構設計實踐
IOTA架構提出背景
大資料3.0時代以前,Lambda資料架構成為大資料公司必備的架構,它解決了大資料離線處理和實時資料處理的需求。典型的Lambda架構如下:
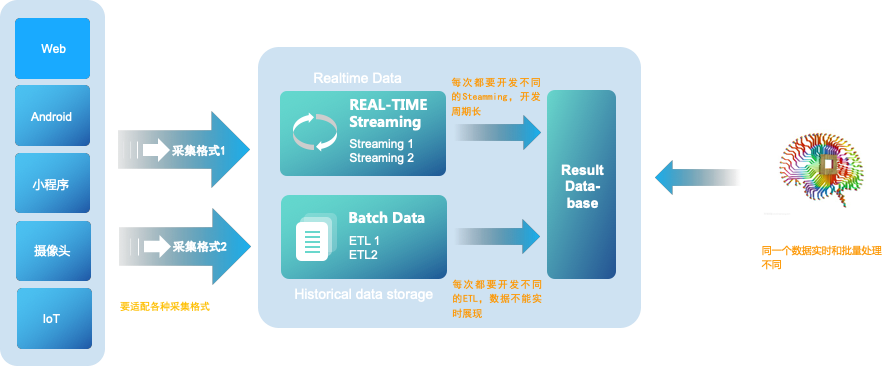
Lambda架構的核心思想是:
資料從底層的資料來源開始,經過各樣的格式進入大資料平臺,然後分成兩條線進行計算。一條線是進入流式計算平臺,去計算實時的一些指標;另一條線進入批量資料處理離線計算平臺,去計算T+1的相關業務指標,這些指標需要隔日才能看見。
Lambda優點是穩定、實時和離線計算高峰錯開,但是它有一些致命缺點,其缺點主要有:
● 實時與批量計算結果不一致引起的資料口徑問題:因為批量和實時計算走的是兩個計算框架和計算程式,算出的結果往往不同,經常看到一個數字當天看是一個數據,第二天看昨天的資料反而發生了變化。
● 批量計算在計算視窗內無法完成:在IOT時代,資料量級越來越大,經常發現夜間只有4、5個小時的時間視窗,已經無法完成白天20多個小時累計的資料,保證早上上班前準時出資料已成為每個大資料團隊頭疼的問題。
● 資料來源變化都要重新開發,開發週期長:每次資料來源的格式變化,業務的邏輯變化都需要針對ETL和Streaming做開發修改,整體開發週期很長,業務反應不夠迅速。
● 伺服器儲存大:資料倉庫的典型設計,會產生大量的中間結果表,造成資料急速膨脹,加大伺服器儲存壓力。
IOTA架構
IOT大潮下,智慧手機、PC、智慧硬體裝置的計算能力越來越強,業務要求資料有實時的響應能力,Lambda架構已經不能適應當今大資料分析時代的需求

IOTA架構的核心概念:
● Common Data Model:貫穿整體業務始終的資料模型,這個模型是整個業務的核心,要保持SDK、Buffer、歷史資料、查詢引擎保持一致。對於使用者資料分析來講可以定義為“主-謂-賓”或者“物件-事件”這樣的抽象模型來滿足各種各樣的查詢。
● Edge SDKs & Edge Servers:這是資料的採集端,不僅僅是過去的簡單的SDK,在複雜的計算情況下,會賦予SDK更復雜的計算,在裝置端就轉化為形成統一的資料模型來進行傳送。例如對於智慧Wi-Fi採集的資料,從AC端就變為“X使用者的MAC 地址-出現- A樓層(2018/4/11 18:00)”這種主-謂-賓結構。對於APP和H5頁面來講,沒有計算工作量,只要求埋點格式即可。
● Real-Time Data:即實時資料快取區。這部分是為了達到實時計算的目的,海量資料接收不可能海量實時入歷史資料庫,會出現建立索引延遲、歷史資料碎片檔案等問題。因此,有一個實時資料快取區來儲存最近幾分鐘或者幾秒鐘的資料。這塊可以使用Kudu或HBase等元件來實現。此處的資料模型和SDK端資料模型是保持一致的,都是Common Data Model。
● Historical Data:歷史資料沉浸區,這部分是儲存了大量的歷史資料,為了實現Ad-hoc查詢,將自動建立相關索引提高整體歷史資料查詢效率,從而實現秒級複雜查詢百億條資料。例如可以使用HDFS儲存歷史資料,此處的資料模型依然SDK端資料模型是保持一致的Common Data Model。
● Dumper:Dumper的主要工作就是把最近幾秒或者幾分鐘的Realtime Data區的資料,根據匯聚規則、建立索引,儲存到歷史儲存結構Historical Data區中。
● Query Engine:查詢引擎,提供統一的對外查詢介面和協議(例如SQL),把Realtime Data和Historical Data合併到一起查詢,從而實現對於資料實時的Ad-hoc查詢。例如常見的計算引擎可以使用Presto、Impala、Clickhouse等。
● Realtime model feedback:通過Edge computing技術,在邊緣端有更多的互動可以做,可以通過在Realtime Data去設定規則來對Edge SDK端進行控制,例如,資料上傳的頻次降低、語音控制的迅速反饋,某些條件和規則的觸發等等。
整體思路是設定標準資料模型,通過邊緣計算技術把所有的計算過程分散在資料產生、計算和查詢過程當中,以統一的資料模型貫穿始終,從而提高整體的預算效率,同時滿足即時計算的需要,可以使用各種Ad-hoc Query來查詢底層資料。
IOTA整體架構引擎例項
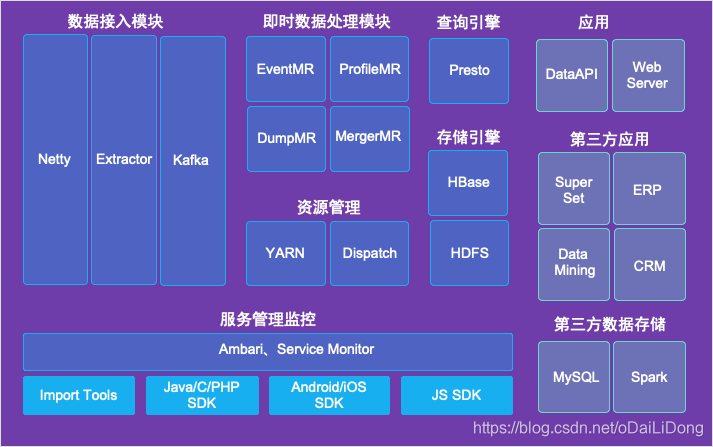
IOTA的特點:
- 去“ETL”化
- 高效:時時入庫即時分析
- 穩定:經過易觀5.8Pb,5.2億月活資料錘鍊
- 便捷:支援SQL級別的二次開發和UDAF定義
- 擴充性強:元件基於Apache開源協議,可支援眾多開源儲存對接
IOTA架構 — 資料模型 Common Data Model
Common Data Model :
貫穿整體業務始終的核心資料模型,保持SDK、Buffer、歷史資料、查詢引擎端資料模型一致。
對於使用者行為分析業務來講:
可以定義為“主-謂-賓”或者“使用者-事件”抽象模型來滿足各種各樣的查詢。
例如 :
智慧手錶:X使用者 – 進行了 – 游泳運動
視訊APP: X使用者 – 播放 – 影片
電商網站:X使用者 – 購買 – 手機( 2018/12/11 18:00:00 , IP , GPS)”
IOTA架構 — 資料模型 Common Data Model
使用者-事件模型之事件 (Event)
事件(Event)
主要是描述使用者做了什麼事情,記錄使用者觸發的行為,例如註冊、登入、支付事件等等
事件屬性
更精準的描述使用者行為,例如事件發生的位置、方式和內容
每一條event資料對應使用者的一次行為資訊, 例如瀏覽、登入、搜尋事件等等。

使用者-事件模型之使用者 (Profile)
使用者這裡沒有太多要說的,要提醒注意唯一標識這塊
唯一標識
方舟的事件模型中,資料上報時會有使用者這個實體,使用 who 來進行標識,在登入前匿名階段,who 中會記錄一個 匿名 ID ,登入後會記錄一個註冊 ID。
1.1 匿名 ID
匿名 ID 用來在使用者主體未登入應用之前標識,當用戶開啟整合有方舟 SDK 的應用時,SDK 會給其分配一個 UUID 來做為匿名 ID 。
當然,方舟也提供了給使用者主體設定匿名 ID 的方式,比如可以使用裝置 ID ( iOS 的 IDFA/IDFV,Web 的 Cookie 等)。
1.2 註冊 ID
通常是業務資料庫裡的主鍵或其它唯一標識,註冊 ID 是更加精確的使用者 ID,但很多應用不會用註冊 ID,或者使用者使用一些功能時是在未登入的狀態下進行的,此時,就不會有註冊 ID。
另外,在方舟系統中,我們以為使用者主體來進行分析,這個使用者主體可能是一個人,一個帳號,也可能是一個家電,一輛汽車。具體以什麼做為使用者主體,要根據使用者實際的業務場景來決定。
1.3 distinct_id
即使有了who( 註冊 ID / 匿名 ID),實際使用中也會存在註冊使用者匿名訪問等情況,所以需要一個唯一標識將使用者行為貫穿起來,distinct_id 就是在who 的基礎上根據一些規則生成的唯一 ID。
IOTA架構 — 資料流轉過程
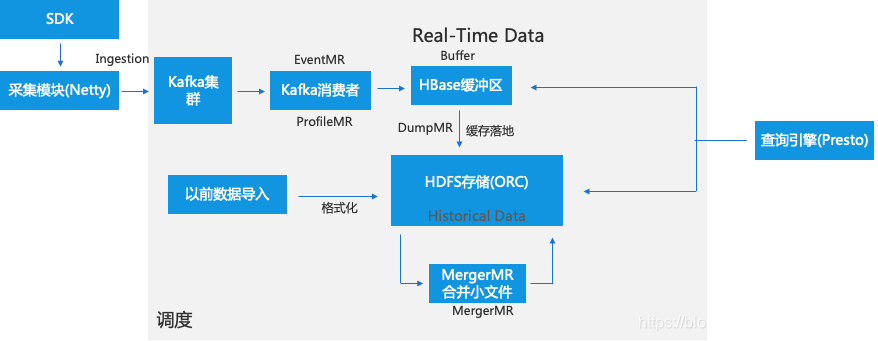
IOTA架構 — 資料採集(Ingestion)
資料採集

資料採集要注意:
傳輸加密
策略控制
伺服器可以隨時更改發發送策略,比如傳送頻率調整,重試頻率
傳送策略優先順序: 伺服器策略>debug>使用者設定>啟動、間隔策略
伺服器約束示例
伺服器端返回示意:

IOTA架構 — 資料緩衝區(Real-Time Data)
Real-Time Data區是資料緩衝區,當從Kafka消費完資料首先落入Buffer區,這樣設計主要是因為目前主流儲存格式都不支援實時追加(Parquet、ORC)。Buffer區一般採用HBase、Kudu等高效能儲存,考慮到成熟度、可控、社群等因素,我們採用HBase。

-
HBase的特點:
– 主鍵查詢速度快
– Scan效能慢 -
如何解決Scan效能:-- In-memory
– Snappy壓縮
– 動態列族
– 只存一定量的資料
– Rowkey設計hash
– hfile資料轉換成OrcFile
IOTA架構 — 歷史儲存區(Historical data storage)
當HBase裡的資料量達到百萬規模時,排程會啟動DumpMR(Spark、MR任務)會將HBase資料flush到HDFS中去,因為還要支援資料的實時查詢,我們採用R/W表切換方案,即一直寫入一張表直到閾值,就寫入新表,老表開始轉為ORC格式。
HDFS高效儲存:
按天分割槽
基於使用者ID,事件時間排序
冷熱分層
Orc儲存
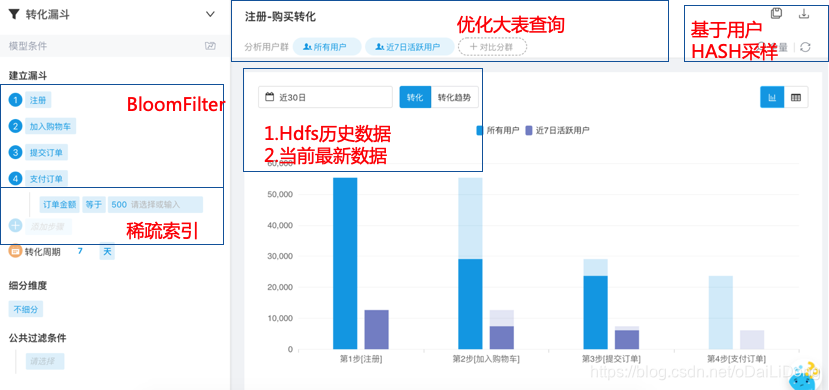
BloomFilter
稀疏索引
Snappy壓縮
小檔案問題:
不按事件分割槽
MergerMR定時合併小檔案
稀疏索引:

資料有序:

IOTA架構 — 即時查詢引擎(Query Engine)
因為需支援從歷史到最近一條資料的即時查詢,查詢引擎需要同時查HBase緩衝區裡和歷史儲存區的資料,採用View檢視的方式進行查詢。
Query Engine基於Presto進行二次開發
- HBase-Connector定製開發、優化
- 通過檢視View建立熱資料與歷史資料的聯合計算
- Session,漏斗,留存,智慧路徑等模型的演算法實現

關於olap引擎測評請參考:
http://geek.analysys.cn/topic/21 開源OLAP引擎測評報告(SparkSql、Presto、Impala、HAWQ、ClickHouse、GreenPlum)
IOTA架構 — 排程(EasyScheduler)
整個資料處理流程都離不開一個元件 – 排程。
考慮排程易用性、可維護性及方便二次開發等綜合原因,我們開發了自己的大資料分散式排程系統EasyScheduler。
EasyScheduler(易排程) 主要解決資料研發ETL 錯綜複雜的依賴關係,而不能直觀監控任務健康狀態等問題。EasyScheduler以DAG流式的方式將Task組裝起來,
可實時監控任務的執行狀態,同時支援重試、從指定節點恢復失敗、暫停及Kill任務等操作。
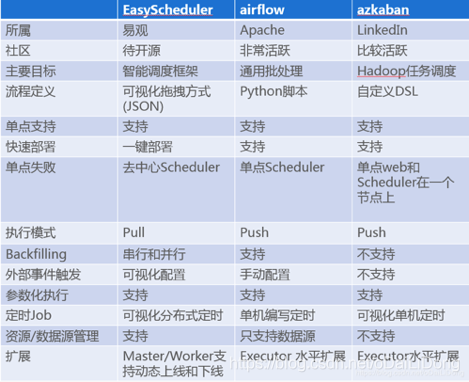
更多關於排程的資訊:
https://blog.csdn.net/oDaiLiDong/article/details/84994247
IOTA架構 — 優化策略
IOTA架構 — 優化經驗
1、添加布隆過濾器,TPC-DS有50%-80%效能提升
2、全域性 + 區域性字典,儘量整型,避免過長字串,數倍效能提升
如:事件名稱使用id,查詢速度提升近1倍
3、資料快取Alluxio使用,2~5倍效能提升
4、SQL優化,耗時sql優化非常重要
5、Unsafe呼叫。Presto裡開源Slice的使用
IOTA架構 — 前進方向
天下武功唯快不破!

1、資料本地化,儘量避免shuffle呼叫
2、更合適的索引構建,如bitmap索引
3、堆外記憶體的使用,避免GC問題

更多關於IOTA架構的交流請加我微信,加我時請註明公司+職位+IOTA,謝謝:
