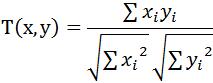推薦系統的幾種相似度計算
阿新 • • 發佈:2019-01-03
對使用者的行為進行分析得到使用者的偏好後,可以根據使用者的偏好計算相似使用者和物品,然後可以基於相似使用者或物品進行推薦。這就是協同過濾中的兩個分支了,即基於使用者的協同過濾和基於物品的協同過濾。
關於相似度的計算,現有的幾種方法都是基於向量(Vector)的,其實也就是計算兩個向量的距離,距離越近相似度越大。在推薦場景中,在使用者-物品偏好的二維矩陣中,我們可以將一個使用者對所有物品的偏好作為一個向量來計算使用者之間的相似度,或者將所有使用者對某個物品的偏好作為一個向量來計算物品之間的相似度。
1.同現相似度
計算公式為:
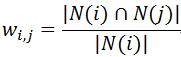
分母|N(i)|是喜歡物品i的使用者數,而分子|N(i)∩N(j)|是同時喜歡物品i和物品j的使用者資料。
為了防止j為熱門物品,修正為:
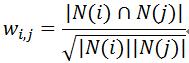
2.歐式距離相似度
最初用於計算歐幾里得空間中的兩個點的距離,假設x、y是n維空間的兩個點,它們之間的歐幾里得距離是:
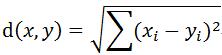
可以看出,當n=2時,歐幾里得距離是平面上的兩點的距離。
當用歐幾里得距離表示相似度時,一般採用一下公式進行轉換:距離越小,相似度越大。
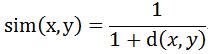
3.Cosine相似度
Cosine相似度被廣泛應用於計算文件資料的相似度: