
推薦演算法基礎--相似度計算方法彙總
推薦系統中相似度計算可以說是基礎中的基礎了,因為基本所有的推薦演算法都是在計算相似度,使用者相似度或者物品相似度,這裡羅列一下各種相似度計算方法和適用點
餘弦相似度
這個基本上是最常用的,最初用在計算文字相似度效果很好,一般像tf-idf一下然後計算,推薦中在協同過濾以及很多演算法中都比其他相似度效果理想。
由於餘弦相似度表示方向上的差異,對距離不敏感,所以有時候也關心距離上的差異會先對每個值都減去一個均值,這樣稱為調整餘弦相似度
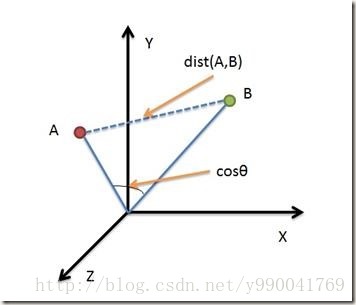
歐式距離
基本上就是兩個點的空間距離,下面這個圖就能很明顯的說明他和餘弦相似度區別,歐式距離更多考慮的是空間中兩條直線的距離,而餘弦相似度關心的是空間夾角。所以
歐氏距離能夠體現個體數值特徵的絕對差異,所以更多的用於需要從維度的數值大小中體現差異的分析,如使用使用者行為指標分析使用者價值的相似度或差異。
餘弦距離更多的是從方向上區分差異,而對絕對的數值不敏感,更多的用於使用使用者對內容評分來區分興趣的相似度和差異,同時修正了使用者間可能存在的度量標準不統一的問題(因為餘弦距離對絕對數值不敏感)。
皮爾遜相關性(PC)
上面是總體相關係數,常用希臘小寫字母 ρ (rho) 作為代表符號。估算樣本的協方差和標準差,可得到樣本相關係數(樣本皮爾遜係數),常用英文小寫字母 r 代表:
其實這個就是前面講的調整的餘弦相似度,因為在推薦系統中均值分為使用者的均值和物品的均值,這裡相當於是物品的均值。這個也是比較常用的。
斯皮爾曼等級相關係數
斯皮爾曼相關係數(Spearman Rank Correlation)被定義成 等級變數之間的皮爾遜相關係數。[1] 對於樣本容量為 n的樣本, n個 原始資料
推薦系統中相似度計算可以說是基礎中的基礎了,因為基本所有的推薦演算法都是在計算相似度,使用者相似度或者物品相似度,這裡羅列一下各種相似度計算方法和適用點
餘弦相似度
similarity=cos(θ)=A⋅B∥A∥∥B∥=∑i=1nAi×Bi∑i=1n(
在推薦系統中,相似度的計算是一個很重要的課題。而相似度的計算方法多種多樣,今天我們來把這些方法比較一下,也為以後做專案留個筆記。其實無論是基於user的cf還是基於item的cf,亦或是基於svd的推薦,相似度計算都是必不可少的一步,只不過cf中計算相似度是一箇中間步驟,而
雜湊演算法實現圖片相似度計算
實現圖片相似度比較的雜湊演算法有三種:均值雜湊演算法,差值雜湊演算法,感知雜湊演算法
1.均值雜湊演算法
一張圖片就是一個二維訊號,它包含了不同頻率的成分。亮度變化小的區域是低頻成分,它描述大範圍的資訊。而亮度變化劇烈的區域(比如物
在上面兩篇文章已經講了如何通過使用者對產品的評分分別計算出某個使用者與其他使用者之間的相似度,那麼在計算完相似度後如何才能獲取和該使用者相似度高的人呢,方法分為兩種:
1、固定數量的K個鄰居,(K-neighborhoods)。意思很明確,就是按分數高低降序取K個
2、基
一、概念:
時間複雜度是總運算次數表示式中受n的變化影響最大的那一項(不含係數)
比如:一般總運算次數表示式類似於這樣:
a*2^n+b*n^3+c*n^2+d*n*lg(n)+e*n+f
a ! =0時,時間複雜度就是O(2^n);
a=0,b<
一、簡述
這幾天在看《推薦系統實戰》這本書。其中,基於領域的演算法是推薦系統中最基本的演算法,什麼是基於領域的演算法呢?簡單來說就是基於使用者(或物品)的協同過濾演算法,所謂的協同的意思就是需要使用者(或物品)共同參與。從而通過使用者的行為, title rac 相似度 無法 tween hive any 明顯 embed
python工具包-pyssim
簡介
python工具包,用來計算圖像之間的結構相似性 (Structural Similarity Image Metric: SSIM)。結構相似性介紹
在做自然語言處理的過程中,我們經常會遇到需要找出相似語句的場景,或者找出句子的近似表達,這時候我們就需要把類似的句子歸到一起,這裡面就涉及到句子相似度計算的問題,那麼本節就來了解一下怎麼樣來用 Python 實現句子相似度的計算。
基本方法
句子相似度計算我們一共歸類
對使用者的行為進行分析得到使用者的偏好後,可以根據使用者的偏好計算相似使用者和物品,然後可以基於相似使用者或物品進行推薦。這就是協同過濾中的兩個分支了,即基於使用者的協同過濾和基於物品的協同過濾。
關於相似度的計算,現有的幾種方法都是基於向量(Vector)
######################
尊重版權,轉載註明地址
######################
相似度演算法介紹
相似度演算法主要任務是衡量物件之間的相似程度,是資訊檢索、推薦系統
Abstract:TF-IDF演算法是一種常用的詞頻統計方法,常被用於關鍵詞提取、文字摘要、文章相似度計算等。
TF-IDF的演算法思路
TF詞頻(Text Frequency):統計出現次數最多的詞
IDF逆文件頻率(Inverse Document Frequ
3. 向量內積
向量內積是線性代數裡最為常見的計算,實際上它還是一種有效並且直觀的相似性測量手段。向量內積的定義如下:
直觀的解釋是:如果 x 高的地方 y 也比較高, x 低的地方 y 也比較低,那麼整體的內積是偏大的,也就是說 x 和 y 是相似的。舉個例子,在一段長的序列訊號 A 中尋找哪一段與短序 之間 ade length pri append 一個 lines 好的 javascrip
歐幾裏德距離
>
計算兩組數據之間的距離,偏好越類似的人其距離就越短。。。為了處理方便。須要一個函數來對偏好越相近的情況給出越大的值(0~1 計算 使用 val PE 相似度 ID turn 稀疏 code 協同過濾中用戶距離計算
# 構建共同的評分向量
def build_xy(user_id1, user_id2):
bool_array = df.loc[user_id1].notnull() & tis afr 廣播 圖片 times 導致 coord 向量 校驗
無論是ICF基於物品的協同過濾、UCF基於用戶的協同過濾、基於內容的推薦,最基本的環節都是計算相似度。如果樣本特征維度很高或者<user, item, score>的維度很大,都會導致無法直 實用 好的 svm center 大量 network alt 詞匯 很難 短文本的相似度計算方法可以分為兩大類:基於深度學習的方法和基於非深度學習的方法。科研方面基本都是從深度學習方面入手,但個人覺得想把單語言的短文本相似度計算給做出花來比較難,相對而言基 就是 mage method 根據 計算 down youdao 比較 所有 1.前言
在自然語言處理過程中,經常會涉及到如何度量兩個文本之間的相似性,我們都知道文本是一種高維的語義空間,如何對其進行抽象分解,從而能夠站在數學角度去量化其相似性。
有了文本之間相似性的度量方
關於影象相似度,主要包括顏色,亮度,紋理等的相似度,比較直觀的相似度匹配是直方圖匹配.直方圖匹配演算法簡單,但受亮度,噪聲等影響較大.另一種方法是提取影象特徵,基於特徵進行相似度計算,常見的有提取影象的sift特徵,再計算兩幅影象的sift特徵相似度.對於不同的影象型別,也可以採用不同的
(1)傳統的傑卡德相似度計算公式如下,
其中A,B可以為不同使用者的購物品類,
當用戶量特別大的時候,導致計算複雜度比較高,因為直接進行了笛卡爾積運算,這時候可能沒有辦法進行運算。優化方法 二、歐幾里得距離
幾個資料集之間的相似度一般是基於每對物件間的距離計算,最常用的是歐幾里德距離:
#-*-coding:utf-8 -*-#計算歐幾里德距離:def euclidean(p,q):#如果兩資料集數目不同,計算兩者之間都對應有的數same = 0for i in p: if i in q: 相關推薦
推薦演算法基礎--相似度計算方法彙總
推薦系統中常見的幾種相似度計算方法和其適用資料
雜湊演算法-圖片相似度計算
推薦演算法之-相似鄰居計算
演算法時間複雜度計算方法
推薦系統基礎演算法--餘弦相似度演算法詳解及應用
計算兩張圖片相似度的方法總結
句子相似度計算的幾種方法
推薦系統的幾種相似度計算
推薦系統中相似度演算法介紹及效果測試
解析TF-IDF演算法原理:關鍵詞提取,自動摘要,文字相似度計算
【轉載】機器學習計算距離和相似度的方法
類似度計算方法
用戶相似度計算
Spark MLlib 之 大規模數據集的相似度計算原理探索
短文本相似度計算
1. 文本相似度計算-文本向量化
影象相似度計算-kmeans聚類
協同過濾相似度計算
相似度的方法