
伺服器監控(包括效能指標與web應用程式)
伺服器監控
在搭建伺服器時,除了部署webapp之外,還需要服務的異常資訊與伺服器效能指標進行監控,一旦有異常則通知管理員。
伺服器使用Linux+Nginx-1.9.15+Tomcat7+Java搭建的。
編寫指令碼檢測錯誤日誌和伺服器效能指標,一旦新生錯誤日誌或者效能降低到設定的閾值時,則使用雲監控將報警上傳到雲賬號。
服務執行監控
錯誤日誌包含以下三個方面:
- nginx 錯誤資訊監控(nginx.conf配置)
- ${NGINX_HOME}/logs/error.log
- tomcat 錯誤資訊監控(server.xml配置)
- ${TOMCAT_HOME}/logs/catalina.out
- webapp錯誤資訊監控(log4j)
- ${WEBAPP_HOME}/log/error
機器效能指標
一般都會使用linux系統的機器作為伺服器,那麼當在上面搭建服務時,需要對一些常用的效能指標進行監控,那麼一般包含哪些指標呢?下面對其進行一些總結,歡迎補充…
指標
- CPU(Load) CPU使用率/負載
- Memory 記憶體
- Disk 磁碟空間
- Disk I/O 磁碟I/O
- Network I/O 網路I/O
- Connect Num 連線數
- File Handle Num 檔案控制代碼數
…
CPU
說明
機器的CPU佔有率越高,說明機器處理越忙,運算型任務越多。一個任務可能不僅會有運算部分,還會有I/O(磁碟I/O與網路I/O)部分,當在處理I/O時,時間片未完其CPU也會釋放,因此某個時間點的CPU佔有率沒有太大的意義,因此需要計算一段時間內的平均值,那麼平均負載(Load Average)這個指標便能很好得對其進行表徵。平均負載:它是根據一段時間內佔有CPU的程序數目和等待CPU的程序數目計算出來的,其中等待CPU的程序不包括處於wait狀態的程序,比如在等待I/O的程序,即指那些就緒狀態的程序,執行只缺CPU這個資源。具體如何計算可以參見Linux核心程式碼,計算出一個數之後,然後除以CPU核數,結果:- <=3 則系統性能較好。
- <=4 則系統性能可以,可以接收。
- >5 則系統性能負載過重,可能會發生嚴重的問題,那麼就需要擴容了,要麼增加核,要麼分散式叢集。
檢視命令
vmstat
vmstat n m
n表示每隔n秒採集一次,m表示一共採集多少次,如果m沒有,那麼會一直採集下去. 在終端鍵入vmstat 5
結果各欄位解釋如下(這裡只解釋與CPU相關的):
r:表示執行佇列(就是說多少個程序真的分配到CPU),當這個值超過了CPU數目,就會出現CPU瓶頸了。這個也和top的負載有關係,一般負載超過了3就比較高,超過了5就高,超過了10就不正常了,伺服器的狀態很危險。top的負載類似每秒的執行佇列。如果執行佇列過大,表示你的CPU很繁忙,一般會造成CPU使用率很高。
b:表示阻塞的程序,如在等待I/O請求。
in:每秒CPU的中斷次數,包括時間中斷。
cs:每秒上下文切換次數,例如我們呼叫系統函式,就要進行上下文切換,執行緒的切換,也要程序上下文切換,這個值要越小越好,太大了,要考慮調低執行緒或者程序的數目,例如在apache和nginx這種web伺服器中,我們一般做效能測試時會進行幾千併發甚至幾萬併發的測試,選擇web伺服器的程序可以由程序或者執行緒的峰值一直下調,壓測,直到cs到一個比較小的值,這個程序和執行緒數就是比較合適的值了。系統呼叫也是,每次呼叫系統函式,我們的程式碼就會進入核心空間,導致上下文切換,這個是很耗資源,也要儘量避免頻繁呼叫系統函式。上下文切換次數過多表示你的CPU大部分浪費在上下文切換,導致CPU幹正經事的時間少了,CPU沒有充分利用,是不可取的。
us:使用者CPU時間佔比(%),例如在做高運算的任務時,如加密解密,那麼會導致us很大,這樣,r也會變大,造成系統瓶頸。
sy:系統CPU時間佔比(%),如果太高,表示系統呼叫時間長,如IO頻繁操作。
id :空閒 CPU時間佔比(%),一般來說,id + us + sy = 100,一般認為id是空閒CPU使用率,us是使用者CPU使用率,sy是系統CPU使用率。
wt:等待IO的CPU時間。uptime
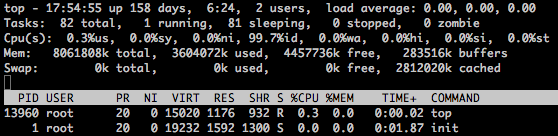
17:53:46為當前時間
up 158 days, 6:23機器執行時間,時間越大說明你的機器越穩定
2 users使用者連線數,而不是總使用者數
oad average: 0.00, 0.00, 0.00 最近1分鐘,5分鐘,15分鐘的系統平均負載。
將平均負載值除以核數,如果結果不大於3,那麼系統性能較好,如果不大於4那麼系統性能可以接受,如果大於5,那麼系統性能較差。top
top命令用於顯示程序資訊,top詳細見http://www.cnblogs.com/peida/archive/2012/12/24/2831353.html
這裡主要關注Cpu(s)統計那一行:
us:使用者空間佔用CPU的百分比
sy:核心空間佔用CPU的百分比
ni:改變過優先順序的程序佔用CPU的百分比
id: 空閒CPU百分比
wa: IO等待佔用CPU的百分比
hi:硬中斷(Hardware IRQ)佔用CPU的百分比
si:軟中斷(Software Interrupts)佔用CPU的百分比
從top的結果看CPU負載情況,主要看us和sy,其中us<=70,sy<=35,us+sy<=70說明狀態良好,同時可以結合idle值來看,如果id<=70 則表示IO的壓力較大。也可以和uptime一樣,看第一行。引用[1]
- 分析
表示系統CPU正常,主要有以下規則:
- CPU利用率:us <= 70,sy <= 35,us + sy <= 70。引用[1]
- 上下文切換:與CPU利用率相關聯,如果CPU利用率狀態良好,大量的上下文切換也是可以接受的。引用[1]
- 可執行佇列:每個處理器的可執行佇列<=3個執行緒。


Memory
- 說明
記憶體也是系統執行效能的一個很重要的指標,如果一個機器記憶體不足,那麼將會導致程序執行異常而退出。如果程序發生記憶體洩漏,則會導致大量記憶體被浪費而無足夠可用記憶體。記憶體監控一般包括total(機器總記憶體)、free(機器可用記憶體)、swap(交換區大小)、cache(快取大小)等。 檢視命令
vmstat
結果各欄位解釋如下(這裡只解釋與Memory相關的):
swpd:虛擬記憶體已使用的大小,如果大於0,表示你的機器實體記憶體不足了,如果不是程式記憶體洩露的原因,那麼你該升級記憶體了或者把耗記憶體的任務遷移到其他機器,單位為KB。
free :空閒的實體記憶體的大小,我的機器記憶體總共8G,剩餘4457612KB,單位為KB。
buff:Linux/Unix系統來儲存目錄裡面有什麼內容,許可權等的快取,這裡大概佔用280M,單位為KB。
cache:cache直接用來記憶我們開啟的檔案,給檔案做緩衝,這裡大概佔用280M(這裡是Linux/Unix的聰明之處,把空閒的實體記憶體的一部分拿來做檔案、目錄和程序地址空間的快取,是為了提高程式執行的效能,當程式使用記憶體時,buffer/cached會很快地被使用),單位為KB。
si: 每秒從磁碟讀入虛擬記憶體的大小,如果這個值大於0,表示實體記憶體不夠用或者記憶體洩露了,要查詢耗記憶體程序解決掉。本機記憶體充裕,一切正常,單位為KB。
so:每秒虛擬記憶體寫入磁碟的大小,如果這個值大於0,同上,單位為KB。free
第二行是記憶體資訊,total為機器總記憶體,used為多少已經使用,free為多少空閒,shared為多個程序共享的記憶體總額,buffers與cache都是磁碟快取的大小,分別同vmstat裡面的buff與cache. 單位都是M.
第三行是buffers與cache總額的used與free. 單位都是M.
第四行是交換區swap的總額、已用與free. 單位都是M.
區別:第二行(mem)的used/free與第三行(-/+ buffers/cache) used/free的區別。 這兩個的區別在於使用的角度來看,第二行是從OS的角度來看,因為對於OS,buffers/cached 都是屬於被使用,所以他的可用記憶體是4353M, 已用記憶體是3519M, 其中包括,核心(OS)使用+Application(X, oracle,etc)使用的+buffers+cached.
第三行所指的是從應用程式角度來看,對於應用程式來說,buffers/cached 是等於可用的,因為buffer/cached是為了提高檔案讀取的效能,當應用程式需在用到記憶體的時候,buffer/cached會很快地被回收。
所以從應用程式的角度來說,可用記憶體=系統free memory+buffers+cached。top
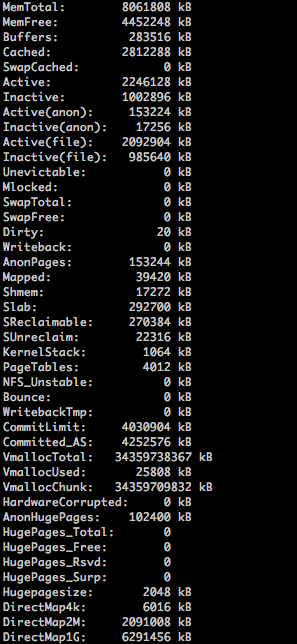
只關注與記憶體相關的統計資訊,即Mem與Swap行。分別是Mem與Swap的總額、已用量、空閒量、buffers與cache. 這裡便驗證了buffers是快取目錄裡面有什麼內容,許可權等資訊的,而cache是用來swap的快取的.cat /proc/meminfo
主要這幾個欄位:
MemTotal:記憶體總額
MemFree:記憶體空閒量
Buffers:同top命令的buffers
Cached:同top命令的cache
SwapToatl:Swap區總大小
SwapFree:Swap區空閒大小
分析
表示系統Mem正常,主要有以下規則:- swap in (si) == 0,swap out (so) == 0
- 可用記憶體/實體記憶體 >= 30%

磁碟
- 說明
機器的磁碟空間也是一個重要的指標,一旦使用率超過閾值而使得可用不足,那麼就需要進行擴容或者清除一些無用的檔案。 - 檢視命令
df
Filesystem:檔案系統的名稱
1K-blocks:1K塊的檔案系統
Used:已使用量,單位為KB
Available:空閒量,單位為KB
Use%:已使用佔比
Mounted on:掛載的目錄
- 分析
表示系統磁碟空間正常,主要有以下規則:
- Use% <= 90%

磁碟I/O
- 說明
機器的磁碟空間也是一個重要的指標,一旦磁碟I/O過重,那麼說明執行的程序在大量的檔案讀寫並且cache命中率低。那麼一個簡單的方法便是增大檔案快取大小來提高命中率從而降低I/O。
在Linux中,核心希望能儘可能產生次缺頁中斷(從檔案快取區讀),並且能儘可能避免主缺頁中斷(從硬碟讀),這樣隨著缺頁中斷的增多,檔案快取區也逐步增大,直到系統只有少量可用實體記憶體的時候 Linux 才開始釋放一些不用的頁。引用[1] - 檢視命令
vmstat
bi :塊裝置每秒接收的塊數量,這裡的塊裝置是指系統上所有的磁碟和其他塊裝置,預設塊大小1024byte。
bo:塊裝置每秒傳送的塊數量,例如我們讀取檔案,bo就要大於0。bi和bo一般都要接近0,不然就是IO過於頻繁,需要調整。iostat
Linux段為機器系統資訊: 系統名稱、hostname、當前時間、系統版本.
avg-cpu段為cpu的統計資訊(平均值):
%user:使用者級別執行所使用的CPU的百分比.
%nice:nice操作所使用的CPU的百分比.
%sys:在系統級別(kernel)執行所使用CPU的百分比.
%iowait:CPU等待硬體I/O時,所佔用CPU百分比.
%idle:CPU空閒時間的百分比.
Device段段為裝置資訊(上圖中有兩個盤vda與vdb):
tps: 每秒鐘傳送到的I/O請求數.
Blk_read/s: 每秒讀取的block數.
Blk_wrtn/s: 每秒寫入的block數.
Blk_read: 讀入的block總數.
Blk_wrtn: 寫入的block總數.sar -d 1 1
sar -d表示檢視磁碟報告 1 1 表示間隔1s,執行1次
其實cpu、快取區、檔案讀寫、系統交換區等資訊都可以通過該命令檢視,只是選項不同,具體參見:http://blog.chinaunix.net/uid-23177306-id-2531032.html
第一個段為機器系統資訊,同iostat
第二個段為每次執行的dev I/O資訊,這裡因為只執行一次,並有兩個裝置dev252-0與dev252-16:
tps:每秒從物理磁碟I/O的次數.多個邏輯請求會被合併為一個I/O磁碟請求,一次傳輸的大小是不確定的.
rd_sec/s:每秒讀扇區數
wr_sec/s:每秒寫扇區數
avgrq-sz:平均每次裝置I/O操作的資料大小 (扇區)
avgqu-sz:平均I/O佇列長度
await:為平均每次裝置I/O操作的等待時間(單位ms),包括請求在佇列中的等待時間和服務時間
svctm:為平均每次裝置I/O操作的服務時間(單位ms)
%util:表示一秒中有百分之幾的時間用於I/O操作
如果svctm的值與await很接近,表示幾乎沒有I/O等待,磁碟效能很好,如果await的值遠高於svctm的值,則表示I/O佇列等待太長,系統上執行的應用程式將變慢。
如果%util接近100%,表示磁碟產生的I/O請求太多,I/O系統已經滿負荷的在工作,該磁碟請求飽和,可能存在瓶頸。idle小於70% I/O壓力就較大了,也就是有較多的I/O。引用[1]
同時可以結合vmstat 檢視b引數(等待資源的程序數)和wa引數(IO等待所佔用的CPU時間的百分比,高過30%時IO壓力高)。引用[1]
- 分析
表示系統磁碟空間正常,主要有以下規則:
- I/O等待的請求比例 <= 20%
- 提高命中率的一個簡單方式就是增大檔案快取區面積,快取區越大預存的頁面就越多,命中率也越高。
- Linux 核心希望能儘可能產生次缺頁中斷(從檔案快取區讀),並且能儘可能避免主缺頁中斷(從硬碟讀),這樣隨著次缺頁中斷的增多,檔案快取區也逐步增大,直到系統只有少量可用實體記憶體的時候 Linux 才開始釋放一些不用的頁。引用[1]


網路I/O
說明
如果伺服器網路連線過多,那麼會造成大量的資料包在緩衝區長時間得不到處理,一旦緩衝區不足,便會造成資料包丟失問題,對於TCP,資料包丟失便會進行重傳,這有會導致大量的重傳;對於UDP,資料包丟失不會進行重傳,那麼資料便會丟失。因此,伺服器的網路連線不宜過多,需要進行監控。
伺服器一般接收UDP與TCP請求,都是無狀態連線,TCP(傳輸控制協議)是一種提供可靠的資料傳輸協議,UDP(使用者資料報協議)是一種面向無連線的協議,即其傳輸簡單但不可靠。關於它們二者之間的區別,可以查閱相關資料。檢視命令
netstat
- UDP
(1)netstat -ludp | grep udp
Proto:協議名
Recv-Q:收到的請求個數
Send-Q:傳送的請求個數
Local Address:本地地址與埠
Foreign Address:遠端地址與埠
State:狀態
PID/Program name:程序ID與程序名
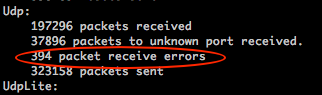
(2) 進一步檢視UDP接收的資料包情況netstat -su
畫圈的便是UDP資料包丟失統計,該項值增加了,說明存在udp資料包丟失,即網絡卡收到了,但是應用層沒有來得及處理而造成的丟包。 - TCP
(1)netstat
各欄位含義同UDP
(2) 檢視重傳率
因為TCP是可靠傳輸協議,如果資料包丟失會進行重傳,因此TCP需要檢視其重傳率.
cat /proc/net/snmp | grep Tcp
那麼重傳率為RetransSegs/OutSegs
- UDP
- 分析
UDP丟包率或者TCP重傳率不能高於多少,這兩個值由系統開發定義,此處,拍腦袋決定UDP包丟包率與TCP包重傳率不能超過1%/s。



連線數
- 說明
對於每一臺伺服器,都應該限制同時連線數,但是這個閾值又不好確定,因此當監測到系統負載過重時,然後取其連線數,這個值便可作為參考值。 - 命令
- netstat
netstat -na | sed -n '3,$p' |awk '{print $5}' | grep -v 127\.0\.0\.1 | grep -v 0\.0\.0\.0 | wc -l
- netstat
- 分析
- 系統負載過重時,該值作為伺服器的峰值參考值。
- 如果超過1024報警

檔案控制代碼數
- 說明
檔案控制代碼數即當前開啟的檔案數,對於linux,系統預設支援的最大控制代碼數是1024,當然每個系統可以不一樣,也可以修改,最大不能超過無符號整型最大值(65535),可以使用ulimit -n命令進行檢視,即因此如果同時開啟的檔案數超過這個數便會發生異常。因此這個指標也需要進行監控。 - 檢視命令
- lsof
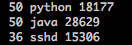
lsof -n | awk '{print $1,$2}' | sort | uniq -c | sort -nr
三列分別是開啟的檔案控制代碼數, 程序名,程序號
- lsof
- 分析
將所有的行的第一列相加便是系統目前開啟的檔案控制代碼數num,如果num<=max_num*85%則報警。
效能指標總結
- CPU
- CPU利用率:us <= 70,sy <= 35,us + sy <= 70。
- 上下文切換:與CPU利用率相關聯,如果CPU利用率狀態良好,大量的上下文切換也是可以接受的。
- 可執行佇列:每個處理器的可執行佇列<=3個執行緒。
- Memory
- swap in (si) == 0,swap out (so) == 0
- 可用記憶體/實體記憶體 >= 30%
- Disk
- Use% <= 90%
- Disk I/O
- I/O等待的請求比例 <= 20%
- Network I/O
- UDP包丟包率與TCP包重傳率不能超過1%/s。
- Connect Num
- <= 1024
- File Handle Num
- num/max_num <= 90%
總結
指令碼檢測nginx、tomcat與webapp執行異常日誌(包括nginx與tomcat是否正在執行)與伺服器效能七個指標,一旦發現異常資訊和效能超標,那麼馬上傳送郵件給管理員,也可以使用雲監控push給管理員的雲賬號。