python3.5《機器學習實戰》學習筆記(三):k近鄰演算法scikit-learn實戰手寫體識別
轉載請註明作者和出處:http://blog.csdn.net/u013829973
系統版本:window 7 (64bit)
我的GitHub:https://github.com/weepon
python版本:python 3.5
IDE:Spyder (一個比較方便的辦法是安裝anaconda,那麼Spyder和jupyter以及python幾個常用的包都有了,甚至可以方便的安裝TensorFlow等,安裝方法連結)
在前面學習筆記(一)、(二)我們主要介紹了k近鄰的基本原理及一步步實現,但是實際上用的時候,不用自己從頭編寫,我們只要使用scikit-learn中的k近鄰函式就可以了,看下圖的各種knn演算法實現:

要想實現上篇文章中手寫體數字識別,只需呼叫KNeighborsClassifier函式,再指定相應引數就可以了
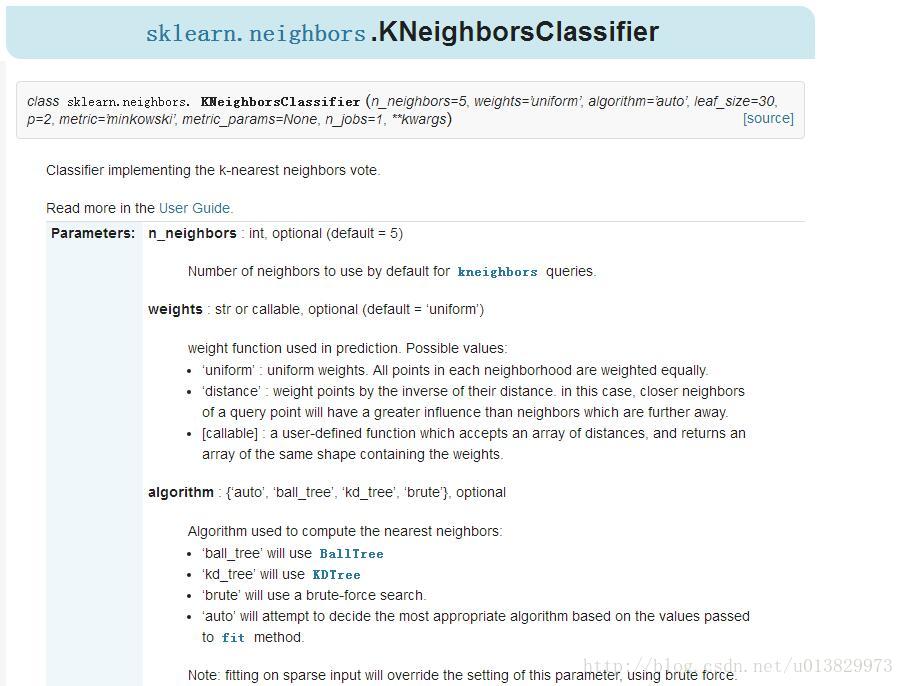
各種引數:
n_neighbors:預設為5,kNN的k的值。
weights:預設是uniform。uniform是均等的權重,就說所有的鄰近點的權重都是相等的。distance是不均等的權重,距離近的點比距離遠的點的影響大。使用者自定義的函式,接收距離的陣列,返回一組維數相同的權重。
algorithm:快速k近鄰搜尋演算法,預設引數為auto。使用者可以指定搜尋演算法ball_tree、kd_tree、brute方法進行搜尋,brute是蠻力搜尋,也就是線性掃描,當訓練集很大時,計算非常耗時。kd_tree,構造kd樹儲存資料以便對其進行快速檢索的樹形資料結構,kd樹也就是資料結構中的二叉樹。以中值切分構造的樹,每個結點是一個超矩形,在維數小於20時效率高。ball tree是為了克服kd樹高緯失效而發明的,其構造過程是以質心C和半徑r分割樣本空間,每個節點是一個超球體。
leaf_size:預設是30,這個是構造的kd樹和ball樹的大小。這個值的設定會影響樹構建的速度和搜尋速度,同樣也影響著儲存樹所需的記憶體大小。需要根據問題的性質選擇最優的大小。
metric:用於樹的距離度量。預設的度量是閔可夫斯基度量,p = 2等價於標準的歐幾里得度量。
p:距離度量選擇。除了歐式距離,還有曼哈頓距離等這個引數預設為2,也就是預設使用歐式距離公式進行距離度量。也可以設定為1,使用曼哈頓距離公式進行距離度量。
metric_params:距離公式的其他關鍵引數,預設None。
- n_jobs:並行處理設定。預設為1,臨近點搜尋並行工作數。如果為-1,那麼CPU的所有cores都用於並行工作。
手寫題數字識別的完整python程式碼:
'''
Created on Sep 10, 2017
kNN: k近鄰(k Nearest Neighbors)
實戰:手寫識別系統
author:weepon
'''
import numpy as np
import operator
from os import listdir
from sklearn.neighbors import KNeighborsClassifier
'''
函式功能:將32x32的二進位制影象轉換為1x1024向量
Input: filename :檔名
Output: 二進位制影象的1x1024向量
'''
def img2vector(filename):
returnVect = np.zeros((1,1024)) #建立空numpy陣列
fr = open(filename) #開啟檔案
for i in range(32):
lineStr = fr.readline() #讀取每一行內容
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])#將每行前32個字元值儲存在numpy陣列中
return returnVect
'''
函式功能:手寫數字分類測試
'''
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits') #載入訓練集
m = len(trainingFileList) #計算資料夾下檔案的個數,因為每一個檔案是一個手寫體數字
trainingMat = np.zeros((m,1024)) #初始化訓練向量矩陣
for i in range(m):
fileNameStr = trainingFileList[i] #獲取檔名
fileStr = fileNameStr.split('.')[0] #從檔名中解析出分類的數字
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
#構建kNN分類器
neigh = KNeighborsClassifier(n_neighbors = 3, algorithm = 'auto')
#擬合模型, trainingMat為測試矩陣,hwLabels為對應的標籤
neigh.fit(trainingMat, hwLabels)
testFileList = listdir('testDigits') #載入測試集
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] #從檔名中解析出測試樣本的類別
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = neigh.predict(vectorUnderTest) #開始分類
print ('the classifier came back with: %d, the real answer is: %d' % (classifierResult, classNumStr))
if (classifierResult != classNumStr): errorCount += 1.0 #計算分錯的樣本數
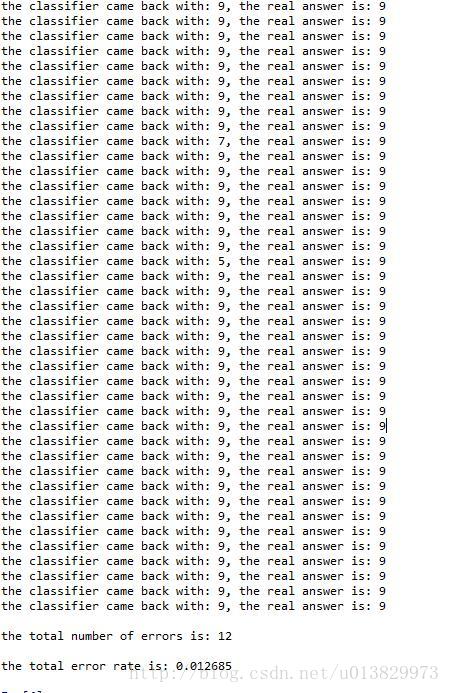
print ('\nthe total number of errors is: %d' % errorCount)
print ('\nthe total error rate is: %f' % (errorCount/float(mTest)))
'''
主函式
'''
if __name__ == '__main__':
handwritingClassTest()
執行結果: