機器學習筆記(七):K-Means
1 - 前言
之前我們學習的演算法均為監督學習演算法,而K-means是我們所學習的第一個無監督學習演算法。所以首先讓我們瞭解一下監督學習和無監督學習的區別
1.1 - 監督學習(supervised learning)
從給定的訓練資料集中學習出一個函式(模型引數),當新的資料到來時,可以根據這個函式預測結果。
監督學習的訓練集要求包括輸入輸出,也可以說是特徵和目標。訓練集中的目標是由人標註的。
監督學習就是最常見的分類(注意和聚類區分)問題,通過已有的訓練樣本(即已知資料及其對應的輸出)去訓練得到一個最優模型(這個模型屬於某個函式的集合,最優表示某個評價準則下是最佳的),再利用這個模型將所有的輸入對映為相應的輸出,對輸出進行簡單的判斷從而實現分類的目的。也就具有了對未知資料分類的能力。
監督學習的目標往往是讓計算機去學習我們已經建立好的分類系統(模型)。
1.2 - 無監督學習(unsupervised learning)
輸入資料沒有被標記,也沒有確定的結果。樣本資料類別未知,需要根據樣本間的相似性對樣本集進行分類(聚類,clustering)試圖使類內差距最小化,類間差距最大化。通俗點將就是實際應用中,不少情況下無法預先知道樣本的標籤,也就是說沒有訓練樣本對應的類別,因而只能從原先沒有樣本標籤的樣本集開始學習分類器設計。
非監督學習目標不是告訴計算機怎麼做,而是讓它(計算機)自己去學習怎樣做事情。非監督學習有兩種思路。第一種思路是在指導Agent時不為其指定明確分類,而是在成功時,採用某種形式的激勵制度。需要注意的是,這類訓練通常會置於決策問題的框架裡,因為它的目標不是為了產生一個分類系統,而是做出最大回報的決定,這種思路很好的概括了現實世界,agent可以對正確的行為做出激勵,而對錯誤行為做出懲罰。
1.3 - 監督學習和無監督學習的區別
-
有監督學習方法必須要有訓練集與測試樣本。在訓練集中找規律,而對測試樣本使用這種規律。而非監督學習沒有訓練集,只有一組資料,在該組資料集內尋找規律。
-
有監督學習的方法就是識別事物,識別的結果表現在給待識別資料加上了標籤。因此訓練樣本集必須由帶標籤的樣本組成。而非監督學習方法只有要分析的資料集的本身,預先沒有什麼標籤。如果發現數據集呈現某種聚集性,則可按自然的聚集性分類,但不予以某種預先分類標籤對上號為目的。
-
非監督學習方法在尋找資料集中的規律性,這種規律性並不一定要達到劃分資料集的目的,也就是說不一定要“分類”。
這一點是比有監督學習方法的用途要廣。
譬如分析一堆資料的主分量,或分析資料集有什麼特點都可以歸於非監督學習方法的範疇。 -
用非監督學習方法分析資料集的主分量與用K-L變換計算資料集的主分量又有區別。後者從方法上講不是學習方法。因此用K-L變換找主分量不屬於無監督學習方法,即方法上不是。而通過學習逐漸找到規律性這體現了學習方法這一點。在人工神經元網路中尋找主分量的方法屬於無監督學習方法。
2 - K-Means演算法簡介
K-means是機器學習中一個比較常用的演算法,屬於無監督學習演算法,其常被用於資料的聚類,只需為它指定簇的數量即可自動將資料聚合到多類中,相同簇中的資料相似度較高,不同簇中資料相似度較低。
3 - K-menas的優缺點:
優點:
-
原理簡單
-
速度快
-
對大資料集有比較好的伸縮性
缺點:
-
需要指定聚類 數量K
-
對異常值敏感
-
對初始值敏感
4 - K-means的聚類過程:
-
隨機選取k個聚類質心點(cluster centroids)為
-
重複下面過程直到收斂
對於每個樣例 ,計算其應該屬於的類
-
對於每一個類j,重新計算該類的質心
-
對於所有的c個聚類中心,如果利用(2)(3)的迭代法更新後,值保持不變,則迭代結束,否則繼續迭代。
聚類過程的圖解:
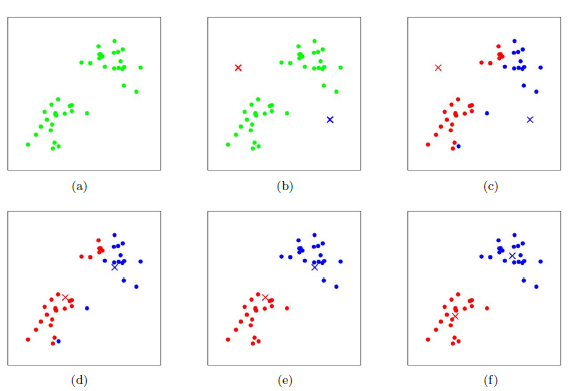
該演算法的最大優勢在於簡潔和快速。演算法的關鍵在於初始中心的選擇和距離公式。
5 - Python實現K-means演算法
import numpy
import random
import matplotlib.pyplot as plt
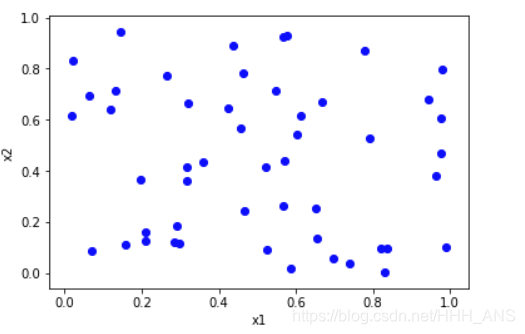
#隨機生成50個需要聚類的資料
numpy.random.seed(0)
a=numpy.random.random((50,2))
#視覺化資料集
for i in range(50):
plt.scatter(a[i][0], a[i][1],color='blue')
print("需要類聚的資料集為:\n",a)
plt.xlabel("x1")
plt.ylabel("x2")
plt.show()
def findCentroids(data_get, k): # 隨機獲取k個質心
return random.sample(data_get, k)
def calculateDistance(vecA, vecB): # 計算向量vecA和向量vecB之間的歐氏距離
return numpy.sqrt(numpy.sum(numpy.square(vecA - vecB)))
def minDistance(data_get, centroidList):
# 計算data_get中的元素與centroidList中k個聚類中心的歐式距離,找出距離最小的
# 將該元素加入相應的聚類中
clusterDict = dict() # 用字典儲存聚類結果
for element in data_get:
vecA = numpy.array(element) # 轉換成陣列形式
flag = 0 # 元素分類標記,記錄與相應聚類距離最近的那個類
minDis = float("inf") # 初始化為最大值
for i in range(len(centroidList)):
vecB = numpy.array(centroidList[i])
distance = calculateDistance(vecA, vecB) # 兩向量間的歐式距離
if distance < minDis:
minDis = distance
flag = i # 儲存與當前item距離最近的那個聚類的標記
if flag not in clusterDict.keys(): # 簇標記不存在,進行初始化
clusterDict[flag] = list()
clusterDict[flag].append(element) # 加入相應的類中
return clusterDict # 返回新的聚類結果
def getCentroids(clusterDict):
centroidList = list()
for key in clusterDict.keys():
centroid = numpy.mean(numpy.array(clusterDict[key]), axis=0) # 求聚類中心即求解每列的均值
centroidList.append(centroid)
return numpy.array(centroidList).tolist()
def calculate_Var(clusterDict, centroidList):
# 計算聚類間的均方誤差
# 將類中各個向量與聚類中心的距離進行累加求和
sum = 0.0
for key in clusterDict.keys():
vecA = numpy.array(centroidList[key])
distance = 0.0
for item in clusterDict[key]:
vecB = numpy.array(item)
distance += calculateDistance(vecA, vecB)
sum += distance
return sum
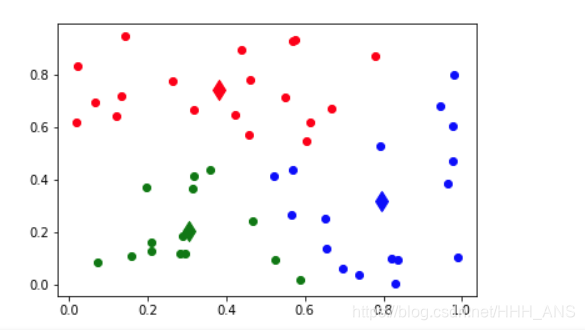
def showCluster(centroidList, clusterDict):
# 畫聚類結果
colorMark = ['or', 'ob', 'og', 'ok', 'oy', 'ow'] # 元素標記
centroidMark = ['dr', 'db', 'dg', 'dk', 'dy', 'dw'] # 聚類中心標記
for key in clusterDict.keys():
plt.plot(centroidList[key][0], centroidList[key][1], centroidMark[key], markersize=12) # 畫聚類中心
for item in clusterDict[key]:
plt.plot(item[0], item[1], colorMark[key]) # 畫類下的點
plt.show()
data = [[0.5488135 , 0.71518937],
[0.60276338, 0.54488318],
[0.4236548 , 0.64589411],
[0.43758721, 0.891773 ],
[0.96366276, 0.38344152],
[0.79172504, 0.52889492],
[0.56804456, 0.92559664],
[0.07103606, 0.0871293 ],
[0.0202184 , 0.83261985],
[0.77815675, 0.87001215],
[0.97861834, 0.79915856],
[0.46147936, 0.78052918],
[0.11827443, 0.63992102],
[0.14335329, 0.94466892],
[0.52184832, 0.41466194],
[0.26455561, 0.77423369],
[0.45615033, 0.56843395],
[0.0187898 , 0.6176355 ],
[0.61209572, 0.616934 ],
[0.94374808, 0.6818203 ],
[0.3595079 , 0.43703195],
[0.6976312 , 0.06022547],
[0.66676672, 0.67063787],
[0.21038256, 0.1289263 ],
[0.31542835, 0.36371077],
[0.57019677, 0.43860151],
[0.98837384, 0.10204481],
[0.20887676, 0.16130952],
[0.65310833, 0.2532916 ],
[0.46631077, 0.24442559],
[0.15896958, 0.11037514],
[0.65632959, 0.13818295],
[0.19658236, 0.36872517],
[0.82099323, 0.09710128],
[0.83794491, 0.09609841],
[0.97645947, 0.4686512 ],
[0.97676109, 0.60484552],
[0.73926358, 0.03918779],
[0.28280696, 0.12019656],
[0.2961402 , 0.11872772],
[0.31798318, 0.41426299],
[0.0641475 , 0.69247212],
[0.56660145, 0.26538949],
[0.52324805, 0.09394051],
[0.5759465 , 0.9292962 ],
[0.31856895, 0.66741038],
[0.13179786, 0.7163272 ],
[0.28940609, 0.18319136],
[0.58651293, 0.02010755],
[0.82894003, 0.00469548]]
if __name__ == '__main__':
centroidList = findCentroids(data, 3) # 隨機獲取3個聚類中心
clusterDict = minDistance(data, centroidList) # 第一次聚類迭代
newVar = calculate_Var(clusterDict, centroidList) # 計算均方誤差值,通過新舊均方誤差來獲得迭代終止條件
oldVar = -0.0001 # 初始化均方誤差
print('***** 第1次迭代 *****')
for key in clusterDict.keys():
print('聚類中心: ', centroidList[key])
print('對應聚類: ',clusterDict[key])
print('平均均方誤差: ', newVar)
showCluster(centroidList, clusterDict) # 展示聚類結果
k = 2
while abs(newVar - oldVar) >= 0.0001: # 當連續兩次聚類結果差距小於0.0001時,迭代結束
centroidList = getCentroids(clusterDict) # 獲得新的聚類中心
clusterDict = minDistance(data, centroidList) # 新的聚類結果
oldVar = newVar
newVar = calculate_Var(clusterDict, centroidList)
print('***** 第%d次迭代 *****' % k)
for key in clusterDict.keys():
print('聚類中心: ', centroidList[key])
print('對應聚類: ', clusterDict[key])
print('平均均方誤差: ', newVar)
showCluster(centroidList, clusterDict) # 展示聚類結果
k += 1