
Spark MLlib系列(一):入門介紹
阿新 • • 發佈:2019-01-03
轉載:http://blog.csdn.net/shifenglov/article/details/43762705
前言 最新的情況是國內BAT已經都上了spark,而且spark在hadoop上的應用,大有為大象插上翅膀的效果。個人估計在未來兩到三年,spark大有代替hadoop的mapreduce的趨勢。應該說spark的在使用上面的經濟成本,效能優勢,一站式解決能力,一定會使其大放異彩。 因為個人對spark很感興趣,加上專案中需要使用它解決一些機器學習的問題,在網上搜集資料時發現,spark machine learning這塊的資料確實太缺少了,所以決定寫一spark machine learning的一系列部落格(只涉及機器學習部分)。目前考慮是,這個系列,先講一些入門的知識,然後是一些真正的實戰應用,可能涉及到推薦,聚類,分類等問題,理論涉及不會太多,分享一些接地氣的乾貨,讓大家能夠真正感受到spark machine learning的魅力。 為什麼使用MLlib
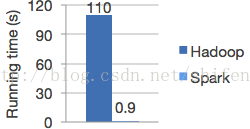
- Speed.Spark has an advanced DAG execution engine that supports cyclic data flow and in-memory computing. Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
- Ease of Use .Write applications quickly in Java, Scala or Python.
- Generality.Combine SQL, streaming, and complex analytics.
- Runs Everywhere.Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, S3.
Logistic regression in Hadoop and Spark 概述
MLlib 是Spark的可以擴充套件的機器學習庫,由以下部分組成:通用的學習演算法 和工具類,包括分類,迴歸,聚類,協同過濾,降維,當然也包括調優的部分
-
- summary statistics 概括統計
- correlations 相關性
- stratified sampling 分層取樣
- hypothesis testing 假設檢驗
- random data generation 隨機數生成
-
- alternating least squares (ALS) (交替最小二乘法(ALS) )
-
- singular value decomposition (SVD) 奇異值分解
- principal component analysis (PCA) 主成分分析
- 優化部分
- stochastic gradient descent 隨機梯度下降
- limited-memory BFGS (L-BFGS) 短時記憶的BFGS (擬牛頓法中的一種,解決非線性問題)
Experimental/DeveloperApi 在未來的釋出種可能會被修改
依賴
MLlib使用了線性代數包 Breeze,
它依賴於netlib-java和jblas。netlib-java
和 jblas 需要依賴native Fortran routines。所以你需要安裝gfortran runtime library (安裝方法在這個連結中),如果你的叢集的節點中沒有安裝native
Fortran routines。MLlib 會丟擲一個link error,如果沒有安裝native Fortran routines。
如果你需要使用spark的python開發,你需要NumPyversion
1.4或以上版本.
當前最近版本1.2
個人認為當前1.2版本的最大的改進應該是釋出了稱為spark.ml的機器學習工具包,支援了pipeline的學習模式,即多個演算法可以用不同引數以流水線的形式執行。在工業界的機器學習應用部署過程中,pipeline的工作模式是很常見的。新的ML工具包使用Spark的SchemaRDD來表示機器學習的資料集合,提供了Spark
SQL直接訪問的介面。此外,在機器學習的演算法方面,增加了兩個基於樹的方法,隨機森林和梯度增強樹。還有貌似效能上有優化,看過一篇DataBricks的ppt,據說1.2版本的演算法在效能上比1.1版本平均快了3倍