
深度學習之視訊人臉識別系列一:介紹
作者 | 東田應子
【導讀】本文是深度學習之視訊人臉識別系列的第一篇文章,介紹了人臉識別領域的一些基本概念,分析了深度學習在人臉識別的基本流程,並總結了近年來科研領域的研究進展,最後分析了靜態資料與視訊動態資料在人臉識別技術上的差異。
一、基本概念
人臉識別是1對n的比對,給定一張人臉圖片,如何在n張人臉圖片中找到同一張人臉圖片,相對於一個分類問題,將一張人臉劃分到n張人臉中的一張。類似於管理人員進行的人臉識別門禁系統。
2.人臉驗證(face verification)
人臉驗證的1對1的比對,給定兩張人臉圖片,判斷這兩張人臉是否為同一人,類似於手機的人臉解鎖系統,事先在手機在錄入自己的臉部資訊,然後在開鎖時比對攝像頭捕捉到的人臉是否與手機上錄入的人臉為同一個人。
人臉檢測是在一張圖片中把人臉檢測出來,即在圖片上把人臉用矩形框出來,並得到矩形的座標,如下圖所示。

、
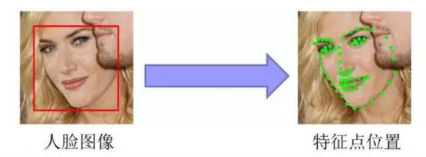
4.人臉關鍵點檢測
根據輸入的人臉影象,識別出面部關鍵特徵點,如眼睛、鼻尖、嘴角點、眉毛以及人臉各部件輪廓點的座標,如下圖所示。
5.人臉矯正(人臉對齊)
通過人臉關鍵點檢測得到人臉的關鍵點座標,然後根據人臉的關鍵點座標調整人臉的角度,使人臉對齊,由於輸入影象的尺寸是大小不一的,人臉區域大小也不相同,角度不一樣,所以要通過座標變換,對人臉影象進行歸一化操作,如下圖所示。

二、基於深度學習的人臉識別演算法基本流程
隨著神經網路的迅速發展和其對影象資料的強大的特徵提取,深度學習運用於人臉識別也成為熱點研究方向;2014年的開山之作DeepFace,第一個真正將大資料和深度學習結合應用於人臉識別與驗證,確立人臉識別的常規流程:圖片->人臉與關鍵點檢測->人臉對齊->人臉表徵(representation)->分類。首先將圖片中的人臉檢測處理並通過關鍵點進行對齊,如何輸入到神經網路,得到特徵向量,通過分類訓練過程,該向量即為人臉的特徵向量。要求出兩張人臉的相似度即計算兩個特徵的向量度量之差,方法包括:SVM、SiameseNetwork、JointBayesian、L1距離、L2距離、cos距離等。
三、科研領域近期進展
科研領域近期進展主要集中於loss函式的研究,包括DeepId2(Contrastive Loss)、FaceNet(Triplet loss)、L-Softmax、SphereFace(A-Softmax)、Center Loss、L2-Softmax、NormFace、CosFace(AM-Softmax)、ArcFace(AA-Softmax)等。
四、基於視訊人臉識別和圖片人臉識別的區別(該小結部分參考於部落格園 - 米羅西)
相對於圖片資料,目前視訊人臉識別有很多挑戰,包括:(1)視訊資料一般為戶外,視訊影象質量比較差;(2)人臉影象比較小且模糊;(3)視訊人臉識別對實時性要求更高。
但是視訊資料也有一些優越性,視訊資料同時具有空間資訊和時間資訊,在時間和空間的聯合空間中描述人臉和識別人臉會具有一定提升空間。在視訊資料中人臉跟蹤是一個提高識別的方法,首先檢測出人臉,然後跟蹤人臉特徵隨時間的變化。當捕捉到一幀比較好的影象時,再使用圖片人臉識別演算法進行識別。這類方法中跟蹤和識別是單獨進行的,時間資訊只在跟蹤階段用到。
【總結】:本期文章主要介紹了基於深度學習的人臉識別演算法的一些基本入門知識,下一期我給大家介紹人臉識別中獲取神經網路輸入的演算法,即關於人臉檢測、人臉關鍵點檢測與人臉對齊的一些重要演算法和相關論文解析。
人臉矯正(人臉對齊)
通過人臉關鍵點檢測得到人臉的關鍵點座標,然後根據人臉的關鍵點座標調整人臉的角度,使人臉對齊,由於輸入影象的尺寸是大小不一的,人臉區域大小也不相同,角度不一樣,所以要通過座標變換,對人臉影象進行歸一化操作,如下圖所示。