
機器學習3 邏輯斯提回歸和梯度下降演算法
引言
上節我們介紹了很多線性迴歸模型,如何用線性模型做分類任務呢?是不是可以將線性迴歸模型的預測值和到分類任務的標記聯絡起來呢?
邏輯斯提回歸
對於一個二分類任務,輸出標記y為{0,1},而線性迴歸模型產生的預測值z為全體實數,我們想把z轉換成0/1值。我們首先想到是“單位階躍函式”。
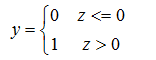
利用線性迴歸模型產生預測值z,經過單位階躍函式做變換,如果z<=0,就歸為負類,若z>0就歸為正類。但單位階躍函式性質不好,不連續。我們用對數機率函式(也叫sigmoid函式)進行替代:
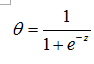
函式影象為:
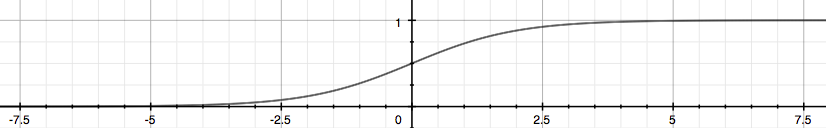
這樣就將預測值z對映到(0,1)之前,那麼怎麼進行分類呢?同樣是:如果z<=0,就歸為負類,若z>0就歸為正類。對映到(0,1)還有一個好處是,可以看成近似的概率。例如y=0.8,就說它歸為正類的概率為0.8。
上一節講到我們的線性模型為;
![]()
將偏置項和權重係數合併:
![]()
其中:![]()
代入到對數機率函式中:

下標sigmoid,表示對映函式為sigmoid函式。這就是邏輯斯提回歸模型。
那麼我們如何求解引數W呢?
由對數函式的性質可知:
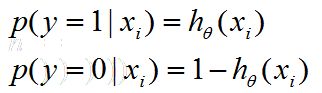
上式即為在已知樣本x和引數θ的情況下,樣本x屬性正樣本(y=1)和負樣本(y=0)的條件概率。理想狀態下,根據上述公式,求出各個點的概率均為1,也就是完全分類都正確。但是考慮到實際情況,樣本點的概率越接近於1,其分類效果越好。比如一個樣本屬於正樣本的概率為0.51,那麼我們就可以說明這個樣本屬於正樣本。另一個樣本屬於正樣本的概率為0.99,那麼我們也可以說明這個樣本屬於正樣本。但是顯然,第二個樣本概率更高,更具說服力。我們可以把上述兩個概率公式合二為一:
![]()
合併出來的Cost,我們稱之為代價函式(Cost Function)。當y等於1時,(1-y)項(第二項)為0;當y等於0時,y項(第一項)為0。為了簡化問題,我們對整個表示式求對數,(將指數問題對數化是處理數學問題常見的方法):
![]()
這個代價函式,是對於一個樣本而言的。給定一個樣本,我們就可以通過這個代價函式求出,樣本所屬類別的概率,而這個概率越大越好,所以也就是求解這個代價函式的最大值。既然概率出來了,那麼最大似然估計也該出場了。假定樣本與樣本之間相互獨立,那麼整個樣本集生成的概率即為所有樣本生成概率的乘積,再將公式對數化,便可得到如下公式:

其中,m為樣本的總數,y(i)表示第i個樣本的類別,x(i)表示第i個樣本,需要注意的是W是多維向量,x(i)也是多維向量。
接下來的問題是求解W使得上式最小、
通過一連串的分析,可以看出一個機器學習演算法其實只有兩部分
- 模型從輸入特徵x預測輸入y的那個函式h(x)
- 目標函式 目標函式取最小(最大)值時所對應的引數值,就是模型的引數的最優值。很多時候我們只能獲得目標函式的區域性最小(最大)值,因此也只能得到模型引數的區域性最優值。
梯度下降演算法
上節介紹的線性迴歸模型,能夠通過閉式方程直接算出最適合訓練集的模型引數。這裡我們介紹另一種方法:梯度下降,通過迭代優化,逐漸調整模型引數直至到達理想的情況。這裡介紹梯度下降和變體隨機梯度下降。
我們先看個簡單的求極小值的例子。
![]()
來吧,做到送分題。這個函式的極值怎麼求?它的函式影象為:

求導數,令其為0,解出x即可。
但是實際任務的函式不會像上面這麼簡單,就算求出了函式的導數,也很難精確計算出函式的極值。此時我們就可以用迭代的方法來做。就像爬坡一樣,一點一點逼近極值。這種尋找最佳擬合引數的方法,就是最優化演算法。爬坡這個動作用數學公式表達即為:
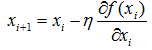
對我們的函式而言就是:
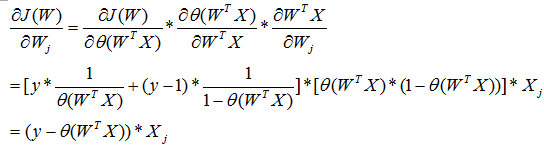
迭代公式為:
![]()
其中n為學習率,學習率越高,邁的步子越大。
當梯度為0或到達一定迭代次數後,演算法就會停止。
梯度下降演算法有個問題,可能只會到達區域性最優,而不是全域性最優。

演算法到達B點就會停止,不會找到最優解C 。
隨機梯度下降
梯度下降演算法每次更新權重時都需要遍歷整個資料集,這樣在資料集很大時使得計算複雜度太高,改進方法是一次僅用一個樣本點更新權重係數,這就叫隨機梯度下降演算法。因此每次採用一個樣本,它比梯度下降不穩定,不斷的上上下下,但整體看,還是慢慢下降,最終接近最小值。因為它不穩定也帶來了一個優點:能跳出區域性最優。
在sklearn中,可以使用SGDRegressor來實現迴歸任務的隨機梯度下降。
以上節線性迴歸為例,使用隨機梯度下降:

引數:
loss:損失函式,預設為平方誤差,可選項:‘squared_loss’, ‘huber’, ‘epsilon_insensitive’, or ‘squared_epsilon_insensitive’
‘squared_loss’:平方誤差
“huber”:修正了“squared_loss”,通過從平方轉換到基於epsilon距離的線性損失,減少了對異常值的校正。
epsilon_insensitive:epsilon_insensitive’ 忽略小於 epsilon的誤差。使用的是SVR的損失函式。
'squared_epsilon_insensitive:上面的平方損失
penalty:懲罰項,可選項:‘none’, ‘l2’, ‘l1’, or ‘elasticnet’
alpha:常數乘以正則化項。預設值為0.0001,當設定為“最優”時,也用於計算learning_rate。不常用。
l1_ratio:elasticnet彈性網路中l1正則項的程度
fit_intercept:偏置項
max_iter:最大迭代次數
tol:容忍誤差
shuffle:訓練資料是否應該在每個epochs之後重新洗牌。預設值為True。
verbose:不常用
epsilon:只有當huber’, ‘epsilon_insensitive’, or ‘squared_epsilon_insensitive’時可用,對於“huber”來說,它決定了一個閾值,在這個閾值內,不必準確預測。對於epsilon_insensitive’,如果當前的預測與正確的標記之間的差異小於這個閾值,則忽略它們。
random_state:種子生成器
learning_rate;學習率,可選‘constant’,‘optimal’:invscaling’,‘adaptive’
constant:eta = eta0
‘optimal’:1.0 / (alpha * (t + t0))其中t0由Leon Bottou提出的啟發式演算法選擇。
invscaling:eta0 / pow(t, power_t)
adaptive:自適應改變eta
eta0:學習率,在‘constant’,‘’invscaling’,‘adaptive’下可用
power_t:逆標度學習速率的指數
early_stopping:當驗證分數沒有提高時,是否使用早期停止終止訓練
validation_fraction:訓練集留給驗證集的部分,(0,1)直接,且early_stopping設為True
n_iter_no_change;在early stopping前沒有提高效能的迭代次數
warm_start:是否重新開始
average:當設定為True時,計算SGD的平均權重,並將結果儲存在coef_屬性中
n_iter:迭代次數,將要移除在0.21
可算寫完了,引數較多,很多也不常用。
屬性:

用上節的線性資料為例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import SGDRegressor
'''
建立資料集
'''
#rand(100,1)產生100*1的矩陣,數為0到1的隨機數
X = 2 * np.random.rand(100,1)
#randn(100,1)產生100*1的矩陣,數為正態分佈隨機數
y = 4 + 3*X + np.random.randn(100,1)
lin_reg = LinearRegression()
lin_reg.fit(X,y)
print('線性迴歸',lin_reg.coef_,lin_reg.intercept_)
sgd_reg = SGDRegressor(eta0=0.1,max_iter=500)
sgd_reg.fit(X,y)
print('隨機梯度迴歸',sgd_reg.coef_,sgd_reg.intercept_)結果:
![]()
邏輯斯提回歸實戰
前面我們介紹了邏輯斯提回歸演算法的原理和解法,接下來進行運用。首先還是先介紹超引數:

penalty:懲罰項,可選L1,L1, ‘newton-cg’, ‘sag’ and ‘lbfgs’ solvers 只支援 l2
dual:對偶僅適用於用''liblinear''solvers 的L2。當樣本數大於特徵數預設False
tol:容忍誤差
C:正則化程度,C越小,正則化程度越大
- fit_intercept:是否存在截距或偏差,bool型別,預設為True。
- intercept_scaling:僅在solver為"liblinear",且fit_intercept設定為True時有用。float型別,預設為1。
- class_weight:用於標示分類模型中各種型別的權重,可以是一個字典或者'balanced'字串,預設為不輸入,也就是不考慮權重,即為None。如果選擇輸入的話,可以選擇balanced讓類庫自己計算型別權重,或者自己輸入各個型別的權重。舉個例子,比如對於0,1的二元模型,我們可以定義class_weight={0:0.9,1:0.1},這樣型別0的權重為90%,而型別1的權重為10%。如果class_weight選擇balanced,那麼類庫會根據訓練樣本量來計算權重。某種型別樣本量越多,則權重越低,樣本量越少,則權重越高。當class_weight為balanced時,類權重計算方法如下:n_samples / (n_classes * np.bincount(y))。n_samples為樣本數,n_classes為類別數量,np.bincount(y)會輸出每個類的樣本數,例如y=[1,0,0,1,1],則np.bincount(y)=[2,3]。
- 那麼class_weight有什麼作用呢?
- 在分類模型中,我們經常會遇到兩類問題:
- 1.第一種是誤分類的代價很高。比如對合法使用者和非法使用者進行分類,將非法使用者分類為合法使用者的代價很高,我們寧願將合法使用者分類為非法使用者,這時可以人工再甄別,但是卻不願將非法使用者分類為合法使用者。這時,我們可以適當提高非法使用者的權重。
- 2. 第二種是樣本是高度失衡的,比如我們有合法使用者和非法使用者的二元樣本資料10000條,裡面合法使用者有9995條,非法使用者只有5條,如果我們不考慮權重,則我們可以將所有的測試集都預測為合法使用者,這樣預測準確率理論上有99.95%,但是卻沒有任何意義。這時,我們可以選擇balanced,讓類庫自動提高非法使用者樣本的權重。提高了某種分類的權重,相比不考慮權重,會有更多的樣本分類劃分到高權重的類別,從而可以解決上面兩類問題。
- 那麼class_weight有什麼作用呢?
- random_state:隨機數種子,僅solver為sag,liblinear時有用。
- solver:優化演算法選擇引數,只有五個可選引數,即newton-cg,lbfgs,liblinear,sag,saga。預設為liblinear。solver引數決定了我們對邏輯迴歸損失函式的優化方法,有四種演算法可以選擇,分別是:
- liblinear:使用了開源的liblinear庫實現,內部使用了座標軸下降法來迭代優化損失函式。
- lbfgs:擬牛頓法的一種,利用損失函式二階導數矩陣即海森矩陣來迭代優化損失函式。
- newton-cg:也是牛頓法家族的一種,利用損失函式二階導數矩陣即海森矩陣來迭代優化損失函式。
- sag:隨機平均梯度下降。
- saga:線性收斂的隨機優化演算法的的變種。
- 總結:
- liblinear適用於小資料集,而sag和saga適用於大資料集因為速度更快。
- 對於多分類問題,只有newton-cg,sag,saga和lbfgs能夠處理多項損失,而liblinear受限於一對剩餘(OvR)。啥意思,就是用liblinear的時候,如果是多分類問題,得先把一種類別作為一個類別,剩餘的所有類別作為另外一個類別。一次類推,遍歷所有類別,進行分類。
- newton-cg,sag和lbfgs這三種優化演算法時都需要損失函式的一階或者二階連續導數,因此不能用於沒有連續導數的L1正則化,只能用於L2正則化。而liblinear和saga通吃L1正則化和L2正則化。
- 同時,sag每次僅僅使用了部分樣本進行梯度迭代,所以當樣本量少的時候不要選擇它,而如果樣本量非常大,比如大於10萬,sag是第一選擇。但是sag不能用於L1正則化,所以當你有大量的樣本,又需要L1正則化的話就要自己做取捨了。要麼通過對樣本取樣來降低樣本量,要麼回到L2正則化。
- 從上面的描述,大家可能覺得,既然newton-cg, lbfgs和sag這麼多限制,如果不是大樣本,我們選擇liblinear不就行了嘛!錯,因為liblinear也有自己的弱點!我們知道,邏輯迴歸有二元邏輯迴歸和多元邏輯迴歸。對於多元邏輯迴歸常見的有one-vs-rest(OvR)和one-vs-one(OvO)兩種。什麼是OvO,舉例,對標記{0,1,2}做分類。OvO的策略為:為每對數字訓練一個二元分類器:一個區分0,1,一個區分0,2,一個區分1,2。這樣每個分類器只需用到所需要的訓練集,更穩定,但訓練時間長。
- OvO一般比OvR分類相對準確一些。鬱悶的是liblinear只支援OvR,不支援OvO,這樣如果我們需要相對精確的多元邏輯迴歸時,就不能選擇liblinear了.
- max_iter:演算法收斂最大迭代次數,預設為100。僅在正則化優化演算法為newton-cg, sag和lbfgs才有用
- multi_class:分類方式選擇引數,str型別,可選引數為ovr和multinomial,預設為ovr。ovr即前面提到的one-vs-rest(OvR),而multinomial即前面提到的one-vs-one(OvO)。如果是二元邏輯迴歸,ovr和multinomial並沒有任何區別,區別主要在多元邏輯迴歸上
- OvR相對簡單,但分類效果相對略差(這裡指大多數樣本分佈情況,某些樣本分佈下OvR可能更好)。而OvO分類相對精確,但是分類速度沒有OvR快。如果選擇了ovr,則4種損失函式的優化方法liblinear,newton-cg,lbfgs和sag都可以選擇。但是如果選擇了multinomial,則只能選擇newton-cg, lbfgs和sag了。
- verbose:日誌冗長度,預設為0。就是不輸出訓練過程,1的時候偶爾輸出結果,大於1,對於每個子模型都輸出。
- warm_start:熱啟動引數,bool型別。預設為False。如果為True,則下一次訓練是以追加樹的形式進行(重新使用上一次的呼叫作為初始化)。
- n_jobs:並行數。
先利用邏輯斯提回歸進行二元分類,以鳶尾花資料集為例:
from sklearn import datasets
'''
建立資料集
'''
iris = datasets.load_iris()
print(list(iris.keys()))
print(iris.target_names,iris.feature_names)結果:

可見我們有三種標記:setosa,versicolor,virginica.。每個樣本有四個特徵['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
我們以setosa和versicolor進行二分類。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
'''
建立資料集
'''
iris = datasets.load_iris()
#採用前兩個特徵
X = iris['data'][:,:2]
y = iris['target']
setosa = []
versicolor = []
for i in range(len(y)):
if y[i] == 0:
setosa.append(X[i])
elif y[i] == 1:
versicolor.append(X[i])
setosa = np.array(setosa)
versicolor = np.array(versicolor)
plt.figure()
plt.scatter(setosa[:,0],setosa[:,1],marker='^',label='setosa')
plt.scatter(versicolor[:,0],versicolor[:,1],label='versicolor')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc='best')
plt.show()結果:

'''
二分類
建立資料集
'''
iris = datasets.load_iris()
#採用前兩個特徵
x = iris['data'][:,:2]
y = iris['target']
X = []
Y = []
for i in range(len(y)):
if y[i] == 0 or y[i] == 1:
Y.append(y[i])
X.append(x[i])
#訓練
log_reg = LogisticRegression(solver='liblinear')
log_reg.fit(np.array(X),np.array(Y))
print(log_reg.predict([[4.5,3]]))結果:
![]()
sepal length=4.5,sepal width=3預測為setosa。
利用邏輯斯提回歸進行多元分類:
'''
建立資料集
'''
iris = datasets.load_iris()
x = iris['data']
y = iris['target']
#訓練
log_reg = LogisticRegression(solver='lbfgs',multi_class='multinomial')
log_reg.fit(x,y)
print(log_reg.predict([[4.5,3,4,3]]))結果:
![]()
小結
本節介紹了邏輯斯提回歸及其解法梯度下降演算法,還引申到多分類問題。下節我們介紹在非線性資料集上如何訓練。