
機器學習2 線性模型
引言
線性模型形式簡單、易於建模,就好像“hello world”。但許多功能強大的非線性模型都是線上性模型上的延伸。我們主要介紹幾種經典的線性模型:線性迴歸,多項式迴歸,嶺迴歸,lasso迴歸,邏輯斯提回歸。
線性迴歸
以西瓜問題為例,它有三個屬性(也就做特徵),{色澤,根蒂,敲聲},根據這些屬性判斷是不是好瓜,我們自然而然想到的是:是不是可以通過屬性的線性組合來預測。即:
寫成向量形式:
其中w叫做權重係數,b叫做偏置項。
那麼如何確定w,b呢。關鍵在於我們的預測值和實際值間的差距。在迴歸任務中,均方誤差是最常用的效能度量。
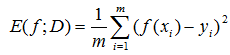
其中f為我們的預測函式,D為包含m個樣本的資料集。
你可能會想也可以這樣度量差距啊:
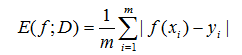
當然這樣也可以,這叫做曼哈頓距離,但函式性質不好,不連續,在後續處理會很麻煩。
我們的目標是求得使均方誤差最小化的w和b:
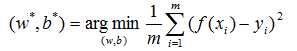
接下來就是數學推導了;
對於包含m個樣本的資料集D,每個樣本有d個屬性描述的一般情況。我們試圖學得的模型為:
![]()
我們把w,b兩個未知的引數寫在一起:
![]()
其中:
![]()
![]()
X為(m,d+1)維,W為(d+1,1)維
這樣我們的目標函式就是:

目標函式為連續的凸函式,令其偏導數為零,不就解出需要的引數了嗎?

解得:
![]()
可以看出一下子就解出我們需要的引數了,這是求解模型的方法之一:存在閉式解。另一種情況:很難求得閉式方程,需要使用迭代優化的方法,一步步走直到引數最優。這種方法,我們會在邏輯斯提回歸中介紹。
回來看,這有一個問題:XTX這個矩陣需要可逆,在練習情況下該矩陣通常是可逆的,因為樣本數遠遠大於屬性數。而在實際情況中該矩陣往往不可逆,屬性數遠遠大於樣本數,這樣該矩陣不可逆,存在多個解。這時需要引入正則化,如嶺迴歸,lasso迴歸。我會線上性迴歸之後進行介紹。
還有一個問題:線性迴歸往往出現欠擬合,在已知資料集上很難達到很好的效能,區域性加權迴歸可以緩解這種情況。
實戰演練
線性迴歸模型很簡單,可以自己試著去實現。這裡不再介紹,直接使用sklearn。
![]()
超引數:fit_intercept:是否需要偏置項b,預設true
normalize:是否需要歸一化。當 fit_intercept
sklearn.preprocessing.StandardScaler 並設定 normalize=False.
copy_X:是否需要複製X
n_jobs:cpu使用數,-1代表全部使用。

屬性:coef_:權重係數w
intercept_:偏置項b
程式碼走起:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
'''
建立資料集
'''
#rand(100,1)產生100*1的矩陣,數為0到1的隨機數
X = 2 * np.random.rand(100,1)
#randn(100,1)產生100*1的矩陣,數為正態分佈隨機數
y = 4 + 3*X + np.random.randn(100,1)
plt.figure()
plt.xlim(0,2)
plt.ylim(0,14)
plt.xlabel('x')
plt.ylabel('y')
plt.scatter(X,y)
plt.show()結果:

lin_reg = LinearRegression()
lin_reg.fit(X,y)
print(lin_reg.coef_,lin_reg.intercept_)結果:
![]()
在資料集上視覺化:
'''
視覺化
'''
plt.figure()
plt.xlim(0,2)
plt.ylim(0,14)
plt.xlabel('x')
plt.ylabel('y')
plt.plot([0,2],
[lin_reg.intercept_[0],2*lin_reg.coef_[0][0]+lin_reg.intercept_[0]],
c='black')
plt.scatter(X,y)
plt.title('LinearRegression')
plt.show()結果:

還不錯吧。
多項式迴歸
如果資料比簡單的直線複雜,我們也可以用線性模型來進行擬合。一個簡單的方法就是將每個特徵的冪次方新增為一個新的特徵,然後在這個拓展過的訓練集上訓練線性模型,這種方法稱為多項式迴歸。
'''
建立資料集
'''
np.random.seed(42)
#rand(100,1)產生100*1的矩陣,數為0到1的隨機數
X = 6 * np.random.rand(100,1) - 3
#randn(100,1)產生100*1的矩陣,數為正態分佈隨機數
y = 0.5 * X**2 + X + 2 + np.random.randn(100,1)
'''
視覺化
'''
plt.figure()
plt.xlim(-3,3)
plt.ylim(0,10)
plt.xlabel('x')
plt.ylabel('y')
plt.scatter(X,y)
plt.show()結果:

顯然,直線不可能很好的擬合它。
'''
訓練
'''
#利用PolynomialFeatures對資料進行轉換,將每個屬性的平方作為新特徵加入資料集
poly_features = PolynomialFeatures(degree=2,include_bias=False)
X_poly = poly_features.fit_transform(X)
lin_reg = LinearRegression()
lin_reg.fit(X_poly,y)
'''
視覺化
'''
plt.figure()
plt.xlim(-3,3)
plt.ylim(0,10)
plt.xlabel('x')
plt.ylabel('y')
x = np.arange(-3,3,0.1)
Y = lin_reg.coef_[0][1]*x**2 + lin_reg.coef_[0][0]*x + lin_reg.intercept_
plt.plot(x,Y,c='black')
plt.scatter(X,y)
plt.show()結果:

嶺迴歸
前面我們提到過,有時XTX矩陣不可逆時可以使用嶺迴歸。簡單來說,嶺迴歸就是在XTX上加上一個lamda*I使得矩陣非奇異。
矩陣I是m*m的單位矩陣(單位矩陣,值1貫穿對角線,其餘全是0,像不像一條‘嶺’)。這樣閉式解變成:
![]()
嶺迴歸最初就是為了解決矩陣奇異的情況,現在也用於在估計中加入偏差,引入懲罰項相當於l2範數,降低過擬合。
這裡引入了方差和偏差的概念:在機器學習領域,一個模型的泛化誤差可以表示成三種誤差的和
1)偏差 該誤差的原因在於模型欠擬合
2)方差 該誤差的原因在於使用的模型複雜,導致過擬合
3)不可避免的誤差:資料本身的噪聲
我們經常回去權衡偏差和方差,增加模型的複雜度就會提升方差,減小偏差。反過來,降低模型的複雜度就會降低方差,增大偏差。
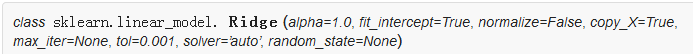
引數:
alpha:正則化強度; 必須是正浮點數。 較大的值指定較強的正則化。
copy_X:與線性迴歸相同
fit_intercept:與線性迴歸相同
max_iter:int,可選,共軛梯度求解器的最大迭代次數。 對於’sparse_cg’和’lsqr’求解器,預設值由scipy.sparse.linalg確定。 對於’sag’求解器,預設值為1000。
normalize:與線性迴歸相同
solver:{‘auto’,’svd’,’cholesky’,’lsqr’,’sparse_cg’,’sag’,‘saga’}
用於計算的求解方法:
‘auto’根據資料型別自動選擇求解器。
‘svd’使用X的奇異值分解來計算Ridge係數。對於奇異矩陣比’cholesky’更穩定。
‘cholesky’使用標準的scipy.linalg.solve函式來獲得閉合形式的解,即上述的閉式解的一種變體
‘sparse_cg’使用在scipy.sparse.linalg.cg中找到的共軛梯度求解器。作為迭代演算法,這個求解器比大規模資料的“cholesky”更合適。
‘lsqr’使用專用的正則化最小二乘常數scipy.sparse.linalg.lsqr。它是最快的,使用迭代過程。
‘sag’使用隨機平均梯度下降。‘saga’是它的改進。都使用迭代過程,並且當n_samples和n_feature都很大時,通常比其他求解器更快。注意,“sag”快速收斂僅在具有近似相同尺度的特徵上被保證。您可以使用sklearn.preprocessing的縮放器預處理資料。
所有最後五個求解器支援密集和稀疏資料。但是,當fit_intercept為True時,只有’sag’,‘saga’支援稀疏輸入。
新版本0.17支援:sag。
新版本0.19支援:saga。
tol:float解的精度。
random_state:隨機種子發生器。當為int時,生成固定資料,只適合‘sag’求解器
返回值
coef_:與線性迴歸相同
intercept_:與線性迴歸相同
n_iter_:每個目標的實際迭代次數。 僅適用於sag和lsqr求解器。 其他求解器將返回None。在版本0.17中出現。
'''
訓練
'''
#利用PolynomialFeatures對資料進行轉換,將每個屬性的平方作為新特徵加入資料集
poly_features = PolynomialFeatures(degree=2,include_bias=False)
X_poly = poly_features.fit_transform(X)
lin_reg = LinearRegression()
lin_reg.fit(X_poly,y)
#嶺迴歸
ridge_reg = Ridge(alpha=100,solver='cholesky')
ridge_reg.fit(X_poly,y)
'''
視覺化
'''
plt.figure()
plt.xlim(-3,3)
plt.ylim(0,10)
plt.xlabel('x')
plt.ylabel('y')
x = np.arange(-3,3,0.1)
Y1 = lin_reg.coef_[0][1]*x**2 + lin_reg.coef_[0][0]*x + lin_reg.intercept_
plt.plot(x,Y1,c='black',label='lin_reg')
Y2 = ridge_reg.coef_[0][1]*x**2 + ridge_reg.coef_[0][0]*x + ridge_reg.intercept_
plt.plot(x,Y2,c='red',label='ridge_reg')
plt.scatter(X,y)
plt.legend(loc='best')
plt.show()結果:

alpha越大,越接近線性模型。
lasso迴歸
與嶺迴歸一樣,它也能緩解過擬合,引入懲罰項,相當於L1範數。Lasso迴歸有一個重要的特點,它會傾向於完全消除掉那些最不重要的權重,我們因此能更好的瞭解到哪些特徵是無用的。

alpha:正則化程度,較大的值指定較強的正則化。
fit_intercept:與線性迴歸相同
normalize:與線性迴歸相同
precompute:是否使用預計算的 Gram 矩陣來加速計算。如果設定為 ‘auto’ 則機器決定。Gram 矩陣也可以 pass。對於 sparse input 這個選項永遠為 True。
max_iter:最大迴圈次數
tol:優化誤差率
warm_start:為 True 時, 重複使用上一次學習作為初始化,否則直接清除上次方案
positive:設為 True 時,強制使係數為正。
random_state:隨機種子生成器
selection:若設為 ‘random’, 每次迴圈會隨機更新引數,而按照預設設定則會依次更新。設為隨機通常會極大地加速交點(convergence)的產生,尤其是 tol 比 1e-4 大的情況下。
返回值
coef_:同線性迴歸
intercept_:同線性迴歸
n_iter_:達到誤差率的迴圈次數
sparse_coef_:擬合係數的稀疏表示
#Lasso迴歸
Lasso_reg = Lasso(alpha=2)
Lasso_reg.fit(X_poly,y)
'''
視覺化
'''
plt.figure()
plt.xlim(-3,3)
plt.ylim(0,10)
plt.xlabel('x')
plt.ylabel('y')
x = np.arange(-3,3,0.1)
Y1 = lin_reg.coef_[0][1]*x**2 + lin_reg.coef_[0][0]*x + lin_reg.intercept_
plt.plot(x,Y1,c='black',label='lin_reg')
Y2 = Lasso_reg.coef_[1]*x**2 + Lasso_reg.coef_[0]*x + Lasso_reg.intercept_
plt.plot(x,Y2,c='red',label='Lasso_reg')
plt.scatter(X,y)
plt.legend(loc='best')
plt.show()結果:

小結
本節主要介紹線性模型中的線性迴歸,並引出了多項式迴歸來解決非線性資料問題。還介紹了嶺迴歸和Lasso迴歸來解決過擬合問題。那如何利用線性模型進行分類學習呢?
下節我們將要介紹邏輯斯提回歸。雖說它有迴歸字樣,卻叛變為分類學習方法。