
機器學習之線性迴歸模型
當我們拿到樣本並經過特徵降維後得到 x1、x2 … 低維特徵,經過多項式對映得到線性迴歸的模型假設:
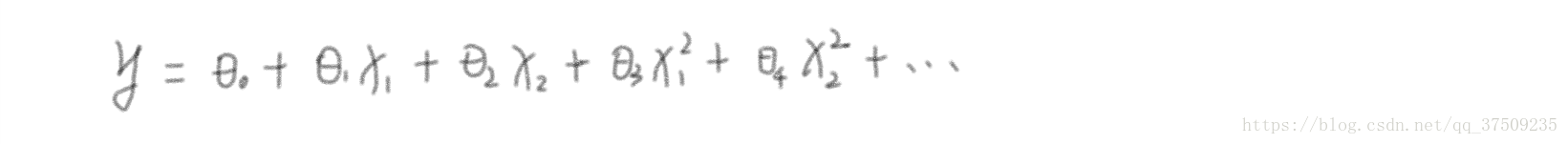
用 h(x) 來表示預測結果,上式用線性代數來表達:
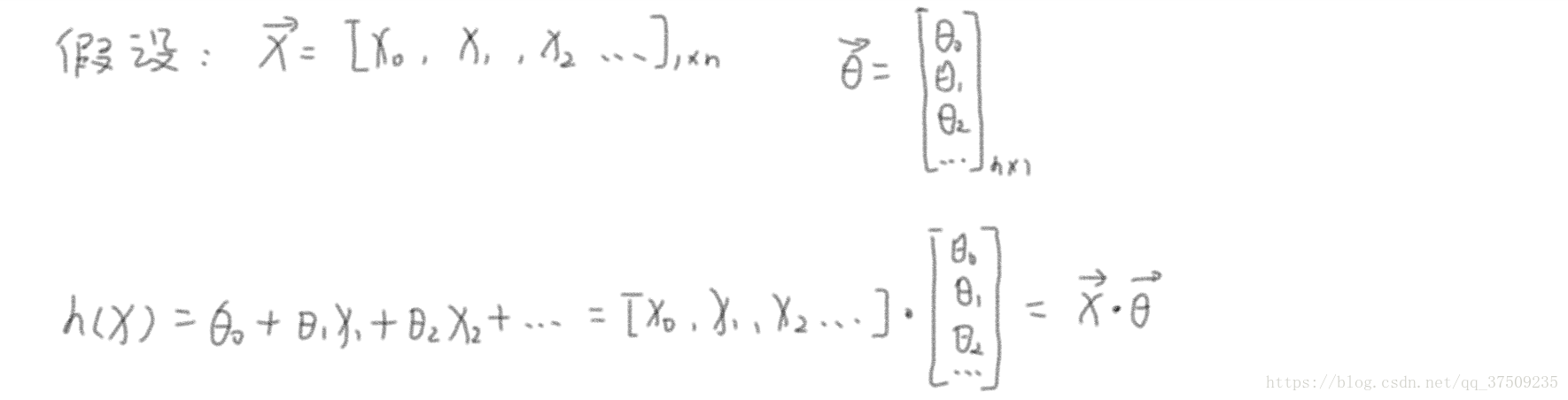
最小二乘法:
給定目標函式:

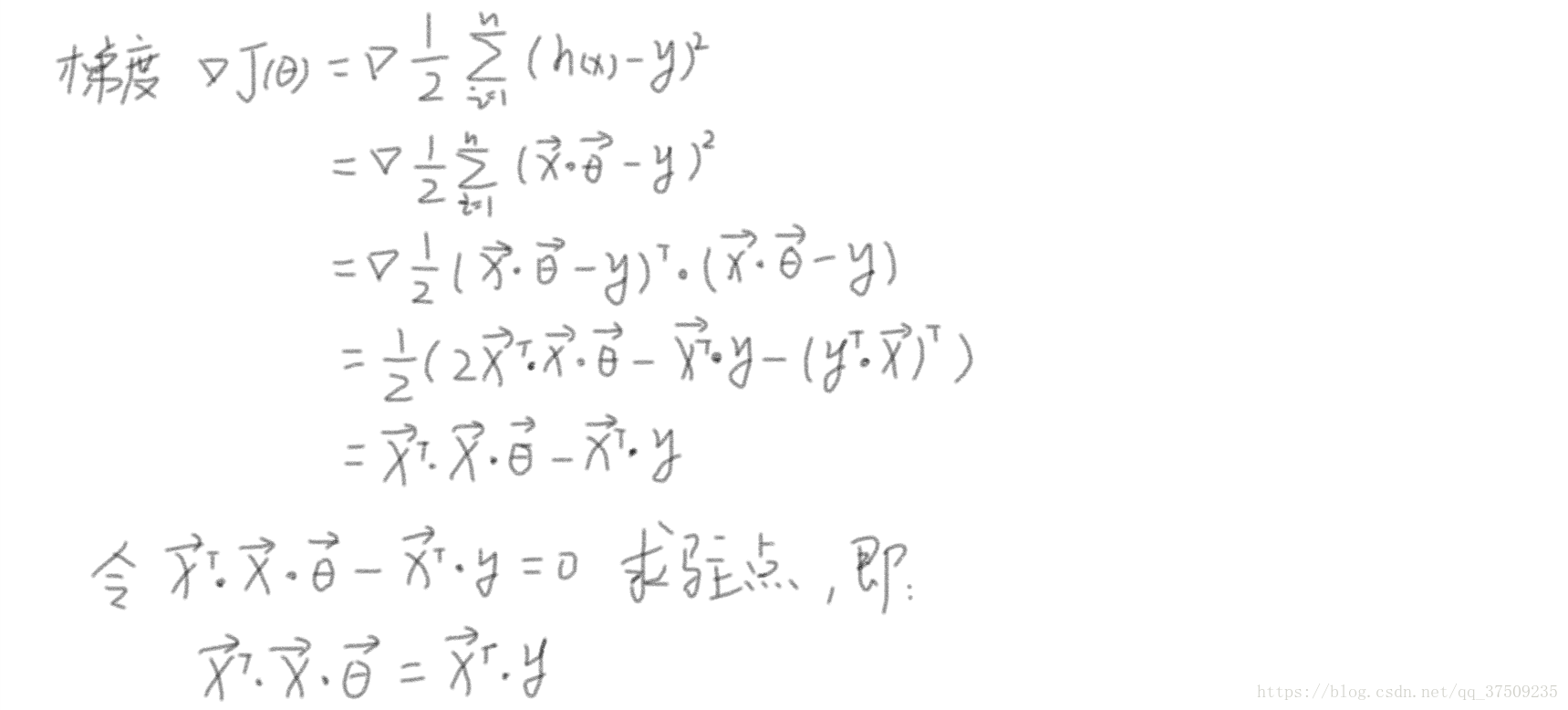 如果 XT•X•θ 可逆,則
如果 XT•X•θ 可逆,則
 如果 XT•X•θ 不可逆或防止過擬合,則加入 λ 擾動:
如果 XT•X•θ 不可逆或防止過擬合,則加入 λ 擾動:

優化與拓展:線性迴歸的複雜度懲罰因子
過擬合:如果有9個樣本點,那麼可以最高用8階的多項式來擬合,階數越高擬合度越高,但階數越高不一定越好,因為會出現震盪現象,當我們再用這個多項式來預測的話會因為震盪出現較大的偏差
防止過擬合:
一、Ridge 迴歸:將目標函式加入平方和損失
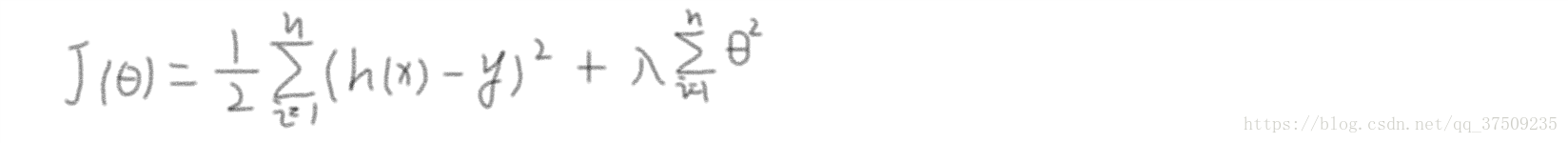
二、LASSO:正則項是一次冪
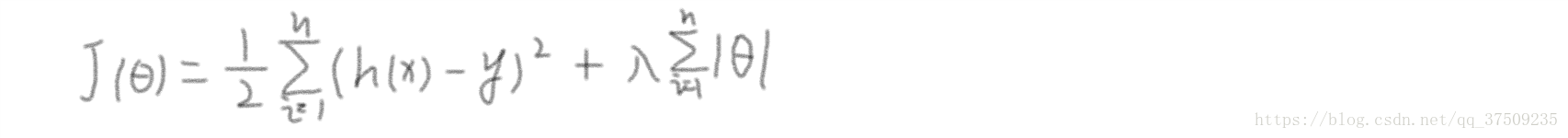
 式中 λ 是 θ 的引數,叫超引數,是沒辦法通過樣本求出來的,一般通過交叉驗證得到
給出 λ=0.01、λ=0.02 … 的候選,從訓練資料集中分出一部分作為驗證資料集,驗證每一個 λ 對應的 θ,用 θ 的均方誤差 MSE 確定候選中最優的 λ
式中 λ 是 θ 的引數,叫超引數,是沒辦法通過樣本求出來的,一般通過交叉驗證得到
給出 λ=0.01、λ=0.02 … 的候選,從訓練資料集中分出一部分作為驗證資料集,驗證每一個 λ 對應的 θ,用 θ 的均方誤差 MSE 確定候選中最優的 λ
交叉驗證(n折):
把驗證資料集分成 n 份
前 n-1 份來作為訓練資料,把第 n 份作為驗證資料集
再把前 n-2 份、第 n 份作為訓練資料集,把第 n-1 份作為驗證集
再把前 n-3 份、n-2~n-1 份作為資料集,把第 n-2 份作為驗證集
再把 …

梯度下降演算法
對於線性迴歸模型假設
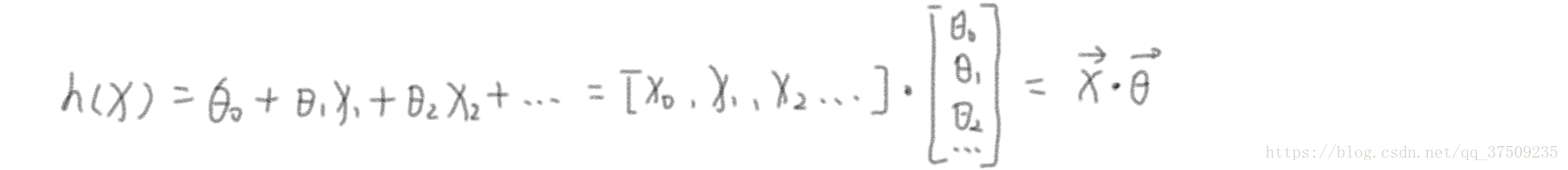
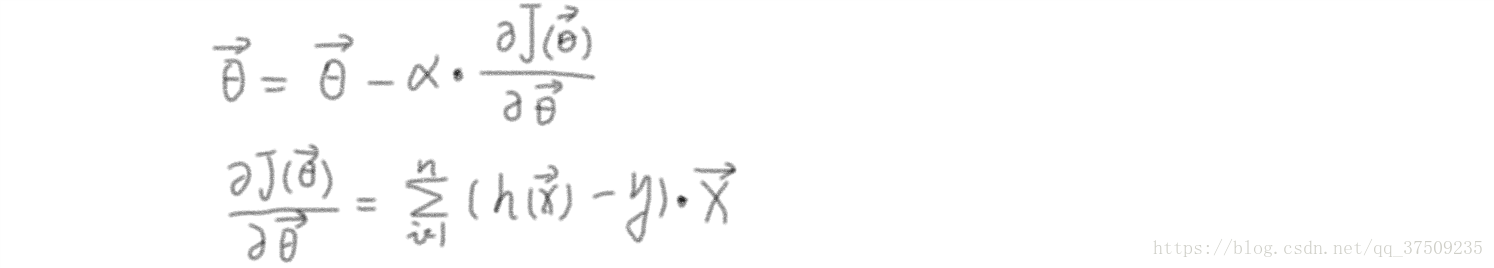 α:學習率、步長
(用回溯線性搜尋尋找最優的學習率是最正的方法;第二種辦法(在實踐中常用)是隨機給一個初始學習率,接下來不斷修正,這是比較簡單高效的方法;第三種是給一個固定的學習率,一般情況下可用)
α:學習率、步長
(用回溯線性搜尋尋找最優的學習率是最正的方法;第二種辦法(在實踐中常用)是隨機給一個初始學習率,接下來不斷修正,這是比較簡單高效的方法;第三種是給一個固定的學習率,一般情況下可用)
優化與拓展:
一、批量梯度下降演算法(需要拿到所有樣本):
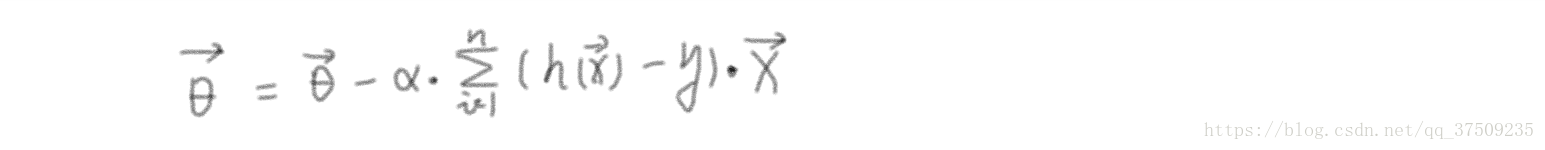
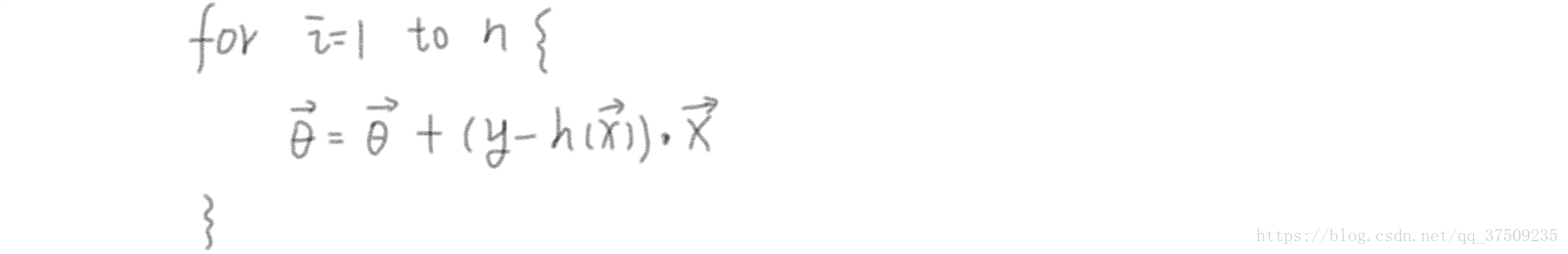
判定係數(模型好壞的指標):
對於 m 個樣本:(x1, y1), (x2, y2) … 某模型的預測值:(x1, y1^), (x2, y2^) … 樣本的平方和:TSS = Σ(y-y~)^2 殘差平方和:RSS = Σ(y-y)2 定義 R^2 = 1-RSS/TSS R^2 越大,效果越好 迴歸平方和:ESS = Σ(y-y~)2