
在深度學習中Softmax交叉熵損失函式的公式求導
阿新 • • 發佈:2019-01-03
(以下部分基本介紹轉載於點選開啟連結)
在深度學習NN中的output層通常是一個分類輸出,對於多分類問題我們可以採用k-二元分類器來實現,這裡我們介紹softmax。softmax迴歸中,我們解決的是多分類問題(相對於 logistic 迴歸解決的二分類問題),類標  可以取
可以取  個不同的值(而不是
2 個)。因此,對於訓練集
個不同的值(而不是
2 個)。因此,對於訓練集 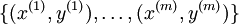 ,我們有
,我們有 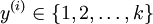 。(注意此處的類別下標從
1 開始,而不是 0)。例如,在 MNIST 數字識別任務中,我們有
。(注意此處的類別下標從
1 開始,而不是 0)。例如,在 MNIST 數字識別任務中,我們有 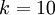 個不同的類別。
個不同的類別。
對於給定的測試輸入  ,我們想用假設函式針對每一個類別j估算出概率值
,我們想用假設函式針對每一個類別j估算出概率值 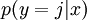 。也就是說,我們想估計 的每一種分類結果出現的概率。因此,我們的假設函式將要輸出一個
。也就是說,我們想估計 的每一種分類結果出現的概率。因此,我們的假設函式將要輸出一個
個估計的概率值。
具體地說,我們的假設函式 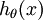 形式如下:
形式如下:
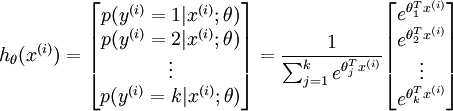
注:這裡我們用類似機器學習裡面(θ^T)x 來代替(w^T)x+b
其中 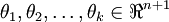 是模型的引數。請注意
是模型的引數。請注意 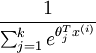 這一項對概率分佈進行歸一化,使得所有概率之和為
1 。
這一項對概率分佈進行歸一化,使得所有概率之和為
1 。
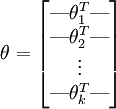
為了方便起見,我們同樣使用符號  來表示全部的模型引數。在實現Softmax迴歸時,將 用一個
來表示全部的模型引數。在實現Softmax迴歸時,將 用一個 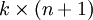 的矩陣來表示會很方便,該矩陣是將
的矩陣來表示會很方便,該矩陣是將 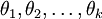 按行羅列起來得到的,如下所示:
按行羅列起來得到的,如下所示:
現在我們來介紹 softmax 迴歸演算法的代價函式。在下面的公式中,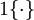 是示性函式,其取值規則為:
是示性函式,其取值規則為:
值為真的表示式
, 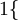 值為假的表示式
值為假的表示式 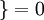 。舉例來說,表示式
。舉例來說,表示式 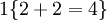
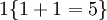 的值為 0。我們的代價函式為:
的值為 0。我們的代價函式為:
-
![\begin{align}J(\theta) = - \frac{1}{m} \left[ \sum_{i=1}^{m} \sum_{j=1}^{k} 1\left\{y^{(i)} = j\right\} \log \frac{e^{\theta_j^T x^{(i)}}}{\sum_{l=1}^k e^{ \theta_l^T x^{(i)} }}\right]\end{align}](http://ufldl.stanford.edu/wiki/images/math/7/6/3/7634eb3b08dc003aa4591a95824d4fbd.png) 在Softmax迴歸中將 分類為類別
在Softmax迴歸中將 分類為類別  的概率為:
的概率為: -
-
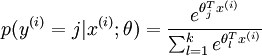 .
.
下面我們來看看求導的問題
softmax的函式公式如下:
其中,
表示第L層(通常是最後一層)第j個神經元的輸入,
表示第L層第j個神經元的輸出,
表示自然常數。注意看,
表示了第L層所有神經元的輸入之和。
先給出aj對zi的偏導在後面要 用到
-
- 在J代價函式中取出對單一資料對(x(i), y(i))的
- 下面我們以L對Wj的偏導舉例:
注:左圖的Wj,bj,aj,zj,均是第L層的.Wj指的是W矩陣中的第j行
- 同理解得:
- 將loss擴充到整個資料集
- 則有:(ps:以下的k是指最後一層及L層的unit數,n是L-1層的unit數,m是資料集大小)
- db[L]的python寫法:np.sum(A-Y, axis=1, keepdims=True)
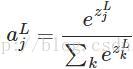
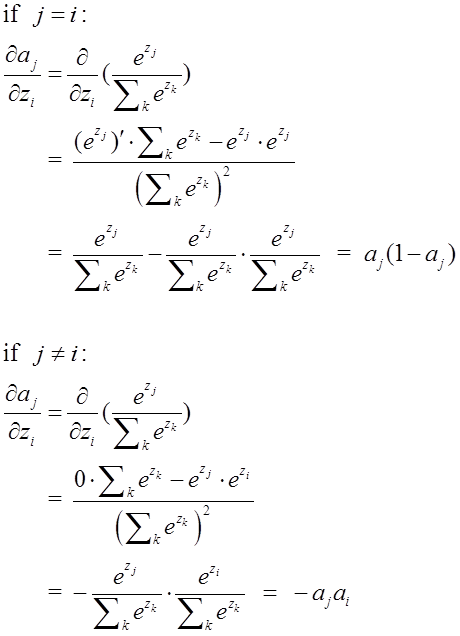
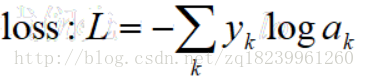

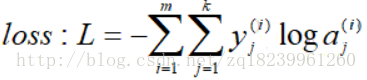
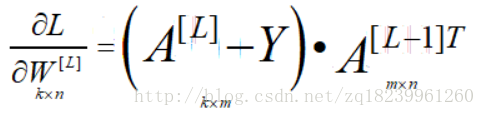
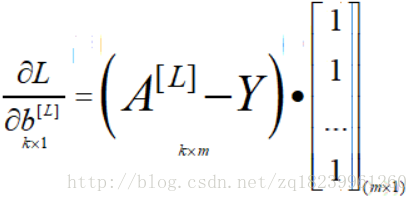
J = np.sum(Y * np.log(A + 1e-8)) * (-1 / m)參考網址: softmax迴歸: http://ufldl.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92