
秒懂詞向量Word2vec的本質
轉自我的公眾號: 『資料探勘機養成記』
1. 引子
大家好
我叫資料探勘機
皇家布魯斯特大學肄業
我喝最烈的果粒橙,鑽最深的牛角尖
——執著如我
今天我要揭開Word2vec的神祕面紗
直窺其本質
相信我,這絕對是你看到的
最淺白易懂的 Word2vec 中文總結
(蛤?你問我為啥有這個底氣?
且看下面,我的踩坑血淚史。。。)
2. Word2vec參考資料總結
(以下都是我踩過的坑,建議先跳過本節,閱讀正文部分,讀完全文回頭再來看)
先大概說下我深挖 word2vec 的過程:先是按照慣例,看了 Mikolov 關於 Word2vec 的兩篇原始論文,然而發現看完依然是一頭霧水,似懂非懂,主要原因是這兩篇文章省略了太多理論背景和推導細節;然後翻出 Bengio 03年那篇JMLR和 Ronan 11年那篇JMLR,看完對語言模型、用CNN處理NLP任務有所瞭解,但依然無法完全吃透 word2vec;這時候我開始大量閱讀中英文部落格,其中 北漂浪子 的一篇閱讀量很多的部落格吸引了我的注意,裡面非常系統地講解了 Word2vec 的前因後果,最難得的是深入剖析了程式碼的實現細節,看完之後細節方面瞭解了很多,不過還是覺得有些迷霧;終於,我在 quora 上看到有人推薦 Xin Rong 的那篇英文paper,看完之後只覺醍醐灌頂,酣暢淋漓,相見恨晚,成為我首推的 Word2vec 參考資料。下面我將詳細列出我閱讀過的所有 Word2vec 相關的參考資料,並給出評價
- Mikolov 兩篇原論文:
- 『Distributed Representations of Sentences and Documents』
- 在前人基礎上提出更精簡的語言模型(language model)框架並用於生成詞向量,這個框架就是 Word2vec
- 『Efficient estimation of word representations in vector space』
- 專門講訓練 Word2vec 中的兩個trick:hierarchical softmax 和 negative sampling
- 優點:Word2vec 開山之作,兩篇論文均值得一讀
- 缺點:只見樹木,不見森林和樹葉,讀完不得要義。這裡『森林』指 word2vec 模型的理論基礎——即 以神經網路形式表示的語言模型,『樹葉』指具體的神經網路形式、理論推導、hierarchical softmax 的實現細節等等
- 『Distributed Representations of Sentences and Documents』
- 北漂浪子的部落格:『深度學習word2vec 筆記之基礎篇』
- 優點:非常系統,結合原始碼剖析,語言平實易懂
- 缺點:太囉嗦,有點抓不住精髓
- Yoav Goldberg 的論文:『word2vec Explained- Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method』
- 優點:對 negative-sampling 的公式推導非常完備
- 缺點:不夠全面,而且都是公式,沒有圖示,略顯乾枯
- Xin Rong 的論文:『word2vec Parameter Learning Explained』:
- !重點推薦!
- 理論完備由淺入深非常好懂,且直擊要害,既有 high-level 的 intuition 的解釋,也有細節的推導過程
- 一定要看這篇paper!一定要看這篇paper!一定要看這篇paper!
- 來斯惟的博士論文『基於神經網路的詞和文件語義向量表示方法研究』以及他的部落格(網名:licstar)
- 可以作為更深入全面的擴充套件閱讀,這裡不僅僅有 word2vec,而是把詞嵌入的所有主流方法通通梳理了一遍
- 幾位大牛在知乎的回答:『word2vec 相比之前的 Word Embedding 方法好在什麼地方?』
- 劉知遠、邱錫鵬、李韶華等知名學者從不同角度發表對 Word2vec 的看法,非常值得一看
- Sebastian 的部落格:『On word embeddings - Part 2: Approximating the Softmax』
- 詳細講解了 softmax 的近似方法,Word2vec 的 hierarchical softmax 只是其中一種
3. 正文
你會在本文看到:
- 提綱挈領地講解 word2vec 的理論精髓
- 學會用gensim訓練詞向量,並尋找相似詞
你不會在本文看到
- 神經網路訓練過程的推導
- hierarchical softmax/negative sampling 等 trick 的理論和實現細節
3.1. 什麼是 Word2vec?
在聊 Word2vec 之前,先聊聊 NLP (自然語言處理)。NLP 裡面,最細粒度的是 詞語,詞語組成句子,句子再組成段落、篇章、文件。所以處理 NLP 的問題,首先就要拿詞語開刀。
舉個簡單例子,判斷一個詞的詞性,是動詞還是名詞。用機器學習的思路,我們有一系列樣本(x,y),這裡 x 是詞語,y 是它們的詞性,我們要構建 f(x)->y 的對映,但這裡的數學模型 f(比如神經網路、SVM)只接受數值型輸入,而 NLP 裡的詞語,是人類的抽象總結,是符號形式的(比如中文、英文、拉丁文等等),所以需要把他們轉換成數值形式,或者說——嵌入到一個數學空間裡,這種嵌入方式,就叫詞嵌入(word embedding),而 Word2vec,就是詞嵌入( word embedding) 的一種
我在前作『都是套路: 從上帝視角看透時間序列和資料探勘』提到,大部分的有監督機器學習模型,都可以歸結為:
f(x)->y
在 NLP 中,把 x 看做一個句子裡的一個詞語,y 是這個詞語的上下文詞語,那麼這裡的 f,便是 NLP 中經常出現的『語言模型』(language model),這個模型的目的,就是判斷 (x,y) 這個樣本,是否符合自然語言的法則,更通俗點說就是:詞語x和詞語y放在一起,是不是人話。
Word2vec 正是來源於這個思想,但它的最終目的,不是要把 f 訓練得多麼完美,而是隻關心模型訓練完後的副產物——模型引數(這裡特指神經網路的權重),並將這些引數,作為輸入 x 的某種向量化的表示,這個向量便叫做——詞向量(這裡看不懂沒關係,下一節我們詳細剖析)。
我們來看個例子,如何用 Word2vec 尋找相似詞:
- 對於一句話:『她們 誇 吳彥祖 帥 到 沒朋友』,如果輸入 x 是『吳彥祖』,那麼 y 可以是『她們』、『誇』、『帥』、『沒朋友』這些詞
- 現有另一句話:『她們 誇 我 帥 到 沒朋友』,如果輸入 x 是『我』,那麼不難發現,這裡的上下文 y 跟上面一句話一樣
- 從而 f(吳彥祖) = f(我) = y,所以大資料告訴我們:我 = 吳彥祖(完美的結論)
3.2. Skip-gram 和 CBOW 模型
上面我們提到了語言模型
- 如果是用一個詞語作為輸入,來預測它周圍的上下文,那這個模型叫做『Skip-gram 模型』
- 而如果是拿一個詞語的上下文作為輸入,來預測這個詞語本身,則是 『CBOW 模型』
3.2.1 Skip-gram 和 CBOW 的簡單情形
我們先來看個最簡單的例子。上面說到, y 是 x 的上下文,所以 y 只取上下文裡一個詞語的時候,語言模型就變成:
用當前詞 x 預測它的下一個詞 y
但如上面所說,一般的數學模型只接受數值型輸入,這裡的 x 該怎麼表示呢? 顯然不能用 Word2vec,因為這是我們訓練完模型的產物,現在我們想要的是 x 的一個原始輸入形式。
答案是:one-hot encoder
所謂 one-hot encoder,其思想跟特徵工程裡處理類別變數的 one-hot 一樣(參考我的前作『資料探勘比賽通用框架』、『深挖One-hot和Dummy背後的玄機』)。本質上是用一個只含一個 1、其他都是 0 的向量來唯一表示詞語。
我舉個例子,假設全世界所有的詞語總共有 V 個,這 V 個詞語有自己的先後順序,假設『吳彥祖』這個詞是第1個詞,『我』這個單詞是第2個詞,那麼『吳彥祖』就可以表示為一個 V 維全零向量、把第1個位置的0變成1,而『我』同樣表示為 V 維全零向量、把第2個位置的0變成1。這樣,每個詞語都可以找到屬於自己的唯一表示。
OK,那我們接下來就可以看看 Skip-gram 的網路結構了,x 就是上面提到的 one-hot encoder 形式的輸入,y 是在這 V 個詞上輸出的概率,我們希望跟真實的 y 的 one-hot encoder 一樣。
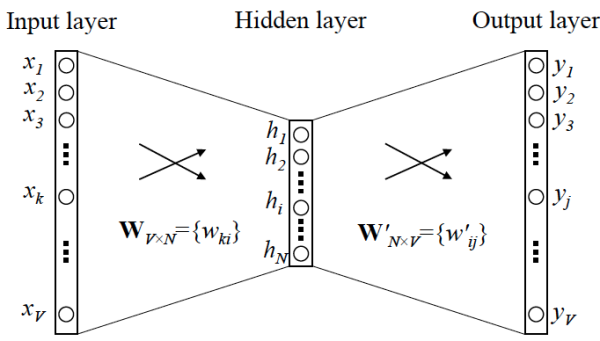
首先說明一點:隱層的啟用函式其實是線性的,相當於沒做任何處理(這也是 Word2vec 簡化之前語言模型的獨到之處),我們要訓練這個神經網路,用反向傳播演算法,本質上是鏈式求導,在此不展開說明了,
當模型訓練完後,最後得到的其實是神經網路的權重,比如現在輸入一個 x 的 one-hot encoder: [1,0,0,…,0],對應剛說的那個詞語『吳彥祖』,則在輸入層到隱含層的權重裡,只有對應 1 這個位置的權重被啟用,這些權重的個數,跟隱含層節點數是一致的,從而這些權重組成一個向量 vx 來表示x,而因為每個詞語的 one-hot encoder 裡面 1 的位置是不同的,所以,這個向量 vx 就可以用來唯一表示 x。
注意:上面這段話說的就是 Word2vec 的精髓!!
此外,我們剛說了,輸出 y 也是用 V 個節點表示的,對應V個詞語,所以其實,我們把輸出節點置成 [1,0,0,…,0],它也能表示『吳彥祖』這個單詞,但是啟用的是隱含層到輸出層的權重,這些權重的個數,跟隱含層一樣,也可以組成一個向量 vy,跟上面提到的 vx 維度一樣,並且可以看做是詞語『吳彥祖』的另一種詞向量。而這兩種詞向量 vx 和 vy,正是 Mikolov 在論文裡所提到的,『輸入向量』和『輸出向量』,一般我們用『輸入向量』。
需要提到一點的是,這個詞向量的維度(與隱含層節點數一致)一般情況下要遠遠小於詞語總數 V 的大小,所以 Word2vec 本質上是一種降維操作——把詞語從 one-hot encoder 形式的表示降維到 Word2vec 形式的表示。
3.2.2. Skip-gram 更一般的情形
上面討論的是最簡單情形,即 y 只有一個詞,當 y 有多個詞時,網路結構如下:
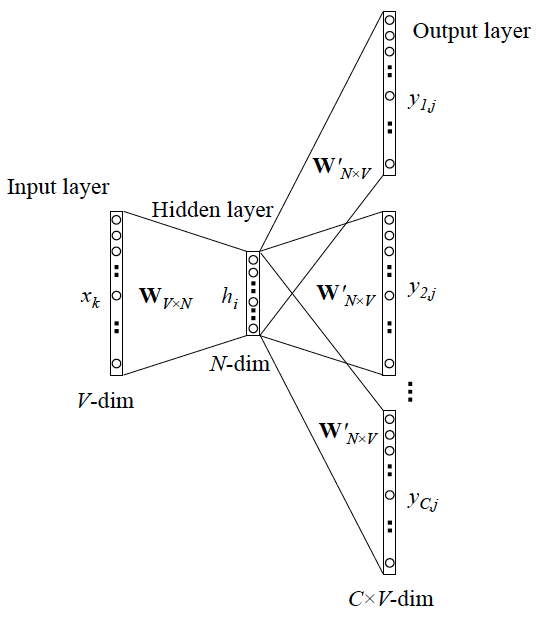
可以看成是 單個x->單個y 模型的並聯,cost function 是單個 cost function 的累加(取log之後)
如果你想深入探究這些模型是如何並聯、 cost function 的形式怎樣,不妨仔細閱讀參考資料4. 在此我們不展開。
3.2.3 CBOW 更一般的情形
跟 Skip-gram 相似,只不過:
Skip-gram 是預測一個詞的上下文,而 CBOW 是用上下文預測這個詞
網路結構如下
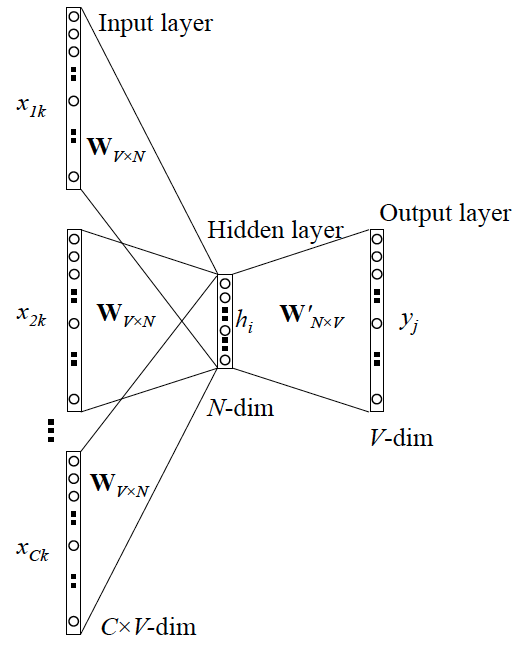
更 Skip-gram 的模型並聯不同,這裡是輸入變成了多個單詞,所以要對輸入處理下(一般是求和然後平均),輸出的 cost function 不變,在此依然不展開,建議你閱讀參考資料4.
3.3. Word2vec 的訓練trick
相信很多初次踩坑的同學,會跟我一樣陷入 Mikolov 那篇論文(參考資料1.)裡提到的 hierarchical softmax 和 negative sampling 裡不能自拔,但其實,它們並不是 Word2vec 的精髓,只是它的訓練技巧,但也不是它獨有的訓練技巧。 Hierarchical softmax 只是 softmax 的一種近似形式(詳見參考資料7.),而 negative sampling 也是從其他方法借鑑而來。
為什麼要用訓練技巧呢? 如我們剛提到的,Word2vec 本質上是一個語言模型,它的輸出節點數是 V 個,對應了 V 個詞語,本質上是一個多分類問題,但實際當中,詞語的個數非常非常多,會給計算造成很大困難,所以需要用技巧來加速訓練。
這裡我總結了一下這兩個 trick 的本質,有助於大家更好地理解,在此也不做過多展開,有興趣的同學可以深入閱讀參考資料1.~7.
- hierarchical softmax
- 本質是把 N 分類問題變成 log(N)次二分類
- negative sampling
- 本質是預測總體類別的一個子集
3.4. 擴充套件
很多時候,當我們面對林林總總的模型、方法時,我們總希望總結出一些本質的、共性的東西,以構建我們的知識體系,比如我在前作『分類和迴歸的本質』裡,原創性地梳理了分類模型和迴歸模型的本質聯絡,比如在詞嵌入領域,除了 Word2vec之外,還有基於共現矩陣分解的 GloVe 等等詞嵌入方法。
深入進去我們會發現,神經網路形式表示的模型(如 Word2vec),跟共現矩陣分解模型(如 GloVe),有理論上的相通性,這裡我推薦大家閱讀參考資料5. ——來斯惟博士在它的博士論文附錄部分,證明了 Skip-gram 模型和 GloVe 的 cost fucntion 本質上是一樣的。是不是一個很有意思的結論? 所以在實際應用當中,這兩者的差別並不算很大,尤其在很多 high-level 的 NLP 任務(如句子表示、命名體識別、文件表示)當中,經常把詞向量作為原始輸入,而到了 high-level 層面,差別就更小了。
鑑於詞語是 NLP 裡最細粒度的表達,所以詞向量的應用很廣泛,既可以執行詞語層面的任務,也可以作為很多模型的輸入,執行 high-level 如句子、文件層面的任務,包括但不限於:
- 計算相似度
- 尋找相似詞
- 資訊檢索
- 作為 SVM/LSTM 等模型的輸入
- 中文分詞
- 命名體識別
- 句子表示
- 情感分析
- 文件表示
- 文件主題判別
4. 實戰
上面講了這麼多理論細節,其實在真正應用的時候,只需要呼叫 Gensim (一個 Python 第三方庫)的介面就可以。但對理論的探究仍然有必要,你能更好地知道引數的意義、模型結果受哪些因素影響,以及舉一反三地應用到其他問題當中,甚至更改原始碼以實現自己定製化的需求。
這裡我們將使用 Gensim 和 NLTK 這兩個庫,來完成對生物領域的相似詞挖掘,將涉及:
- 解讀 Gensim 裡 Word2vec 模型的引數含義
- 基於相應語料訓練 Word2vec 模型,並評估結果
- 對模型結果調優
語料我已經放出來了,可以關注我的公眾號『資料探勘機養成記』,並回復 Sherlocked 獲取語料,包含5000行生物醫學領域相關文獻的摘要(英文)
我將在下一篇文章裡詳細講解實戰步驟,敬請關注本人公眾號。友情建議:請先自行安裝 Gensim 和 NLTK 兩個庫,並建議使用 jupyter notebook 作為程式碼執行環境
歡迎各路大神猛烈拍磚,共同交流
====評論區答疑節選====
Q1. gensim 和 google的 word2vec 裡面並沒有用到onehot encoder,而是初始化的時候直接為每個詞隨機生成一個N維的向量,並且把這個N維向量作為模型引數學習;所以word2vec結構中不存在文章圖中顯示的將V維對映到N維的隱藏層。
A1. 其實,本質是一樣的,加上 one-hot encoder 層,是為了方便理解,因為這裡的 N 維隨機向量,就可以理解為是 V 維 one-hot encoder 輸入層到 N 維隱層的權重,或者說隱層的輸出(因為隱層是線性的)。每個 one-hot encoder 裡值是 1 的那個位置,對應的 V 個權重被啟用,其實就是『從一個V*N的隨機詞向量矩陣裡,抽取某一行』。學習 N 維向量的過程,也就是優化 one-hot encoder 層到隱含層權重的過程
Q2. hierarchical softmax 獲取詞向量的方式和原先的其實基本完全不一樣,我初始化輸入的也不是一個onehot,同時我是直接通過優化輸入向量的形式來獲取詞向量?如果用了hierarchical 結構我應該就沒有輸出向量了吧?
A2. 初始化輸入依然可以理解為是 one-hot,同上面的回答;確實是只能優化輸入向量,沒有輸出向量了。具體原因,我們可以梳理一下不用 hierarchical (即原始的 softmax) 的情形:
隱含層輸出一個 N 維向量 x, 每個x 被一個 N 維權重 w 連線到輸出節點上,有 V 個這樣的輸出節點,就有 V 個權重 w,再套用 softmax 的公式,變成 V 分類問題。這裡的類別就是詞表裡的 V 個詞,所以一個詞就對應了一個權重 w,從而可以用 w 作為該詞的詞向量,即文中的輸出詞向量。
PS. 這裡的 softmax 其實多了一個『自由度』,因為 V 分類只需要 V-1 個權重即可
我們再看看 hierarchical softmax 的情形:
隱含層輸出一個 N 維向量 x, 但這裡要預測的目標輸出詞,不再是用 one-hot 形式表示,而是用 huffman tree 的編碼,所以跟上面 V 個權重同時存在的原始 softmax 不一樣, 這裡 x 可以理解為先接一個輸出節點,即只有一個權重 w1 ,輸出節點輸出 1/1+exp(-w*x),變成一個二分類的 LR,輸出一個概率值 P1,然後根據目標詞的 huffman tree 編碼,將 x 再輸出到下一個 LR,對應權重 w2,輸出 P2,總共遇到的 LR 個數(或者說權重個數)跟 huffman tree 編碼長度一致,大概有 log(V) 個,最後將這 log(V) 個 P 相乘,得到屬於目標詞的概率。但注意因為只有 log(V) 個權重 w 了,所以跟 V 個詞並不是一一對應關係,就不能用 w 表徵某個詞,從而失去了詞向量的意義
PS. 但我個人理解,這 log(V) 個權重的組合,可以表示某一個詞。因為 huffman tree 構建的時候,可以理解成是一個不斷『二分』的過程,不斷二分到只剩一個詞為止。而每一次二分,都有一個 LR 權重,這個權重可以表徵該類詞,所以這些權重拼接在一起,就表示了『二分』這個過程,以及最後分到的這個詞的『輸出詞向量』。
我舉個例子:
假設現在總共有 (A,B,C)三個詞,huffman tree 這麼構建:
第一次二分: (A,B), (C)
假如我們用的 LR 是二分類 softmax 的情形(比常見 LR 多了一個自由度),這樣 LR 就有倆權重,權重 w1_1 是屬於 (A,B) 這一類的,w1_2 是屬於 (C) 的, 而 C 已經到最後一個了,所以 C 可以表示為 w1_2
第二次二分: (A), (B)
假設權重分別對應 w2_1 和 w2_2,那麼 A 就可以表示為 [w1_1, w2_1], B 可以表示為 [w1_1, w2_2]
這樣, A,B,C 每個詞都有了一個唯一表示的詞向量(此時他們長度不一樣,不過可以用 padding 的思路,即在最後補0)
當然了,一般沒人這麼幹。。。開個腦洞而已
Q3. 待續