
視訊理解論文雜讀(門外漢級)
從圖片到視訊肯定是科研發展的方向,可惜需要的資源太多,像我這種只有一個GPU的根本做不了,不過學習學習總是好的。
未完成,主要自己看,主要是動作識別方向
[2018-arxiv] Temporal Shift Module for Efficient Video Understanding [paper]
韓老師怎麼進軍視訊領域了? 這篇文章簡單有趣,不過有個小疑問為啥不以channel為單位交換呢,隔行如隔山,細節還是非常重要

[2018-ECCV] ECO: Efficient Convolutional Network for Online Video Understanding
這麼直觀的想法為什麼到18年才被人發現,可能我錯過了一些細節。不過這裡N也是固定的,固定的N感覺還是有些遺憾的

[2018-CVPR] Non-local Neural Networks [paper][code]
其實我對該論文的做法是抱保留態度的,雖然他的出發點我是十分贊同的。該工作主要是想利用空間和時間上全域性的資訊來輔助視訊或圖片上的理解任務,這個是很合理的出發點,所以像作者提到之前的global mean什麼的方法(雖然我沒看),或者是分割裡面比較新的論文Context Encoding for Semantic Segmentation加個全域性分類損失,我都非常理解。但是作者採用是這麼一個策略,以圖片為例,如果是傳統的方法,對於一個特徵圖,每個畫素點的值都是卷積堆疊的結果,獲取的資訊跟感受野有關,因此稱之為local也是合理的。作者想為每個點增加全域性資訊,採用的其實就是一個有權重的累加,計算的公式跟全域性的卷積有點小類似,如下面的公式,x是特徵圖,i,j等就是座標,f是相似性的函式,g是一個轉化,比如1*1的卷積,學術上稱之為embedding,
權重是兩個特徵值的相似性。兩個點的特徵越相似,那麼權重越大,如下面的公式。但是這樣就完全拋棄空間或時間的關係,這是很不合理的,如果兩個畫素點的特徵相似但是隔的很遠,他們的關係會有那麼強麼?
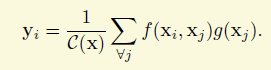
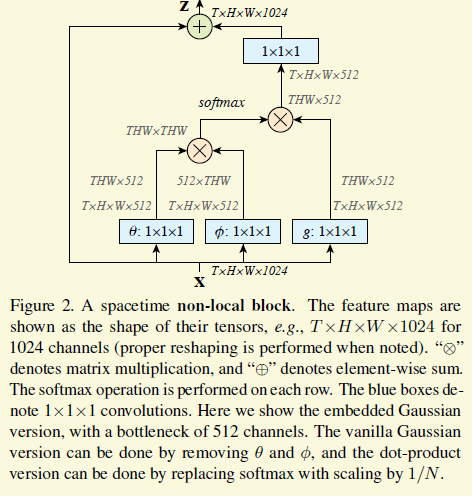
接下來作者就把這個公式完美地用一個新的cnn building block實現了出來。首先需要定義上面的g和h. g論文裡就用1*1的卷積了,f是一個embeded guassian,如下圖,不難理解

最後就成了這樣,θ和φ就是f裡面的embedding,特徵用512維表示,減少計算,下圖最左邊的矩陣乘法就是上面公式3的右上部分,softmax把公式3的指數跟歸一化包辦了,還是比較優美的。
[2017-ICCV]
Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks [paper][code]
P3D
[2017-CVPR ] Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
I3D
[2014-NIPS]Two-Stream Convolutional Networks for Action Recognition in Videos[paper]